WildRydes (Serverless Web Application) With Terraform in AWS
Learn how to use S3, API gateways, AWS Lambda, and more to create and host a web application.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
AWS has a number of getting started projects. These projects provide a step-by-step approach to build the infrastructure and deploy applications on it. Every step refers to the AWS console with information on how to implement them and following the steps provides a very good familiarization to the console as well.
WildRydes is one of these projects and is a pretty good example of how to create a website using S3 and then using a backend serverless capability, i.e. Lambda, to process the requests and respond back to the user. For context, below is the application architecture which I have copied from AWS site for reference.
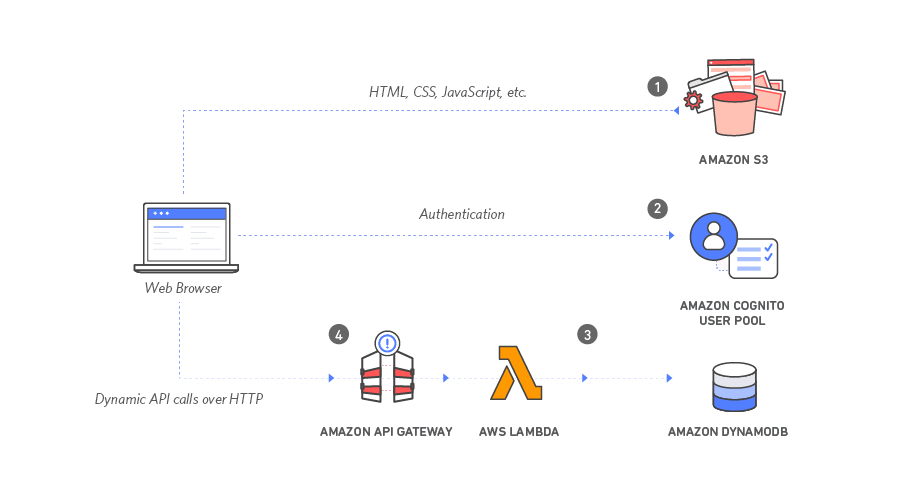
As you can see, there are a couple of AWS services used in the backend. The front-end is deployed on S3, Cognito is used for user management, and DynamoDB is used to record user requests for a unicorn. An API Gateway is used to expose the Lambda function over the internet which is then invoked by the front-end. The statically hosted website on S3 is turned into a dynamic web application by adding client-side JavaScript that makes AJAX calls to the exposed API.
In this tutorial, we will automate the steps provided using terraform. We will save the state of our infrastructure in an S3 bucket so you would need to have an S3 bucket available which can be configured as below.
terraform {
backend "s3" {
bucket = "<your_state_bucket>"
key = "dev-sandbox/wildrydes_terraform/terraform.tfstate"
region = "eu-west-2"
encrypt = true
dynamodb_table = "terraform"
}
}Note that implementing the modules may cost you money.
Module 1. Static Web Hosting
This module configures Amazon Simple Storage Service (S3) to host static resources for the web application. This requires us to use the "aws_s3_bucket" resource. A partial code snippet block is shown below.
resource "aws_s3_bucket" "wildrydes_s3_bucket" {
bucket = "${var.s3-bucket-name}"
acl = "public-read"
force_destroy = true
website {
index_document = "index.html"
error_document = "error.html"
}
....
....Module 2. User Management
Further, we will create an Amazon Cognito user pool to manage user accounts. This will also allow us to send a verification code to the registered email address that the user has entered during registration. The verification code can be used to authorize the user. Upon successful authorization, the user should be able to log in and request a unicorn.
We will need to use two resources:
- aws_cognito_user_pool: This will create a user pool for user management.
- aws_cognito_user_pool_client: This will create an app client in the pool.
#---------------------------------------------------------------------
# Cognito setup for user management
#---------------------------------------------------------------------
resource "aws_cognito_user_pool" "user_pool" {
name = "${var.cognito_user_pool}"
// Cognito will send the verification code to the registered email
auto_verified_attributes = ["email"]
}# --------------------------------------------------
# Create a App Client in the pool
# --------------------------------------------------
resource "aws_cognito_user_pool_client" "app_client" {
name = "${var.cognito_user_pool_client}"
user_pool_id = "${aws_cognito_user_pool.user_pool.id}"
generate_secret = false
}Module 3: Serverless Service Backend
In this module, we will implement a Lambda function that will be invoked when the user requests a unicorn. We will need a DynamoDB table to record the request.
To allow this interaction, we will also need to create an IAM role and attach appropriate policies. The IAM role will then need to be given to the authorizer which we will do in the next module.
We will need to use the following resources and configure them appropriately:
- aws_dynamodb_table: A DynamoDB table ("Rides") to record the user requests for a unicorn.
- aws_iam_role: An IAM role allowing a trust relationship to Lambda and the API Gateway to assume it.
- aws_iam_policy: Two IAM policies allowing Lambda access to CloudWatch and write access to DynamoDB.
