Telemetry Pipelines Workshop: Avoiding Telemetry Data Loss With Fluent Bit
Take a look at how Fluent Bit filesystem buffering provides a data- and memory-safe solution to the problems of backpressure and data loss.
Join the DZone community and get the full member experience.
Join For FreeAre you ready to get started with cloud-native observability with telemetry pipelines?
This article is part of a series exploring a workshop guiding you through the open source project Fluent Bit, what it is, a basic installation, and setting up the first telemetry pipeline project. Learn how to manage your cloud-native data from source to destination using the telemetry pipeline phases covering collection, aggregation, transformation, and forwarding from any source to any destination.
In the previous article in this series, we explored what backpressure was, how it manifests in telemetry pipelines, and took the first steps to mitigate this with Fluent Bit. In this article, we look at how to enable Fluent Bit features that will help with avoiding telemetry data loss as we saw in the previous article.
You can find more details in the accompanying workshop lab.
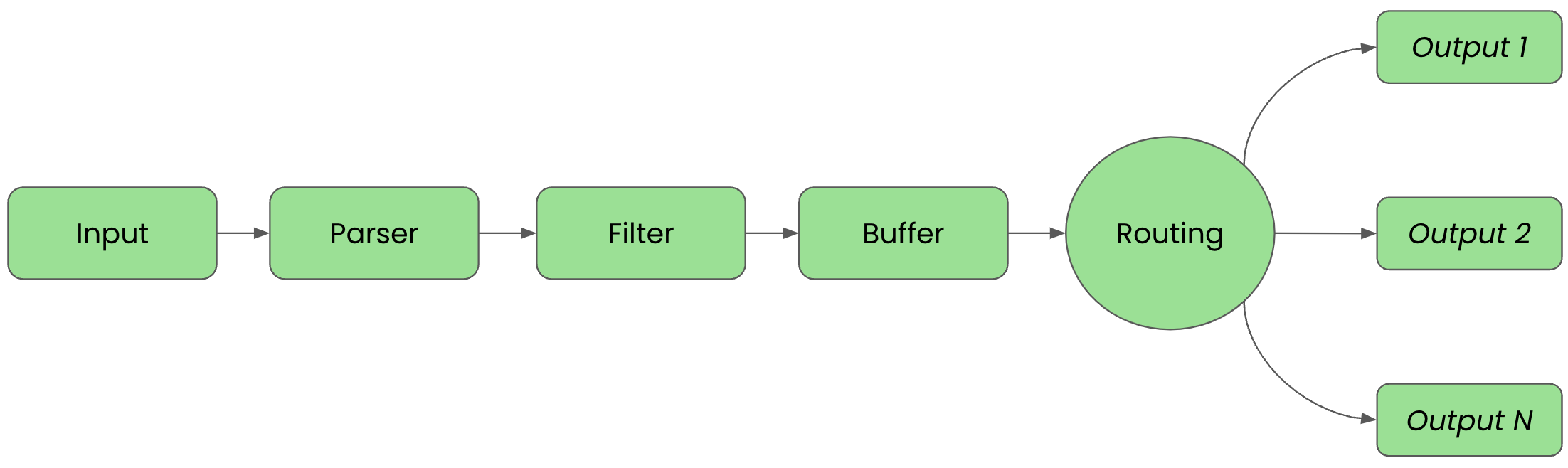
Before we get started it's important to review the phases of a telemetry pipeline. In the diagram below we see them laid out again. Each incoming event goes from input to parser to filter to buffer to routing before they are sent to its final output destination(s).
For clarity in this article, we'll split up the configuration into files that are imported into a main fluent bit configuration file we'll name workshop-fb.conf.
Tackling Data Loss
Previously, we explored how input plugins can hit their ingestion limits when our telemetry pipelines scale beyond memory limits when using default in-memory buffering of our events. We also saw that we can limit the size of our input plugin buffers to prevent our pipeline from failing on out-of-memory errors, but that the pausing of the ingestion can also lead to data loss if the clearing of the input buffers takes too long.
To rectify this problem, we'll explore another buffering solution that Fluent Bit offers, ensuring data and memory safety at scale by configuring filesystem buffering.
To that end, let's explore how the Fluent Bit engine processes data that input plugins emit. When an input plugin emits events, the engine groups them into a Chunk. The chunk size is around 2MB. The default is for the engine to place this Chunk only in memory.
We saw that limiting in-memory buffer size did not solve the problem, so we are looking at modifying this default behavior of only placing chunks into memory. This is done by changing the property storage.type from the default Memory to Filesystem.
It's important to understand that memory and filesystem buffering mechanisms are not mutually exclusive. By enabling filesystem buffering for our input plugin we automatically get performance and data safety
Filesystem Buffering Tips
When changing our buffering from memory to filesystem with the property storage.type filesystem, the settings for mem_buf_limit are ignored.
