API Gateway Pattern: Features and the AWS Implementation
This article will provide a deep-dive study of API Gateways, starting with the problems that are addressed by API Gateways in enterprise computing
Join the DZone community and get the full member experience.
Join For FreeAPI Gateway is an architectural pattern to create a façade that exposes the internal system’s data to external clients in a decoupled layer, reducing the dependency between frontend and backend components. Nowadays, that pattern is widely spread in the computing field being used in business applications and integration solutions for small, medium, and large enterprises. The value of breaking the dependency between clients and backend implementations is very substantial. Many paramount functions of modern distributed systems can be implemented in the API gateway. The list of functions is quite large and will be elucidated in the next sections of this article.
Currently, we see API gateways usage in critical mission applications and use cases such as microservices architecture, legacy monoliths, monolith migration to microservices projects, and integration layers. Additionally, the API gateways are involved in different deployment models, since the bare-metal servers running on-premises, virtual machines like Amazon EC2, and containerized solutions such as Kubernetes on Amazon EKS, even in the modern serverless computing platform, covering all possible deployment spectrum available today. The issues solved using the API Gateway pattern are explored in section 2.
The functions implemented by the API Gateways available today vary significantly; where on one hand, some implementations have only a few features, but on the other hand, they are fully covered. These functions are also known as edge functions. They need to be implemented somewhere, they could be implemented in the business layer as in monolithic applications, or eventually in an API Gateway, or finally, they could be in other external extra components. For instance, one can implement an authentication function in the business layer instead of in the API gateway; however, decoupling such functionality into API Gateway has many advantages, as shown in section 3 of this article.
Amazon API Gateway is the Amazon Web Service (AWS) implementation of the API Gateway Pattern; it is a fully managed solution, easily integrated with other AWS services. The Amazon implementation is a very robust service that provides an easy-to-use graphical user interface and can be automated using CLI or infrastructure as a code (IaC) approach. Section 4 explores the features (edge functions) implemented by the current Amazon implementation of the API Gateway available at AWS.
This article will provide a deep-dive study of API Gateways, starting with the problems that are addressed by API Gateways in enterprise computing, then providing specification research of functions or features known in the entire computing field, presenting, describing, and exploring their details. Finally, the Amazon implementation will be covered, contrasting the researched API Gateway features and what is found currently on the Amazon implementation.
Why Use the API Gateway Pattern?
It needs to be clear why the API Gateway is needed as a new component in the already huge computing infrastructure in place in our data centers, on-premises or in the cloud, because of the high cost involved in designing, implementing, deploying, and managing a new highly scalable and available component such as a gateway that must be included into that big ecosystem. There are two main reasons for introducing a gateway, first decoupling software to expose internal business functions to the external world — improving the reuse of software components and causing a faster time to market. Second, routing and controlling the inbound traffic to improve security and management.
Decoupling Software
Well, the companies once were in an evolved stage of their internal process automation where they have, in general, their processes being performed automatically and autonomously in a big application (that is what we call legacy and nowadays backend applications). However, that application was only produced to automatize these internal processes, not bringing external stakeholders to the automation. So, to keep competing in a very dynamic market, those companies were wanting to expose their internal data and functions, stored, and running in their backend systems, to be consumed by external applications creating a more interactive and productive ecosystem. To cope with those new requirements, in the late 1990s, the terms business to customer (B2C) and business to business (B2B) became immensely popular during the dot-com E-Commerce boom. The IT teams dealt with that solution by developing what was called the three-tier web applications, integration systems with point-to-point connections linking their own applications with their partners. The introduction of a web layer produced connectivity between companies, their customers, and partners. See Figure 1, which shows the web layer and a high-level picture of the entire model used in that three-tier solution.
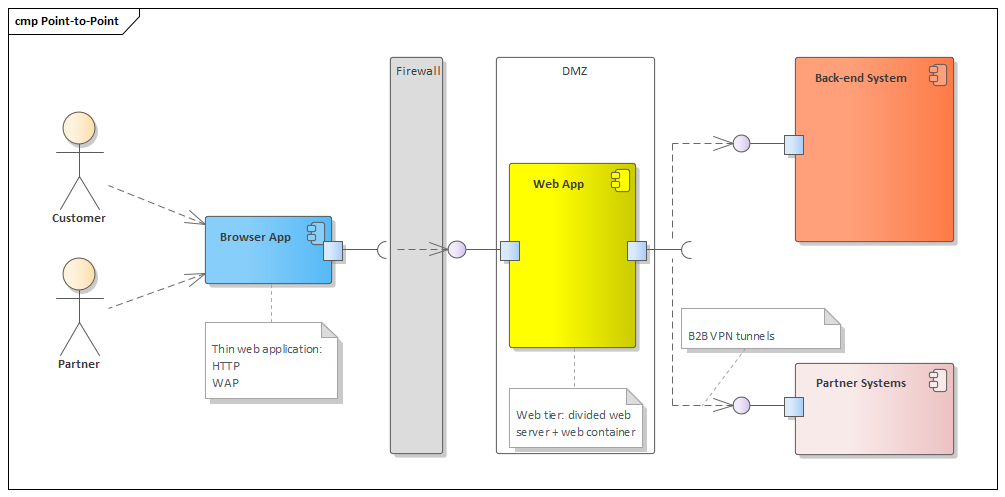
Figure 1: Three-tier architectural solution
Figure 1 shows the three-tier solution that was used to be created to expose the backend systems to the front-end web tier running in Internet browsers. The browser application was thin and statically based pages (HTML) provided by the dynamic web applications running in the middleware. This web application was a normally massive monolithic integration layer, a glue between frontend and backend, which provided data from the backend systems and potentially integrated with the partners’ systems. It was performed by creating many point-to-point integrations that are not a best practice due to the lack of reusability and the extensive infrastructure work necessary because of the communication protocols that were based on Internet standards and consequently not firewall-friendly.
Also, the web application in the middleware was what is called today a distributed “big ball of mud,” meaning it has the symptoms of a monolithic hell described by Sam Newman [1]: hard to maintain (development struggles), difficult to test, increases time to market, stuck with outdated technology stack, and inflexible for scaling.
From the business perspective, the vast number of technical issues pointed out were almost not noticed drawbacks of using the three-tier application architecture since the underlying technology is transparent for the business people, but the most important complication resides in the cited time to market. It generates a delay in creating new features for existing applications, affecting the dynamic of the competitive market, which needs high-speed response when creating new functionalities which will improve the automation and provide differentiated services overcoming their competitors.
Therefore, to make clear the necessity of a gateway to solving the symptoms of monolithic hell in that three-tier application scenario, the called edge functions that were running together with the business logic in the web tier, as shown in Figure 1, have been decoupled, resulting in a separation of concerns from our monolith applications into a more distributed system with open standard protocols, breaking down into more manageable independent components, see figure 2, which is also interacting with the backend, but it is breaking the functions inside the monolith web app into microservices and putting a gateway in place to expose the APIs to external consumers, a new infrastructure design was born. The first step in the study of API Gateways is shedding some light into what are the edge functions that would be decomposed from the monolith and integrate the gateway solution, which has been reached after researching API gateway’s documentation in the field and will be explored in section 3.
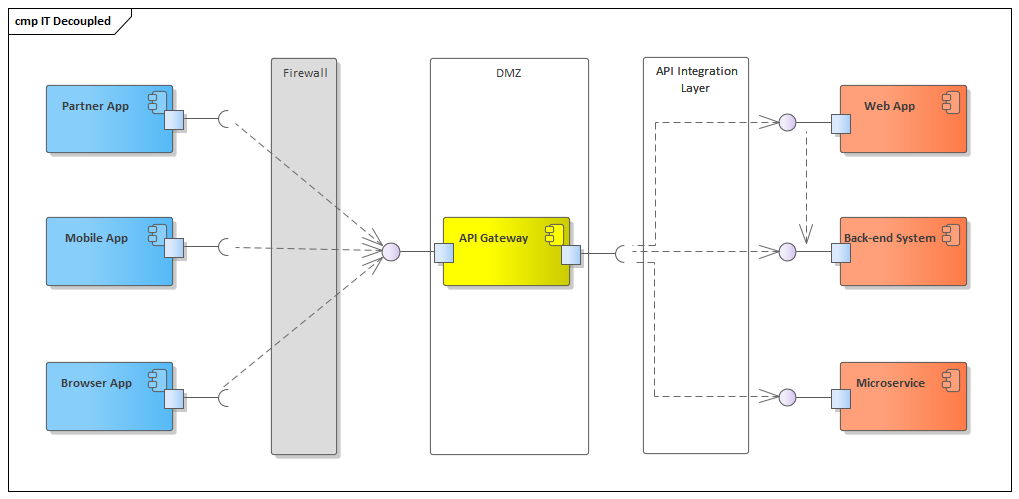
Figure 2: API Gateway Breaking the Web App Monolith
Notice in the figure that firstly: the partner application has turned into a loose-coupled API participant in the solution instead of an integration point-to-point in the backend. Secondly, the Web App that was concentrating the direct call from the clients is now protected by the gateway running safely in the intranet network instead of the risky DMZ layer. And finally, the Web App has been broken into one microservice, bringing all the advantages of a microservices architecture that are not covered in this text (if you want to go deeper about microservices architecture, see [2]).
Controlling Inbound Traffic
The inbound traffic, normally HTTP protocol, needs to be routed from the consumer to the correct service that implements the function or data resource exposure needed by an API consumer. The consumer or client can be a JavaScript running in the browser-rich client applications (React, Angular, or simple HTML with Ajax calls, etc.), native or web mobile applications, or third-party applications consuming the underlying APIs. The traffic routing in API Gateways is a means to justify an end because it needs to perform the edge functions and act as a man in the middle for all requests made to the exposed backend systems, which enables it to make interceptions and add functionalities on them.
Let us see how a very common scenario of exposing the backend through a RESTful API without an API Gateway, the consumer will send fine-grained synchronous HTTP REST requests, which will be received directly by the backend system that will compute and return the processed response. It functionally works fine; however, when processing a real-life application, it just does not need only one request to get the needed information. For instance, to retrieve customer information in a web dashboard, many requests are needed targeting many services in the backend. One call for basic information, another for the customer’s related accounts, the customer’s balance, and so on. In that very granular scenario, it will be laborious to merge such information together, and it needs to be done on the client side, increasing the code base and resource utilization, impacting especially when the client has limited resources, such as when using smartphones or tablets.
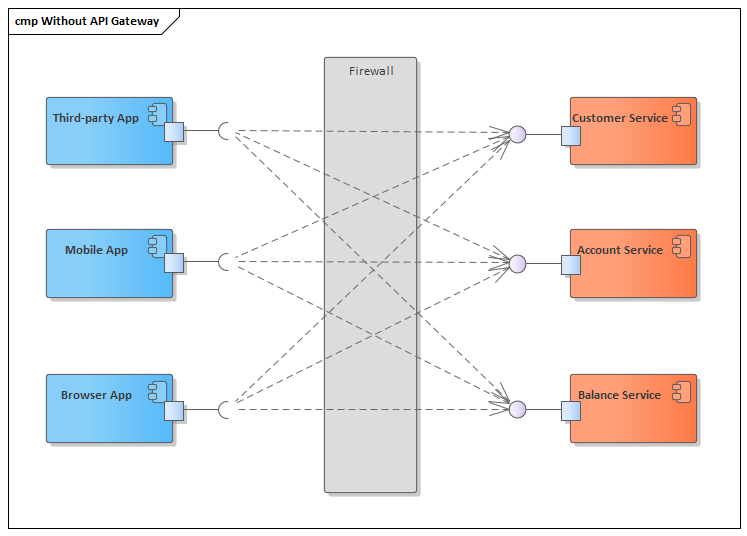
Figure 3: Data Processing without API Gateway
Figure 3 shows three consumers in blue, sending three fine-grained calls to each backend component in orange. The consumers are responsible for composing the customer information doing it inside their own code, then presenting the collected data to the application user. Those fine-grained calls are remote calls commonly through the Internet. This increases the delay in presenting data in the front end, and furthermore, they have direct access to the services without any authentication or authorization mechanism acting before reaching the core business software components and the underlying infrastructure; it is very susceptible to attacks.
The fine-grain access problem has a design pattern called Façade; the Façade pattern is described by Eric Gamma et al. [3]; here it is implemented by the API Gateway, which will result in what is shown in the next picture:
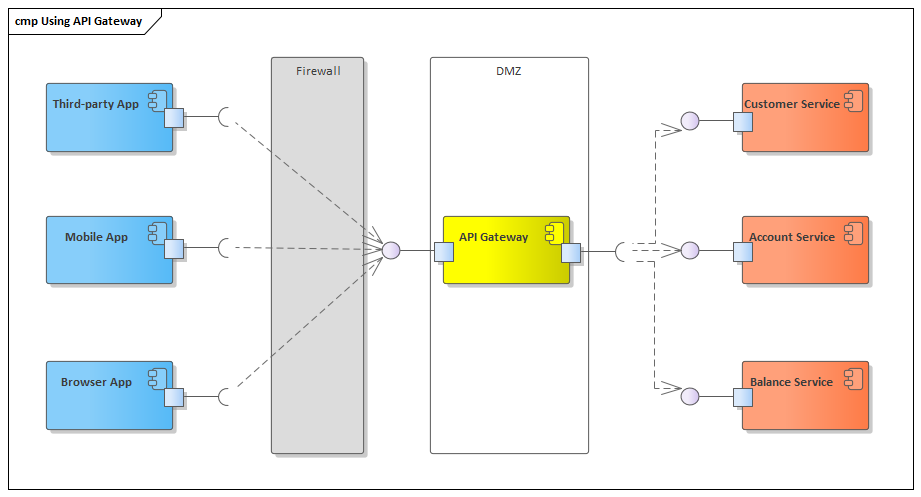
Figure 4: API Gateway as Façade exposing computing services.
Figure 4 brings the API Gateway, which decouples the API composition from the clients bringing a solution that centralizes the inbound calls and controls the routing of the outbound calls. An important, could say mandatory, management concentrator component in modern computing architecture. Notice also that the infrastructure has changed, creating a Demilitarized Zone (DMZ) whose deployment, for security’s sake, should be in a different subnetwork, with the gateway which can provide an interface to the Internet, not exposing the business components before authenticating the consumers. The DMZ should be a public subnet, and the services must be deployed in a called private subnet (very reduced access, normally only through accessed using bastion services); those services would whitelist the gateway address in their configuration, creating one more security barrier against the potential attackers.
Notice that the level of security and control promoted by traffic routing is huge, which is enough to justify the investments in a component such as the API gateway with high availability and scalability, which certainly increases the design, development, deployment, and operational IT costs. Additionally, notice the flows in Figure 3 contrasting with the flows in Figure 4; you will realize that it has significantly improved the roundtrips between the client and the backend systems.
Inside the gateway implementation, it will concentrate on the functions mentioned in this section adding many others called edge functions. The next section will explore the API Gateway of these edge functions or features.
The API Gateways Features
The API Gateway research outcome for having a holistic view of the features it could come across, also known as its edge functions, resulted in twenty-two features to be potentially implemented in an API Gateway solution. These functions were split into six categories: Core, Bridging, Performance, Security, Quality of Services, and Operational.
The Core features are the ones that are indispensable for every gateway implementation. Bridging is a feature that intercepts the consumer’s request and makes some processing, then forward to the service, doing a bridge between the client and the exposed backend system. Performance is about improving the solution’s response time. Security provides mechanisms to disable unauthorized access, avoiding potential attackers. Quality of Services is related to service level agreement (SLA). And Operational features are those useful in runtime operations and troubleshooting.
Mulesoft Anypoint, which is a comprehensive integration platform, implements some of these features using what they call “policies,” implemented with their API proxies. They do not call API Gateway, but API proxies and the deployment model are slightly different from what is exposed here. For further information, follow up on Anypoint documentation, available at [3].
The edge functions with their specific category can be seen in Figure 5 below. The categorized details of edge functions will be described in the following subsections.
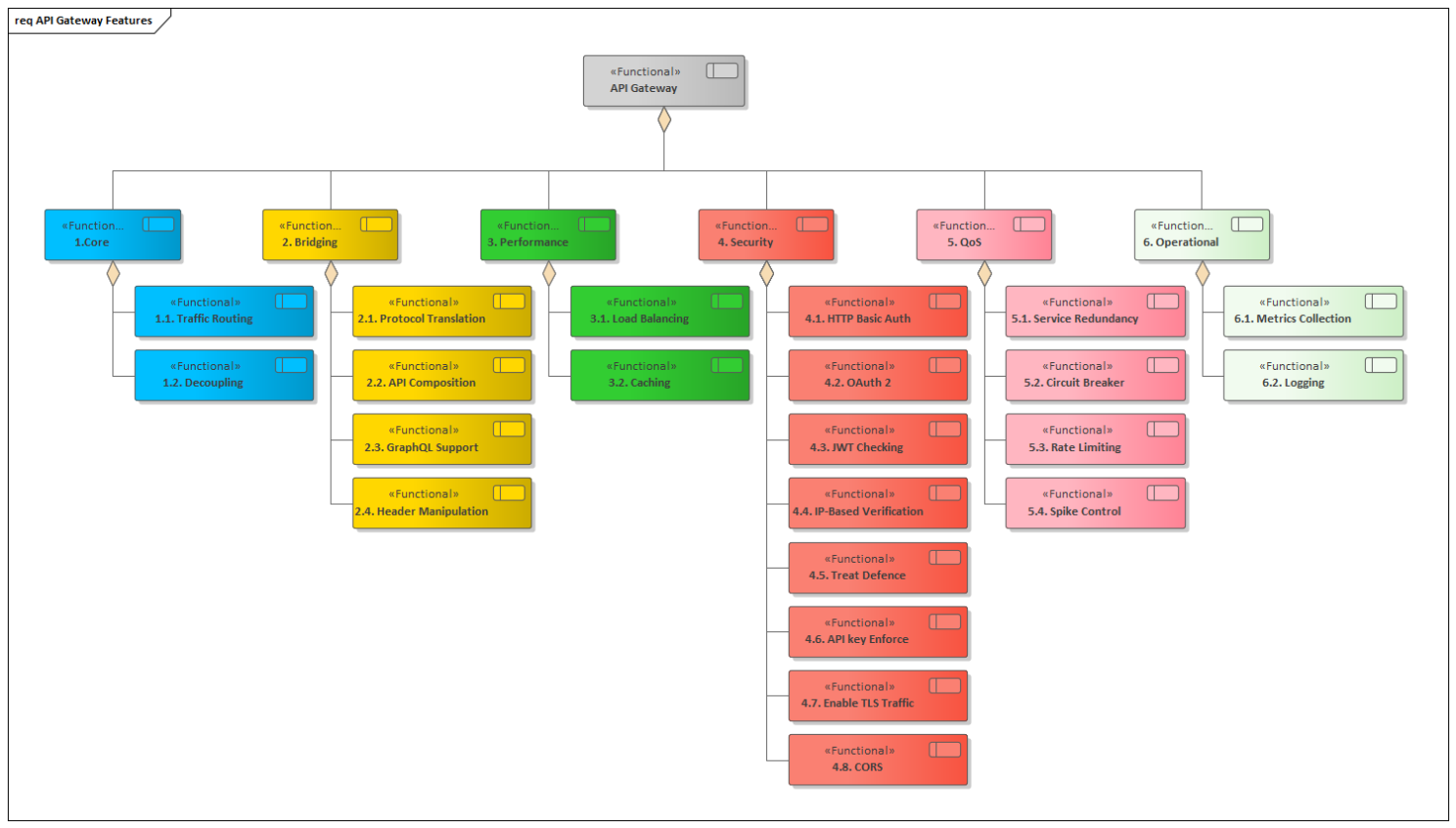
Figure 5: Edge Functions
Traffic Routing
As exposed in section 2.2, traffic routing is a mandatory function to be implemented by an API Gateway. It is the same functionality found on reverse proxy solutions, which does a mapping between endpoints to be requested and endpoints to be forwarded for each specific request endpoint.
Decoupling
As elaborated in section 2, decoupling the “big ball of mud” is a crucial point to match the fast-paced changes in the global market. The API gateway is a core player in that direction of having the backend system entirely exposed to be consumed safely by different clients. Decoupling is one of the most important responsibilities of an API Gateway. The gateway now specializes and alleviates other middleware nodes of functions that are studied in this very section.
Protocol Translation
A gateway, in networking terminology, is a piece of software able to translate between different protocols. The API Gateway specifically works in layer 7 of the open systems interconnection (OSI) reference model using HTTP, commonly RESTful APIs, to expose interfaces to backend systems to the external public Internet and internally can deal with different protocols such as REST (the same as the gateway exposed interface), gRPC, WebSocket, JMS (in asynchronous use cases), AMQP, SOAP, and others.
API Composition
The API Composition Pattern is the result of the creation of a Façade. Where the API Gateway, which implements the Façade, receives a remote request for coarse-grained data from clients, then brings the business data from different services in the adjacent layer composing the responses and returning the response all at once, instead of the client directly accessing those services, performing many fine-grained requests to those services in the backend.
When using an API gateway to perform the API composition, the network delay will be reduced since the Internet traffic from the client to the API Gateway, which is the bigger delay contributor, will be computed only once instead of a direct proportion of the number of services involved in a specific business process.
GraphQL Support
GraphQL is a query language used on APIs that provides flexibility for clients to select the appropriate information from the backend systems, which means the right information in the right size. The GraphQL support as an API Gateway feature is an important point since it will provide an implementation of the Backend for Frontend pattern [5], making it possible for the client to take the exact amount of information they need and can afford. Imagine it as a SQL query in that you can select only the fields and tables you need. GraphQL works similarly by selecting JSON attributes the client wants to bring as a response to his queries reducing the payload and, consequently, the memory and CPU utilization on the client side. For a deep dive into GraphQL access [6].
Header Manipulation
Header manipulation includes changing status code and header manipulation at the API Gateway level. It is useful in specific scenarios where the HTTP header data needs to be included or removed to satisfy API consumers or middleware services, sometimes for authentication and/or authorization reasons.
Load Balancing
The API Gateway, because of its strategic position in the architecture, is a potential spot to improve the system’s scalability when used as a load balancer to the underlying service layer nodes.
Keeping track of the instances of the nodes in a list with their maximum capacity, the gateway would be able to promote auto-scaling, scaling out new instances when necessary, and also scaling in terminating unused nodes. Despite that the load balancing function is normally done in dedicated load balancers such as Amazon Elastic Load Balancing Services (ELB), there is a possibility to implement it in the API Gateway reducing the hops needed to reach the service’s nodes.
Caching
Caching is used in API queries to store responses into fast memories, locally or in distributed nodes. Then, on the next calls with the same query, use these cached data for a response instead of a new round trip to the backend systems. It reduces the amount of backend round trips from the gateway to all the down-streaming services. This feature increases the overall performance tremendously because it eventually reduces not only the interaction with many services in the middleware but also applications and databases in the backend.
HTTP Basic Authentication
Basic Authentication is a popular mechanism for a client to provide credentials for authentication in HTTP protocol. It uses the Authorization HTTP header and the user ID and password encoded on it. This mechanism has been used since the beginning of Internet utilization. For further information, see: [6]. The HTTP Basic Authentication also can be used to send client IDs and client secrets to be used on OAuth 2 security, described later.
OAuth 2.0 Authentication and Authorization
This is an extensively used function that enables secure API client checking by using OAuth 2.0 which is an open standard for authorization and authorization. For more details about this standard see [8].
JWT Checking
This feature obligates the API gateway to verify the existence of a Bearer token in the inbound request’s authorization header. After finding it, it will validate the token with an identity provider, then propagate the principal’s role in the JWT token’s claim.
IP-Based Verification
IP whitelist and IP blacklist are powerful tools in defense against attacks. It allows control of which host in an IP network can access a specific endpoint or the entire node. On one hand, the whitelist is a list of IP addresses allowed access to the service; on another hand, you can have a blacklist disallowing access.
Treat Defense
Whist the IP-based verification, presented in the last subsection, is a significant defense at the networking level (OSI layer 3), the Threat Defense is another applies at the application level (OSI layer 7). The Treat Defense function can protect XML- or JSON-based applications matching patterns expected at the application level, avoiding oversized, malicious, and out-of-expected payloads.
API Key Enforcement
That edge function allows sending authentication API Key and secret credentials in different ways for different use cases: as query parameters, custom headers, or standard Authorization header as a Basic Authentication (see section 3.9). That feature is important to manage different devices and use cases that, for instance, are not able to send a POST with data in the payload, instead they need to send a GET and use query parameters to provide credentials (it is highly not recommended to pass the secret as a query parameter).
Enable TLS Traffic
Securing the communication channel with encryption using TLS is a common pattern in any computing services used today. So, the gateway would be capable to implement simple TLS and should have the ability to implement mutual authentication. TLS provides node authentication, confidentiality, and integrity of the communication channel.
Cross-Origin Resource Sharing (CORS)
CORS is an access control feature that enables the gateway to allow traffic only for specified origin domains. This control is performed normally on web browser’s-based applications using the Origin request header, where it must match the configured origin domain. For further information regarding CORS see [9].
Service Redundancy
A pattern called Health Check can be implemented in the API Gateway to provide higher availability, increasing the system's resilience. It is performed keeping a list of nodes, as proposed in the last subsection, with periodic health checks to the nodes. It will enable the API Gateway to route traffic only for healthy nodes. This provides a powerful failover solution that could be provided by the gateways, significantly improving the quality of service (QoS).
The service redundancy can also be implemented using dynamic service discovery through a service discovery mechanism, such as the Netflix Eureka open-source project, which registers the nodes dynamically instead of having them on static configuration files. If you are interested in Eureka's implementation, see [10].
Circuit Breakers
Using Circuit Breaker pattern implementations to monitor nodes related to a customer request and avoiding catastrophic cascade failures across a specific customer request is essential for critical mission applications such as API integration layer and microservices (for more information regarding the Circuit Breaker pattern, see Martin Fowler’s website here [11]).
Because the API gateway is a fundamental component that works on the edge of the deployment infrastructure, it is an excellent place to have a Circuit Breaker in place. It will provide failure protection by implementing a map with remote calls as key and a list of backend services related to that remote call. Then it must monitor that list looking for failures and potential long round trips causing connection timeouts and, consequently, system rupture. When these ruptures are detected, the circuit breaker opens the circuit for the entire path, keeping it in that state until the service returns alive or responds faster. Additionally, a failover mechanism should be in place to reroute the traffic in case of failure keeping the system resiliently working.
Rate Limiting
The rate-limiting controls the data flow through the gateway, rejecting requests when a specified throughput is reached. That control is implemented through HTTP headers.
Spike Control
Spike control is like rate limiting, but instead of simply rejecting requests when the threshold is reached, it enqueues them, delaying and limiting their processing.
Metrics Collection
For some companies, which, for instance, charge their customers per API request calls, it is necessary to have a procedure for billing. Other companies need a mechanism to capture metrics for analytics. Therefore, metrics collection is an important feature in any gateway implementation.
Logging
Troubleshooting or auditing is of great importance, so creating logging and being able to perform the Log Aggregation pattern [12] to troubleshoot the distributed nodes in a system must be implemented for operation in all computing systems or platforms.
These are all edge functions covered in the research. The next section will see how these edge functions are implemented in one of the more prominent API Gateways in the market nowadays, the Amazon API Gateway.
Amazon API Gateway Implementation
The Amazon API Gateway is a managed service that implements the API Gateway pattern. It is used to expose backend systems or services through RESTful APIs. Being managed means the AWS is responsible to maintain the underlying infrastructure in a contracted quality of service. See Table 1 below. It presents the functions studied in the last section and exposes those that are implemented by the Amazon API Gateway:
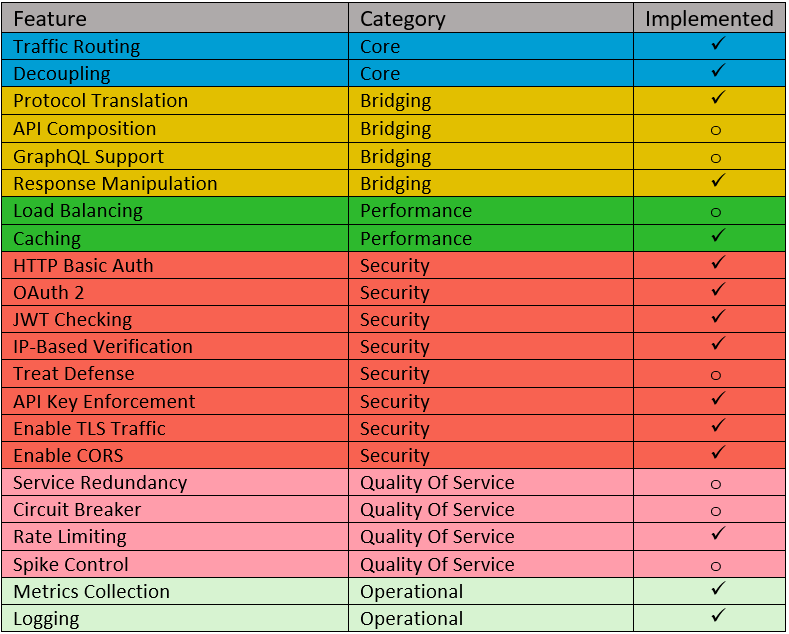
Table 1: Edge Functions Implemented on AWS API Gateway
The table shows the Amazon implementation implementing most of the presented edge functions, only seven functions are not implemented. From these seven, it has external services that cover the following: Load Balancing with Elastic Load Balancing, GraphQL support with AWS AppSync, and API Composition that can be deployed on AWS Lambdas.
Therefore, despite not being included in the AWS API Gateway, they provide three separate services to add such functionalities to it, which will then miss only the following four features: Treat Defense, Service Redundancy, Circuit Breaker, and Spike Control.
Conclusion
The API Gateway is of paramount importance to break down monolithic applications to expose the enterprise's internal business applications and cope with the current level of integration needed for them.
Researching the edge functions that potentially could be implemented by a modern API Gateway resulted in six categories with twenty-two features or edge functions covering the presently needed spectrum.
The Amazon API Gateway implementation covered about 68% of the edge functions, which can be considered a good amount regarding AWS decoupling their services into smaller pieces and offering them separately. In other words, they have covered many of the edge functions in other products instead of concentrating it all on the API Gateway. On the other hand, it has the drawback of having more distributed components performing the edge functions, where the most relevant problem is the increased latency brought by inter-services communication.
Bibliography
[1] S. Newman, Building Microservices: Designing Fine-Grained Systems, Sebastopol, California: O'Reilly Media, 2015.
[2] C. Richardson, "Microservices Architecture," [Online]. Available: https://microservices.io/patterns. [Accessed 20 June 2021].
[3] E. Gamma, R. Helm, J. Vlissides and G. Booch, "Design Patterns: Elements of Reusable Object-Oriented Software," Addison-Wesley Professional, 1994.
[4] M. LLC, "Mulesoft Anypoint Documentation," [Online]. Available: https://docs.mulesoft.com/api-manager/2.x/policies-ootb-landing-page. [Accessed 20 June 2021].
[5] C. Richardson, Microservices Patterns, Shelter Island, New York: Manning, 2018.
[6] GraphQL, "GraphQL Specification," [Online]. Available: https://graphql.org/learn. [Accessed 20 June 2021].
[7] IETF, "RFC7617," [Online]. Available: https://datatracker.ietf.org/doc/html/rfc7617. [Accessed 20 June 2020].
[8] "OAuth 2.0 Specification," [Online]. Available: https://oauth.net/2/. [Accessed 20 June 2021].
[9] Mozilla, "Cross Origin Resource Sharing," Mozilla Corporation, [Online]. Available: https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS. [Accessed 20 June 2021].
[10] I. Netflix, "Eureka Source Code," [Online]. Available: https://github.com/Netflix/eureka. [Accessed 20 June 2021].
[11] M. Fowler. [Online]. Available: https://martinfowler.com/bliki/CircuitBreaker.html. [Accessed 20 June 2020].
[12] C. Richardson, "Microservice Architecture," [Online]. Available: https://microservices.io/patterns/observability/application-logging.html. [Accessed 20 June 2021].
Published at DZone with permission of Rodrigo Dinis. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments