Benchmarking Java Streams
Take a deep dive into the performance characteristics of Java streams. With the help of JMH, learn how Java streams behave when put under pressure.
Join the DZone community and get the full member experience.
Join For FreeIn my previous article, I took a closer look at the Java ExecutorService interface and its implementations, with some focus on the Fork/Join framework and ThreadPerTaskExecutor. Today, I would like to take a step forward and check how well they behave when put under pressure. In short, I am going to make benchmarks, a lot of benchmarks.
All the code from below, and more, will be available in a dedicated GitHub repository.
Logic Under Benchmark
I would like to start this text with a walk through the logic that will be the base for benchmarks as it is split into two basic categories:
- Based on the classic stream
- Based on the Fork/Join approach
Classic Stream Logic
public static Map<Ip, Integer> groupByIncomingIp(Stream<String> requests,
LocalDateTime upperTimeBound, LocalDateTime lowerTimeBound) {
return requests
.map(line -> line.split(","))
.filter(words -> words.length == 3)
.map(words -> new Request(words[1], LocalDateTime.parse(words[2])))
.filter(request -> request.timestamp().isBefore(upperTimeBound) &&
request.timestamp().isAfter(lowerTimeBound))
.map(i -> new Ip(i.ip()))
.collect(groupingBy(i -> i, summingInt(i -> 1)));
}In theory, the purpose of this piece of code is to transform a list of strings, then do some filtering and grouping around and return the map. Supplied strings are in the following format:
1,192.168.1.1,2023-10-29T17:33:33.647641574
It represents the event of reading an IP address trying to access a particular server. The output maps an IP address to the number of access attempts in a particular period, expressed by lower and upper time boundaries.
Fork/Join Logic
@Override
public Map<Ip, Integer> compute() {
if (data.size() >= THRESHOLD) {
Map<Ip, Integer> output = new HashMap<>();
ForkJoinTask
.invokeAll(createSubTasks())
.forEach(task -> task
.join()
.forEach((k, v) -> updateOutput(k, v, output))
);
return output;
}
return process();
}
private void updateOutput(Ip k, Integer v, Map<Ip, Integer> output) {
Integer currentValue = output.get(k);
if (currentValue == null) {
output.put(k, v);
} else {
output.replace(k, currentValue + v);
}
}
private List<ForkJoinDefinition> createSubTasks() {
int size = data.size();
int middle = size / 2;
return List.of(
new ForkJoinDefinition(new ArrayList<>(data.subList(0, middle)), now),
new ForkJoinDefinition(new ArrayList<>(data.subList(middle, size)), now)
);
}
private Map<Ip, Integer> process() {
return groupByIncomingIp(data.stream(), upperTimeBound, lowerTimeBound);
}The only impactful difference here is that I split the dataset into smaller batches until a certain threshold is reached. By default, the threshold is set to 20. After this operation, I start to perform the computations. Computations are the same as in the classic stream approach logic described above - I am using the groupByIncomingIp method.
JMH Setup
All the benchmarks are written using Java Microbenchmark Harness (or JMH for short).
I have used JMH in version 1.37 to run benchmarks. Benchmarks share the same setup: five warm-up iterations and twenty measurement iterations.
There are two different modes here: average time and throughput. In the case of average time, the JMH measures the average execution time of code under benchmark, and output time is expressed in milliseconds.
For throughput, JMH measures the number of operations - full execution of code - in a particular unit of time, milliseconds in this case. The result is expressed in ops per millisecond.
In more JMH syntax:
@Warmup(iterations = 5, time = 10, timeUnit = SECONDS)
@Measurement(iterations = 20, time = 10, timeUnit = SECONDS)
@BenchmarkMode({Mode.AverageTime, Mode.Throughput})
@OutputTimeUnit(MILLISECONDS)
@Fork(1)
@Threads(1)Furthermore, each benchmark has its unique State with a Benchmark scope containing all the data and variables needed by a particular benchmark.
Benchmark State
Classic Stream
The base benchmark state for Classic Stream can be viewed below.