Instead, we need to use the property storage.max_chunks_up for controlling the size of our memory buffer. Shockingly, when using the default settings the property storage.pause_on_chunks_overlimit is set to off, causing the input plugins not to pause. Instead, input plugins will switch to buffering only in the filesystem. We can control the amount of disk space used with storage.total_limit_size.
If the property storage.pause_on_chunks_overlimit is set to on, then the buffering mechanism to the filesystem behaves just like our mem_buf_limit scenario demonstrated previously.
Configuring Stressed Telemetry Pipeline
In this example, we are going to use the same stressed Fluent Bit pipeline to simulate a need for enabling filesystem buffering. All examples are going to be shown using containers (Podman) and it's assumed you are familiar with container tooling such as Podman or Docker.
We begin the configuration of our telemetry pipeline in the INPUT phase with a simple dummy plugin generating a large number of entries to flood our pipeline with as follows in our configuration file inputs.conf (note that the mem_buf_limit fix is commented out):
# This entry generates a large amount of success messages for the workshop.
[INPUT]
Name dummy
Tag big.data
Copies 15000
Dummy {"message":"true 200 success", "big_data": "blah blah blah blah blah blah blah blah blah"}
#Mem_Buf_Limit 2MB
Now ensure the output configuration file outputs.conf has the following configuration:
# This entry directs all tags (it matches any we encounter) # to print to standard output, which is our console. [OUTPUT] Name stdout Match *
With our inputs and outputs configured, we can now bring them together in a single main configuration file. Using a file called workshop-fb.conf in our favorite editor, ensure the following configuration is created. For now, just import two files:
# Fluent Bit main configuration file. # # Imports section. @INCLUDE inputs.conf @INCLUDE outputs.conf
Let's now try testing our configuration by running it using a container image. The first thing that is needed is to ensure a file called Buildfile is created. This is going to be used to build a new container image and insert our configuration files. Note this file needs to be in the same directory as our configuration files, otherwise adjust the file path names:
FROM cr.fluentbit.io/fluent/fluent-bit:3.0.4 COPY ./workshop-fb.conf /fluent-bit/etc/fluent-bit.conf COPY ./inputs.conf /fluent-bit/etc/inputs.conf COPY ./outputs.conf /fluent-bit/etc/outputs.conf
Now we'll build a new container image, naming it with a version tag as follows using the Buildfile and assuming you are in the same directory:
$ podman build -t workshop-fb:v8 -f Buildfile STEP 1/4: FROM cr.fluentbit.io/fluent/fluent-bit:3.0.4 STEP 2/4: COPY ./workshop-fb.conf /fluent-bit/etc/fluent-bit.conf --> a379e7611210 STEP 3/4: COPY ./inputs.conf /fluent-bit/etc/inputs.conf --> f39b10d3d6d0 STEP 4/4: COPY ./outputs.conf /fluent-bit/etc/outputs.conf COMMIT workshop-fb:v6 --> e74b2f228729 Successfully tagged localhost/workshop-fb:v8 e74b2f22872958a79c0e056efce66a811c93f43da641a2efaa30cacceb94a195
If we run our pipeline in a container configured with constricted memory, in our case, we need to give it around a 6.5MB limit, then we'll see the pipeline run for a bit and then fail due to overloading (OOM):
$ podman run --memory 6.5MB --name fbv8 workshop-fb:v8
The console output shows that the pipeline ran for a bit; in our case, below to event number 862 before it hit the OOM limits of our container environment (6.5MB):
...
[860] big.data: [[1716551898.202389716, {}], {"message"=>"true 200 success", "big_data"=>"blah blah blah blah blah blah blah blah"}]
[861] big.data: [[1716551898.202389925, {}], {"message"=>"true 200 success", "big_data"=>"blah blah blah blah blah blah blah blah"}]
[862] big.data: [[1716551898.202390133, {}], {"message"=>"true 200 success", "big_data"=>"blah blah blah blah blah blah blah blah"}]
[863] big.data: [[1 <<<< CONTAINER KILLED WITH OOM HERE
We can validate that the stressed telemetry pipeline actually failed on an OOM status by viewing our container, and inspecting it for an OOM failure to validate our backpressure worked:
# Use the container name to inspect for reason it failed $ podman inspect fbv8 | grep OOM "OOMKilled": true,
Already having tried in a previous lab to manage this with mem_buf_limit settings, we've seen that this also is not the real fix. To prevent data loss we need to enable filesystem buffering so that overloading the memory buffer means that events will be buffered in the filesystem until there is memory free to process them.
Using Filesystem Buffering
The configuration of our telemetry pipeline in the INPUT phase needs a slight adjustment by adding storage.type to as shown, set to filesystem to enable it. Note that mem_buf_limit has been removed:
# This entry generates a large amount of success messages for the workshop.
[INPUT]
Name dummy
Tag big.data
Copies 15000
Dummy {"message":"true 200 success", "big_data": "blah blah blah blah blah blah blah blah blah"}
storage.type filesystem
We can now bring it all together in the main configuration file. Using a file called the following workshop-fb.conf in our favorite editor, update the file to include SERVICE configuration is added with settings for managing the filesystem buffering:
# Fluent Bit main configuration file. [SERVICE] flush 1 log_Level info storage.path /tmp/fluentbit-storage storage.sync normal storage.checksum off storage.max_chunks_up 5 # Imports section @INCLUDE inputs.conf @INCLUDE outputs.conf
A few words on the SERVICE section properties might be needed to explain their function:
storage.path- Putting filesystem buffering in the tmp filesystemstorage.sync- Using normal and turning off checksum processingstorage.max_chunks_up- Set to ~10MB, amount of allowed memory for events
Now it's time for testing our configuration by running it using a container image. The first thing that is needed is to ensure a file called Buildfile is created. This is going to be used to build a new container image and insert our configuration files. Note this file needs to be in the same directory as our configuration files, otherwise adjust the file path names:
FROM cr.fluentbit.io/fluent/fluent-bit:3.0.4 COPY ./workshop-fb.conf /fluent-bit/etc/fluent-bit.conf COPY ./inputs.conf /fluent-bit/etc/inputs.conf COPY ./outputs.conf /fluent-bit/etc/outputs.conf
Now we'll build a new container image, naming it with a version tag, as follows using the Buildfile and assuming you are in the same directory:
$ podman build -t workshop-fb:v9 -f Buildfile STEP 1/4: FROM cr.fluentbit.io/fluent/fluent-bit:3.0.4 STEP 2/4: COPY ./workshop-fb.conf /fluent-bit/etc/fluent-bit.conf --> a379e7611210 STEP 3/4: COPY ./inputs.conf /fluent-bit/etc/inputs.conf --> f39b10d3d6d0 STEP 4/4: COPY ./outputs.conf /fluent-bit/etc/outputs.conf COMMIT workshop-fb:v6 --> e74b2f228729 Successfully tagged localhost/workshop-fb:v9 e74b2f22872958a79c0e056efce66a811c93f43da641a2efaa30cacceb94a195
If we run our pipeline in a container configured with constricted memory (slightly larger value due to memory needed for mounting the filesystem) - in our case, we need to give it around a 9MB limit - then we'll see the pipeline running without failure:
$ podman run -v ./:/tmp --memory 9MB --name fbv9 workshop-fb:v9
The console output shows that the pipeline runs until we stop it with CTRL-C, with events rolling by as shown below.
...
[14991] big.data: [[1716559655.213181639, {}], {"message"=>"true 200 success", "big_data"=>"blah blah blah blah blah blah blah"}]
[14992] big.data: [[1716559655.213182181, {}], {"message"=>"true 200 success", "big_data"=>"blah blah blah blah blah blah blah"}]
[14993] big.data: [[1716559655.213182681, {}], {"message"=>"true 200 success", "big_data"=>"blah blah blah blah blah blah blah"}]
...
We can now validate the filesystem buffering by looking at the filesystem storage. Check the filesystem from the directory where you started your container. While the pipeline is running with memory restrictions, it will be using the filesystem to store events until the memory is free to process them. If you view the contents of the file before stopping your pipeline, you'll see a messy message format stored inside (cleaned up for you here):
$ ls -l ./fluentbit-storage/dummy.0/1-1716558042.211576161.flb -rw------- 1 username groupname 1.4M May 24 15:40 1-1716558042.211576161.flb $ cat fluentbit-storage/dummy.0/1-1716558042.211576161.flb ??wbig.data???fP?? ?????message?true 200 success?big_data?'blah blah blah blah blah blah blah blah???fP?? ?p???message?true 200 success?big_data?'blah blah blah blah blah blah blah blah???fP?? ߲???message?true 200 success?big_data?'blah blah blah blah blah blah blah blah???fP?? ?F???message?true 200 success?big_data?'blah blah blah blah blah blah blah blah???fP?? ?d???message?true 200 success?big_data?'blah blah blah blah blah blah blah blah???fP?? ...
Last Thoughts on Filesystem Buffering
This solution is the way to deal with backpressure and other issues that might flood your telemetry pipeline and cause it to crash. It's worth noting that using a filesystem to buffer the events also introduces the limits of the filesystem being used.
It's important to understand that just as memory can run out, so too can the filesystem storage reach its limits. It's best to have a plan to address any possible filesystem challenges when using this solution, but this is outside the scope of this article.
This completes our use cases for this article. Be sure to explore this hands-on experience with the accompanying workshop lab.
What's Next?
This article walked us through how Fluent Bit filesystem buffering provides a data- and memory-safe solution to the problems of backpressure and data loss.
Stay tuned for more hands-on material to help you with your cloud-native observability journey.
Published at DZone with permission of Eric D. Schabell, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments