AWS-CodeArtifact vs JFrog-Artifactory
Take a look at AWS-CodeArtifact versus JFrog-Artifactory.
Join the DZone community and get the full member experience.
Join For FreeWelcome, AWS-CodeArtifact, to the world of repository managers.
Amazon has marked the Managed Service AWS CodeArtifactory as a GA, thereby giving the general public access. But what is this service all about, and how does it compare to JFrog-Artifactory? We'll take a quick look at that here in detail.
BirdEye View
In summary, one can say that Amazon is immersed in an existing market in which some competitors have a much longer history. You can see that from the variety of functions on the JFog site. There is still significant potential here on the Amazon side. As with all Amazon products, the use of this service is fully tied to the AWS cloud itself. If you look at the price model, Amazon has the billing model that is typical for this platform and is difficult to predict, based on read- and write- cycles. Anyone who can foresee this must know and be able to estimate their development processes down to very delicate actions.
If this is not the case, cost accounting can quickly reach areas that were not foreseen. Here, the simple license model from JFrog has a clear advantage, and there are no surprises in the planning. With JFrog-Artifactory, you also have no vendor lock-in in terms of the runtime environment and IT architecture. Here you can be sure that you will have the free decision in the future towards the cloud, or even out of it again. Migration scenarios are possible in any mix between OnPrem and SAAS.
In terms of supported technologies, there is a distinct advantage of JFrog products. And the design options for the repository structures are much more flexible compared to the CodeArtifact options. Amazon has just three package managers in its portfolio. And also in the way the compositions can be set up, the virtual repositories are a feature from Artifactory that leads the field unbeaten. It remains to be seen what Amazon wants to bring up next.
Repositories and How to Use Binaries Efficiently
After we have seen what the basic options for repository composition look like, the question arises which advantages and disadvantages result from this for production. At this point, I assume that we are in a DevOps or already in a DevSecOps environment. For each change made available in a source code repository, a build process starts, which then leads to a binary package stored in an artifact repository.
This behavior inevitably leads to a sharp increase in the resources required to keep these binary packages available for further progression. On the other hand, you also want to prevent partial results or results that have caused a termination within processing to bleed into other production processes. It is therefore essential to make a very accurate separation here. How can this be implemented in the two systems mentioned here?
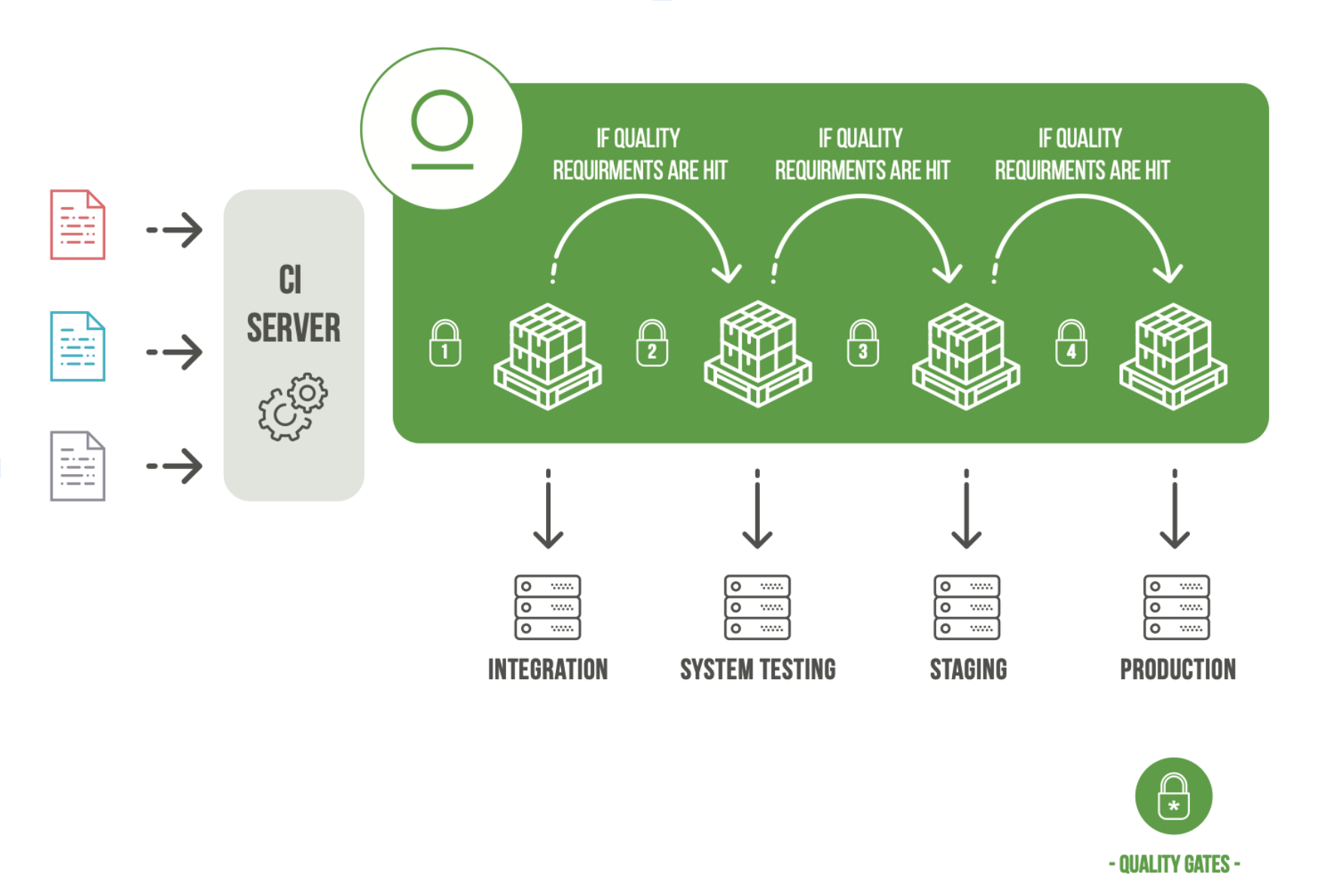
In addition to the previously mentioned approach, the amount of new created binary fragments usually decreases with every further step in the build pipeline. For example; From several feature branches, a develop branch from which a release branch can then become. With every further development stage, i.e. with every additional step within the production chain, the frequency with which artifacts generated decreases. As soon as a new binary has been created in a develop branch that contains the source code changes of an analogous feature branch, all created artifacts of the corresponding feature branch can be removed. Removing can now mean that they are deleted, or just hidden from the active repository structures of the subsequent production stages.