@State(Scope.Benchmark)
public class BenchmarkState {
@Param({"0"})
public int size;
public List<String> input;
public ClassicDefinition definitions;
public ForkJoinPool forkJoinPool_4;
public ForkJoinPool forkJoinPool_8;
public ForkJoinPool forkJoinPool_16;
public ForkJoinPool forkJoinPool_32;
private final LocalDateTime now = LocalDateTime.now();
@Setup(Level.Trial)
public void trialUp() {
input = new TestDataGen(now).generate(size);
definitions = new ClassicDefinition(now);
System.out.println(input.size());
}
@Setup(Level.Iteration)
public void up() {
forkJoinPool_4 = new ForkJoinPool(4);
forkJoinPool_8 = new ForkJoinPool(8);
forkJoinPool_16 = new ForkJoinPool(16);
forkJoinPool_32 = new ForkJoinPool(32);
}
@TearDown(Level.Iteration)
public void down() {
forkJoinPool_4.shutdown();
forkJoinPool_8.shutdown();
forkJoinPool_16.shutdown();
forkJoinPool_32.shutdown();
}
}First, I set up all the variables needed to perform benchmarks. Apart from the size parameter, which is particularly special in this part, thread pools will be used only in the benchmark.
The size parameter, on the other hand, is quite an interesting mechanism of JMH. It allows the parametrization of a certain variable used during the benchmark. You will see how I took advantage of this later when we move to running benchmarks.
As for now, I am using this parameter to generate the input dataset that will remain unchanged throughout the whole benchmark - to achieve better repeatability of results.
The second part is an up method that works similarly to @BeforeEach from the JUnit library.
It will be triggered before each of the 20 iterations of my benchmark and reset all the variables used in the benchmark. Thanks to such a setting, I start with a clear state for every iteration.
The last part is the down method that works similarly to @AfterEach from the JUnit library.
It will be triggered after each of the 20 iterations of my benchmark and shut down all the thread pools used in the iteration - mostly to handle possible memory leaks.
Fork/Join
The state for the Fork/Join version looks as below.
@State(Scope.Benchmark)
public class ForkJoinState {
@Param({"0"})
public int size;
public List<String> input;
public ForkJoinPool forkJoinPool_4;
public ForkJoinPool forkJoinPool_8;
public ForkJoinPool forkJoinPool_16;
public ForkJoinPool forkJoinPool_32;
public final LocalDateTime now = LocalDateTime.now();
@Setup(Level.Trial)
public void trialUp() {
input = new TestDataGen(now).generate(size);
System.out.println(input.size());
}
@Setup(Level.Iteration)
public void up() {
forkJoinPool_4 = new ForkJoinPool(4);
forkJoinPool_8 = new ForkJoinPool(8);
forkJoinPool_16 = new ForkJoinPool(16);
forkJoinPool_32 = new ForkJoinPool(32);
}
@TearDown(Level.Iteration)
public void down() {
forkJoinPool_4.shutdown();
forkJoinPool_8.shutdown();
forkJoinPool_16.shutdown();
forkJoinPool_32.shutdown();
}
}There is no big difference between the setup for classic stream and Fork/Join. The only difference comes from placing the definitions inside benchmarks themselves, not in state as in the case of the Classic approach.
Such change comes from how RecursiveTask works - task executions are memoized and stored - thus, it can impact overall benchmark results.
Benchmark Input
The basic input for benchmarks is a list of strings in the following format:
1,192.168.1.1,2023-10-29T17:33:33.647641574
Or in a more generalized description:
{ordering-number},{ip-like-string},{timestamp}
There are five different input sizes:
- 100
- 1000
- 10000
- 100000
- 1000000
There is some deeper meaning behind the sizes, as I believe that such a size range can illustrate how well the solution will scale and potentially show some performance bottleneck.
Additionally, the overall setup of the benchmark is very flexible, so adding a new size should not be difficult if someone is interested in doing so.
Benchmark Setup
Classic Stream
There is only a single class related to the classic stream benchmark. Different sizes are handled on a State level.
public class ClassicStreamBenchmark extends BaseBenchmarkConfig {
@Benchmark
public void bench_sequential(SingleStreamState state, Blackhole bh) {
Map<String, Integer> map = state.definitions.sequentialStream(state.input);
bh.consume(map);
}
@Benchmark
public void bench_defaultParallelStream(SingleStreamState state, Blackhole bh) {
Map<String, Integer> map = state.definitions.defaultParallelStream(state.input);
bh.consume(map);
}
@Benchmark
public void bench_parallelStreamWithCustomForkJoinPool_4(SingleStreamState state, Blackhole bh) {
Map<String, Integer> map = state.definitions.parallelStreamWithCustomForkJoinPool(state.forkJoinPool_4, state.input);
bh.consume(map);
}
@Benchmark
public void bench_parallelStreamWithCustomForkJoinPool_8(SingleStreamState state, Blackhole bh) {
Map<String, Integer> map = state.definitions.parallelStreamWithCustomForkJoinPool(state.forkJoinPool_8, state.input);
bh.consume(map);
}
@Benchmark
public void bench_parallelStreamWithCustomForkJoinPool_16(SingleStreamState state, Blackhole bh) {
Map<String, Integer> map = state.definitions.parallelStreamWithCustomForkJoinPool(state.forkJoinPool_16, state.input);
bh.consume(map);
}
@Benchmark
public void bench_parallelStreamWithCustomForkJoinPool_32(SingleStreamState state, Blackhole bh) {
Map<String, Integer> map = state.definitions.parallelStreamWithCustomForkJoinPool(state.forkJoinPool_32, state.input);
bh.consume(map);
}
}There are six different benchmark setups of the same logic:
bench_sequential: Simple benchmark with just a singular sequential streambench_defaultParallelStream: Benchmark with default Java parallel stream via.parallelStream()method ofStreamclass in practice acommonPoolfromForkJoinPooland parallelism of 19 (at least on my machine)bench_parallelStreamWithCustomForkJoinPool_4: CustomForkJoinPoolwith parallelism level equal to 4bench_parallelStreamWithCustomForkJoinPool_8: CustomForkJoinPoolwith parallelism level equal to 8bench_parallelStreamWithCustomForkJoinPool_16: CustomForkJoinPoolwith parallelism level equal to 16bench_parallelStreamWithCustomForkJoinPool_32: CustomForkJoinPoolwith parallelism level equal to 32
For classic stream logic, I have 6 different setups and 5 different input sizes resulting in a total of 30 different unique combinations of benchmarks.
Fork/Join
public class ForkJoinBenchmark extends BaseBenchmarkConfig {
@Benchmark
public void bench(ForkJoinState state, Blackhole bh) {
Map<Ip, Integer> map = new ForkJoinDefinition(state.input, state.now).compute();
bh.consume(map);
}
@Benchmark
public void bench_customForkJoinPool_4(ForkJoinState state, Blackhole bh) {
ForkJoinDefinition forkJoinDefinition = new ForkJoinDefinition(state.input, state.now);
Map<Ip, Integer> map = state.forkJoinPool_4.invoke(forkJoinDefinition);
bh.consume(map);
}
@Benchmark
public void bench_customForkJoinPool_8(ForkJoinState state, Blackhole bh) {
ForkJoinDefinition forkJoinDefinition = new ForkJoinDefinition(state.input, state.now);
Map<Ip, Integer> map = state.forkJoinPool_8.invoke(forkJoinDefinition);
bh.consume(map);
}
@Benchmark
public void bench_customForkJoinPool_16(ForkJoinState state, Blackhole bh) {
ForkJoinDefinition forkJoinDefinition = new ForkJoinDefinition(state.input, state.now);
Map<Ip, Integer> map = state.forkJoinPool_16.invoke(forkJoinDefinition);
bh.consume(map);
}
@Benchmark
public void bench_customForkJoinPool_32(ForkJoinState state, Blackhole bh) {
ForkJoinDefinition forkJoinDefinition = new ForkJoinDefinition(state.input, state.now);
Map<Ip, Integer> map = state.forkJoinPool_32.invoke(forkJoinDefinition);
bh.consume(map);
}
}There are six different benchmark setups of the same logic:
bench-> simple benchmark with just a singular sequential streambench_customForkJoinPool_4: CustomForkJoinPoolwith parallelism level equal to 4bench_customForkJoinPool_8: CustomForkJoinPoolwith parallelism level equal to 8bench_customForkJoinPool_16: CustomForkJoinPoolwith parallelism level equal to 16bench_customForkJoinPool_32: CustomForkJoinPoolwith parallelism level equal to 32
For classic stream logic, I have 5 different setups and 5 different input sizes resulting in a total of 25 different unique combinations of benchmarks.