- aws_iam_role_policy_attachment: This will be used to attach the two policies to the IAM role.
- aws_lambda_function: Finally, the lambda function. This resource will create a function and upload the function source code which is provided as a zip file (requestUnicorn.zip).
# --------------------------------------------------
# The Lambda Function
# --------------------------------------------------
resource "aws_lambda_function" "WildRydes_Lambda_Function" {
filename = "${var.lambda_function_filename}"
function_name = "${var.lambda_function_name}"
handler = "${var.lambda_handler}"
runtime = "${var.lambda_runtime}"
source_code_hash = "${base64sha256(file("${var.lambda_function_filename}"))}"
// execution role for lambda - Allow Lambda to execute
role = "${aws_iam_role.WildRydesLambda.arn}"
}Module 4. RESTful APIs
In this module, we will create a REST API with an endpoint, "/ride," that exposes the lambda function over the public internet. The access to the API is secured by using the Cognito user pool that we created earlier.
We also need to enable CORS while implementing the API. While creating this using the AWS console, it is just a checkbox that needs to be ticked. Behind the scenes, it creates an "OPTIONS" method with integration responses. We will create this using "aws_api_gateway_method" and implement a gateway integration response with response parameters.
We will use the following resources and configure them appropriately:
- aws_api_gateway_rest_api: The API Gateway for the WildRydes application.
- aws_api_gateway_authorizer: Authorizer for the API gateway which will use the Cognito user pool for authorization and IAM roles.
- aws_api_gateway_resource: This creates a "ride" resource within the API gateway.
- aws_api_gateway_method: This creates the POST and the OPTIONS (for CORS) method for the API gateway. For POST, authorization is set as "COGNITO_USER_POOLS" and for CORS this is set as "NONE."
- aws_api_gateway_integration: Creates an integration for the API gateway, resource, and the method. This is used for both POST (type = AWS_PROXY) and OPTIONS(type = MOCK).
- aws_api_gateway_integration_response, aws_api_gateway_method_response: This is used to set the response for CORS with appropriate response parameters.
- aws_lambda_permission: This resource is used to provide (by lambda) to give invoke permissions to the API gateway.
- aws_api_gateway_deployment: Finally, deploy the API to the "Test" stage.
After the above configuration has been completed, execute the following commands from inside the base directory:
$ terraform init
$ terraform plan
$ terraform applyAfter terraform apply, three outputs are returned:
Apply complete! Resources: 21 added, 0 changed, 0 destroyed.
Outputs:
lambda_base_url = https://1lcyeokpe6.execute-api.eu-west-2.amazonaws.com/Test
user_pool_client_id = 4mkt3h62iq79628019d7r41787
user_pool_id = eu-west-2_A4HfohzmLThe output values from this will need to be configured in "config.js" as shown below (wildrydes_terraform\src_webapp\js\config.js).
window._config = {
cognito: {
userPoolId: 'eu-west-2_A4HfohzmL',
userPoolClientId: '4mkt3h62iq79628019d7r41787',
region: 'eu-west-2'
},
api: {
invokeUrl: 'https://1lcyeokpe6.execute-api.eu-west-2.amazonaws.com/Test'
}
};Once this has been done, upload the code from the "src_webapp" folder to the S3 bucket defined in the variables_input.tf file. Make sure the contents of the folder are uploaded (not the actual folder src_webapp)
You can drag and drop the contents into the S3 bucket using the AWS console.
variable "s3-bucket-name" {
default = "wildrydes-s3-bucket"
}WidlRydes should now be functional and available, and, of course, the URL will be dependent on the bucket name and the region.
http://wildrydes-s3-bucket.s3-website.eu-west-2.amazonaws.com/Module 5. Resource Cleanup
Terminating resources should be easy by just executing the below command:
$ terraform destroyThe complete code is available on GitHub here.
Further Automation
There are two steps above that we still need to do manually and can be automated. There could be multiple ways this can be done. One of the ways is specified below.
- Update config.js with the output values from
terraform apply- the "local_file" terraform resource can be used to generate the config.js whenever anapplyis done followed by upload of the config to S3 bucket. - Upload the front-end website code to S3 either by drag/drop or the AWS CLI - Use an orchestrator such as Jenkins and upload using the AWS CLI defined in one of the pipeline steps.
Using a Jenkins pipeline, the apply, config, and upload steps can be fully automated to create a CI/CD pipeline.
Considerations
I have tried to map the module steps from the AWS project to terraform resources. This approach creates four individual .tf files with very less reusability.
The project can be further enhanced by creating reusable terraform modules. I can see two different modules that can be created — a module that encapsulates the API gateway with a lambda function and another one to enable CORS. This is out of scope for this tutorial.
I hope this tutorial helps anybody trying to learn AWS, serverless computing, and terraform.
Let me know in the comments. Happy terraforming!
Opinions expressed by DZone contributors are their own.
Comments