Now we come to our candidate from Amazon. Here you can build a tree from repositories. This structure enables you to establish a caching process. But how do we isolate the individual stages in the production chain? Based on the tree structure and the current restriction that you can only ever have one higher-level repository, only stringent top-down structures can be mapped. Cross-sectional structures cannot be represented in this way. A subsequent stage cannot have a sub-selection of the higher-level element here. To isolate the binaries from the feature branches, you have to set up your structure at this point and then rebuild all associated binary packages during a merge in the developer branch to save the result again in the repository belonging to the develop branch. This approach has some conceptual weaknesses that I would like to point out here explicitly.
One point is that you have to reproduce this procedure in every project, which is only a matter of time before bumps and errors creep into this structure. Additionally, running this procedure means that the results of a previously executed build process must be delivered again.
It is better not only to minimize this effort at this point, which will bring temporal, financial and ecological advantages but also follow the DRY principle very clearly.
What is the solution with Artifactory? Here you can assign a dedicated private local repository to each production stage in which the artifacts created. Because all operations in the JFrog products offered via REST as well, it is also possible to automatically assign a repository to a newly created feature branch. If you want to map the isolation even more explicitly, create a separate artifact repository for each processing level in a build-plan. This solution then has the additional advantage that the last failed step of the partially completed build processes can be started again at the previous finished point without having to go through all previous stages. DRY!
The needed cross-sectional repositories can be defined using virtual repositories. Only those elements that are necessary for this production stage are then active within these repositories. This concept helps that no artifacts from previous steps can bleed in that do not belong to precisely this production stage for exactly this entity of the outcome to be generated. Maintenance of the artifact inventory can also very efficiently implemented since the partial repositories that are no longer required are deleted or deactivated directly.
Last Words
In terms of supported technologies, there is a distinct advantage of JFrog With this brief overview; this topic is far from exhausted. To do this, I will gradually look at the various sub-areas over the next few weeks and make a direct comparison.
If particular aspects of these comparisons are of interest, please contact me directly. The order of the areas has not yet been determined. But if you want to get a realistic picture, I cordially invite you to start a trial and try it out by yourself.
Cheers,
Sven
Opinions expressed by DZone contributors are their own.
Comments