What is more, in both cases I am also using the Blackhole concept from JMH to “cheat” the compiler optimization of dead code. There’s more about Blackholes and their use case here.
Benchmark Environment
Machine 1
The tests we conducted on my Dell XPS with the following parameters:
- OS: Ubuntu 20.04.6 LTS
- CPU: i9-12900HK × 20
- Memory: 64 GB
JVM
- OpenJDK version "21" 2023-09-19
- OpenJDK Runtime Environment (build 21+35-2513)
- OpenJDK 64-Bit Server VM (build 21+35-2513, mixed mode, sharing)
Machine 2
The tests we conducted on my Lenovo Y700 with the following parameters:
- OS: Ubuntu 20.04.6 LTS
- CPU: i7-6700HQ × 8
- Memory: 32 GB
JVM
- OpenJDK version "21" 2023-09-19
- OpenJDK Runtime Environment (build 21+35-2513)
- OpenJDK 64-Bit Server VM (build 21+35-2513, mixed mode, sharing)
For both machines, all side/insignificant applications were closed. I tried to make the runtime system as pure as possible so as to not generate any unwanted performance overhead. However, on a pure Ubuntu server or when run inside a container, the overall performance may differ.
Benchmark Report
The results of running benchmarks are stored in .csv files and the GitHub repository in the reports directory. Furthermore, to ease the download of reports, there is a separate .zip file named reports.zip that contains all the .csv files with data.
Reports directories are structured on per size basis with three special reports for all input sizes:
report_classic: All input sizes for classic streamreport_forkjoin: All input sizes for fork/join streamreport_whole: All input sizes for both classic and fork/join stream
 Each report directory from the above 3 separate files:
Each report directory from the above 3 separate files:
- averagetime.csv: Results for average time mode benchmarks
- throughput.csv: Results for throughput mode benchmarks
- total.csv: Combine results for both modes
![Reports from directory]()
For the particular reports, I have two formats: averagetime.csv and throughput.csv share one format, and total.csv has a separate one. Let’s call them modes and total formats.
The modes report contains eight columns:
- Label: Name of the benchmark
- Input Size: Benchmark input size
- Threads: Number of threads used in benchmark from set 1,4,7,8,16,19,32
- Mode: Benchmark mode, either average time or throughput
- Cnt: The number of benchmark iterations should always be equal to 20
- Score: Actual results of benchmark
- Score Mean Error: Benchmark measurement error
- Units: Units of benchmark either ms/op (for average time) or ops/ms (for throughput)
The total report contains 10 columns:
- Label: Name of the benchmark
- Input Size: Benchmark input size
- Threads: Number of threads used in benchmark from set 1,4,7,8,16,19,32
- Cnt: The number of benchmark iterations should always be equal to 20
- AvgTimeScore: Actual results of benchmark for average time mode
- AvgTimeMeanError: Benchmark measurement error for average time mode
- AvgUnits: Units of benchmark for average time mode in ms/op
- ThroughputScore: Actual results of benchmark
- ThroughputMeanError: Benchmark measurement error for throughput mode
- ThroughputUnits: Units of benchmark for throughput mode in ops/ms
Results Analysis
Assumptions
Baseline
I will present general results and insights based on the size of 10000 – so I will be using the .csv files from the report_10000 directory.
There are two main reasons behind choosing this particular data size.
- The execution time is high enough to show any difference based on different setups.
- Data sizes 100 and 1000 are, in my opinion, too small to notice some performance bottlenecks
Thus, I think that an in-depth analysis of this particular data size would be the most impactful.
Of course, other sizes will also get a results overview but it will not be as thorough as this one unless I encounter some anomalies – in comparison to the behavior for size 10000.
A Word On Fork/Join Native Approach
With the current code under benchmark, there will be performance overhead associated with Fork/Join benchmarks.
As the fork-join benchmark logic heavily relies on splitting the input dataset there must be a moment when all of the results are combined into a single cohesive output. This is the fragment that is not included in normal benchmarks, so correctly understanding its impact on overall performance is crucial.
Please remember about this.
Analysis
Machine 1 (20 cores)
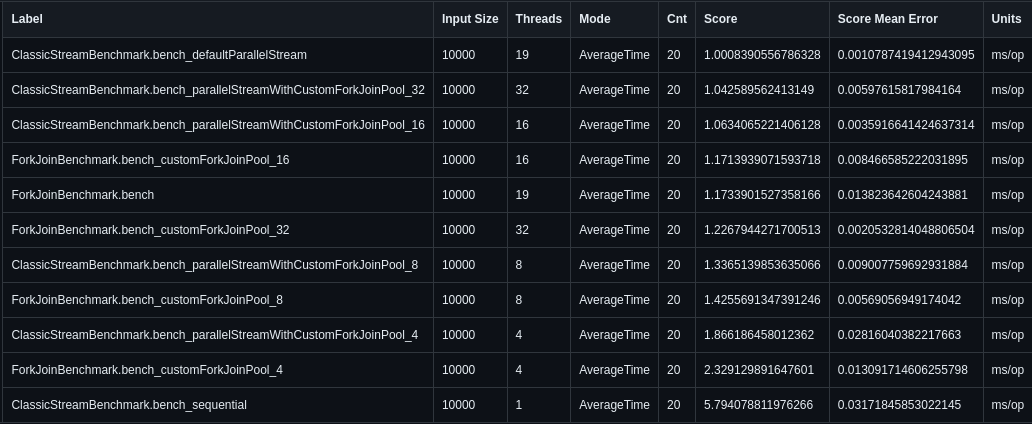 As you can see above the best overall result for input volume 10 thousands on machine 1 belongs to versions with
As you can see above the best overall result for input volume 10 thousands on machine 1 belongs to versions with defaultParallelStream.

For ClassicStream-based benchmarks, bench_defaultParallelStream returns by far the best result. Even when we take into consideration a possible error in measurements, it still comes on top.
Setup for ForkJoinPool with parallelism 32 and 16 and return worse results. On one hand, it is surprising - for parallelism 32, I would expect a better score than for the default pool (parallelism 19). However, parallelism 16 has worse results than both parallelism 19 and 32.
With 20 CPU threads on Machine 1, parallelism 32 is not enough to picture performance degradation caused by an overabundance of threads. However, you would be able to notice such behavior for Machine 2. I would assume that to show such behavior on Machine 1, the parallelism should be set to 64 or more.
What is curious here is that the relationship with bench_defaultParallelStream coming on top seems not to hold for higher input sizes of 100k and one million. The best performance belongs to bench_parallelStreamWithCustomForkJoinPool_16 which may indicate that in the end, reasonably smaller parallelism may be a good idea.
The Fork/Join-based implementation is noticeably slower than the default parallel stream implementation, with around 10 % worse performance. This pattern also occurs for other sizes. It confirms my assumption from above that joining different smaller parts of a split data set has a noticeable impact.
Of course, the worst score belongs to the single-threaded approach and is around 5 times slower than the best result. Such a situation is expected, as a single-threaded benchmark is a kind of baseline for me. I want to check how far we can move its execution time and 5 times better average execution time in the best-case scenario seems like a good score.
As for the value of the score mean error it is very very small. In the worst case (the highest error), it is within 1,5% of its respectable score (result for ClassicStreamBenchmark.bench_parallelStreamWithCustomForkJoinPool_4).
In other cases, it varies from 0,1 % to 0,7 % of the overall score.
There seems to be no difference in result positions for sizes above 10 thousand.
Machine 2 (8 cores)
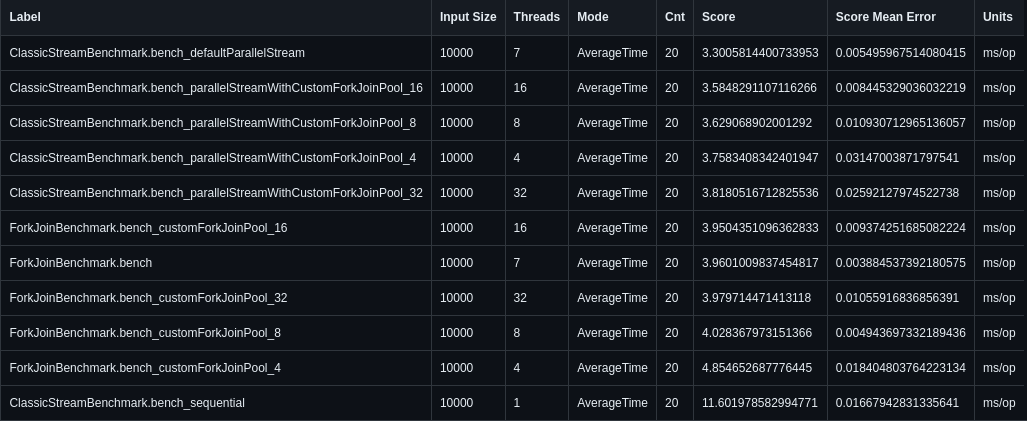 As in the case of Machine 1, the first score also belongs to
As in the case of Machine 1, the first score also belongs to bench_defaultParallelStream. Again, even when we consider a possible measurement error, it still comes out on top: nothing especially interesting. What is interesting, however, is that the pattern of the first 3 positions for Machine 2 changes quite a lot based on higher input sizes. For input 100 to 10000, we have somewhat similar behavior, with
What is interesting, however, is that the pattern of the first 3 positions for Machine 2 changes quite a lot based on higher input sizes. For input 100 to 10000, we have somewhat similar behavior, with bench_defaultParallelStream occupying 1 position and bench_parallelStreamWithCustomForkJoinPool_8 following shortly after.
On the other hand, for inputs 100000 and 1000000, the first position belongs to bench_parallelStreamWithCustomForkJoinPool_8 followed by bench_parallelStreamWithCustomForkJoinPool_32. While bench_defaultParallelStream is moved to 4th and 3rd positions.
Another curious thing about Machine 2 may be that for smaller input sizes, parallelism 32 is quite far away from the top. Such performance degradation may be caused by the overabundance of threads compared to the 8 CPU threads total available on the machine.
Nevertheless, on inputs 100000 and 1000000, ForkJoinPool with parallelism 32 is in the second position, which may indicate that for longer time spans, such overabundance of threads is not a problem.
Some other aspects that are very similar to the behavior of Machine 1 are skipped here and are mentioned below.
Common Points
There are a few observations valid for both machines:
- My
ForkJoinNative(“naive”)-based benchmarks yield results that are noticeably worse, around 10% on both machines, than those delivered by default versions of a parallel stream or even ones withcustomForkJoinPool. Of course, one of the reasons is that they are not optimized in any way. There are probably some low-hanging performance fruits here. Thus, I strongly recommend getting familiar with the Fork/Join framework, before moving its implementations to production. - The time difference between positions one to three is very, very small - less than a millisecond. Thus, it may be hard to achieve any type of repeatability for these benchmarks. With such a small difference it is easy for the results distribution to differ between benchmark runs.
- The mean error of the scores is also very, very small, up to 2% of the overall score in worse cases - mostly less than 1%. Such low error may indicate two things. The first, benchmarks are reliable because results are focused around some point. If there were some anomalies along the way the error would be higher. Second, JMH is good at making measurements.
- There is no breaking difference in results between throughput and average time modes. If one of the benchmarks performed well in average time mode, it would also perform well in throughput mode.
Above you can see all the differences and similarities I found inside the report files. If you find anything else that seems to be interesting do not hesitate to mention it in the comment section below.
Summary
Before we finally split ways for today, I would like to mention one more very important thing:
JAVA IS NOT SLOW
Processing the list with one million elements, all potential JMH overhead, and a single thread takes 560 milliseconds (Machine 1) and 1142 milliseconds (Machine 2). There are no special optimizations or magic included, just pure default JVM.
The total best time for processing one million elements for Machine 1 was 88 milliseconds for ClassicStreamBenchmark.bench_parallelStreamWithCustomForkJoinPool_16. In the case of Machine 2, it was 321 milliseconds for ClassicStreamBenchmark.bench_parallelStreamWithCustomForkJoinPool_8.
Although both results may not be as good as C/C++-based solutions, the relative simplicity and descriptiveness of the approach make it very interesting, in my opinion.
Overall, it is quite a nice addition to Java’s one billion rows challenge.
I would just like to mention that all the reports and benchmark code are in the GitHub repository (linked in the introduction of this article). You can easily verify my results and compare them to the benchmark behavior on your machine.
Furthermore, to ease up the download of reposts there is a separate .zip file named reports.zip that contains all the .csv files with data.
Besides, remember Java is not slow.
Thank you for your time.
Review by: Krzysztof Ciesielski, Łukasz Rola
Published at DZone with permission of Bartłomiej Żyliński. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments