Apache Flink 101: A Guide for Developers
Learn more about Apache Flink, a powerful stream processing tool, for building streaming data pipelines, real-time analytics, and event-driven applications.
Join the DZone community and get the full member experience.
Join For FreeIn recent years, Apache Flink has established itself as the de facto standard for real-time stream processing. Stream processing is a paradigm for system building that treats event streams (sequences of events in time) as its most essential building block. A stream processor, such as Flink, consumes input streams produced by event sources and produces output streams that are consumed by sinks (the sinks store results and make them available for further processing).
Household names like Amazon, Netflix, and Uber rely on Flink to power data pipelines running at tremendous scale at the heart of their businesses, but Flink also plays a key role in many smaller companies with similar requirements for being able to react quickly to critical business events.
What is Flink being used for? Common use cases fall into these three categories:
|
Streaming data pipelines |
Real-time analytics |
Event-driven applications |
|---|---|---|
|
Continuously ingest, enrich, and transform data streams, loading them into destination systems for timely action (vs. batch processing). |
Continuously produce and update results which are displayed and delivered to users as real-time data streams are consumed. |
Recognize patterns and react to incoming events by triggering computations, state updates, or external actions. |
|
Some examples include:
|
Some examples include:
|
Some examples include:
|
Flink includes:
- Robust support for data streaming workloads at the scale needed by global enterprises
- Strong guarantees of exactly-once correctness and failure recovery
- Support for Java, Python, and SQL, with unified support for both batch and stream processing
- Flink is a mature open-source project from the Apache Software Foundation and has a very active and supportive community.
Flink is sometimes described as being complex and difficult to learn. Yes, the implementation of Flink’s runtime is complex, but that shouldn’t be surprising, as it solves some difficult problems. Flink APIs can be somewhat challenging to learn, but this has more to do with the concepts and organizing principles being unfamiliar than with any inherent complexity.
Flink may be different from anything you’ve used before, but in many respects, it’s actually rather simple. At some point, as you become more familiar with the way that Flink is put together, and the issues that its runtime must address, the details of Flink’s APIs should begin to strike you as being the obvious consequences of a few key principles, rather than a collection of arcane details you should memorize.
This article aims to make the Flink learning journey much easier, by laying out the core principles underlying its design.
Flink Embodies a Few Big Ideas
Streams
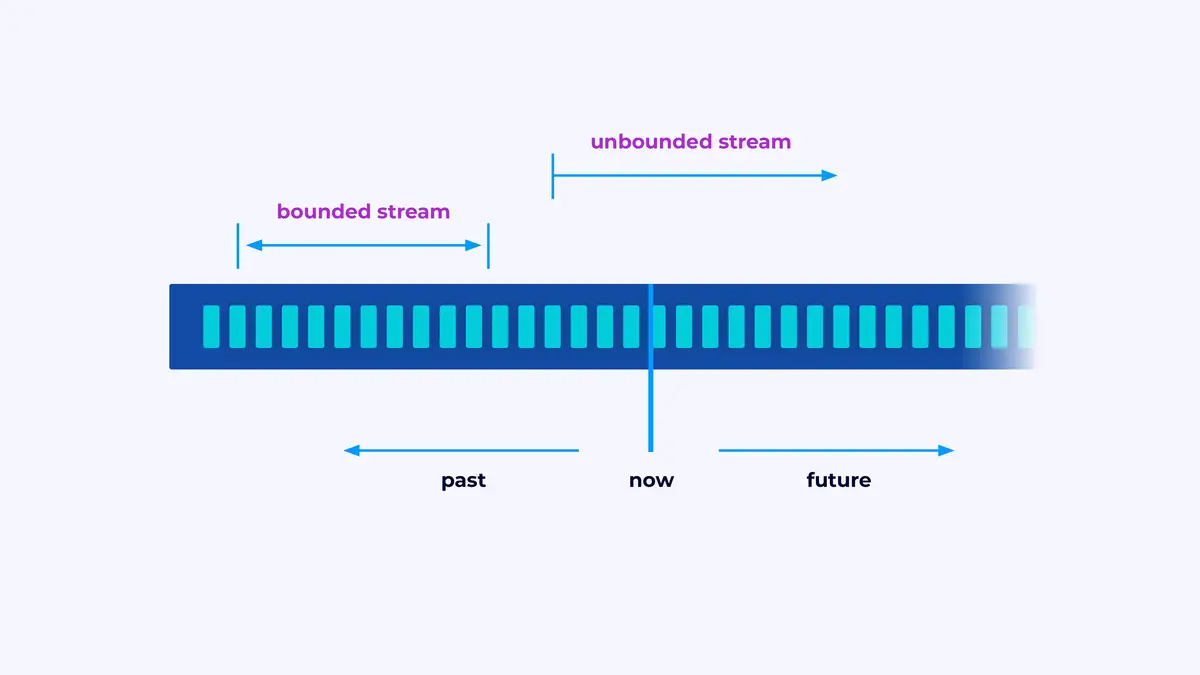
Flink is a framework for building applications that process event streams, where a stream is a bounded or unbounded sequence of events.
A Flink application is a data processing pipeline. Your events flow through this pipeline and are operated on at each stage by the code you write. We call this pipeline the job graph, and the nodes of this graph (or in other words, the stages of the processing pipeline) are called operators.
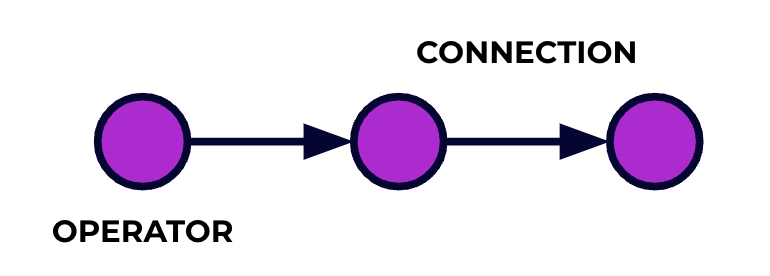
The code you write using one of Flink's APIs describes the job graph, including the behavior of the operators and their connections.
Parallel Processing
Each operator can have many parallel instances, each operating independently on some subset of the events.
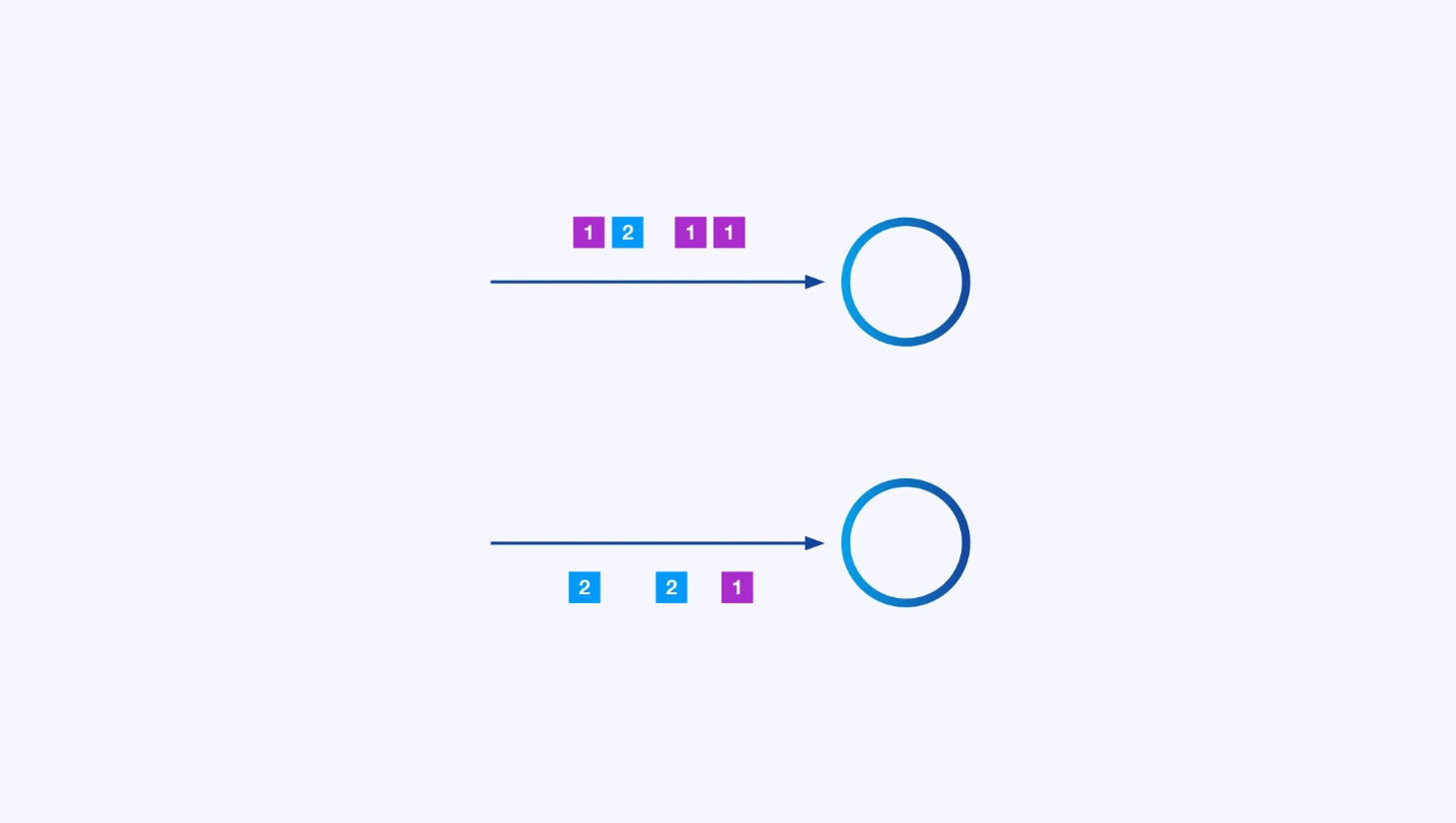
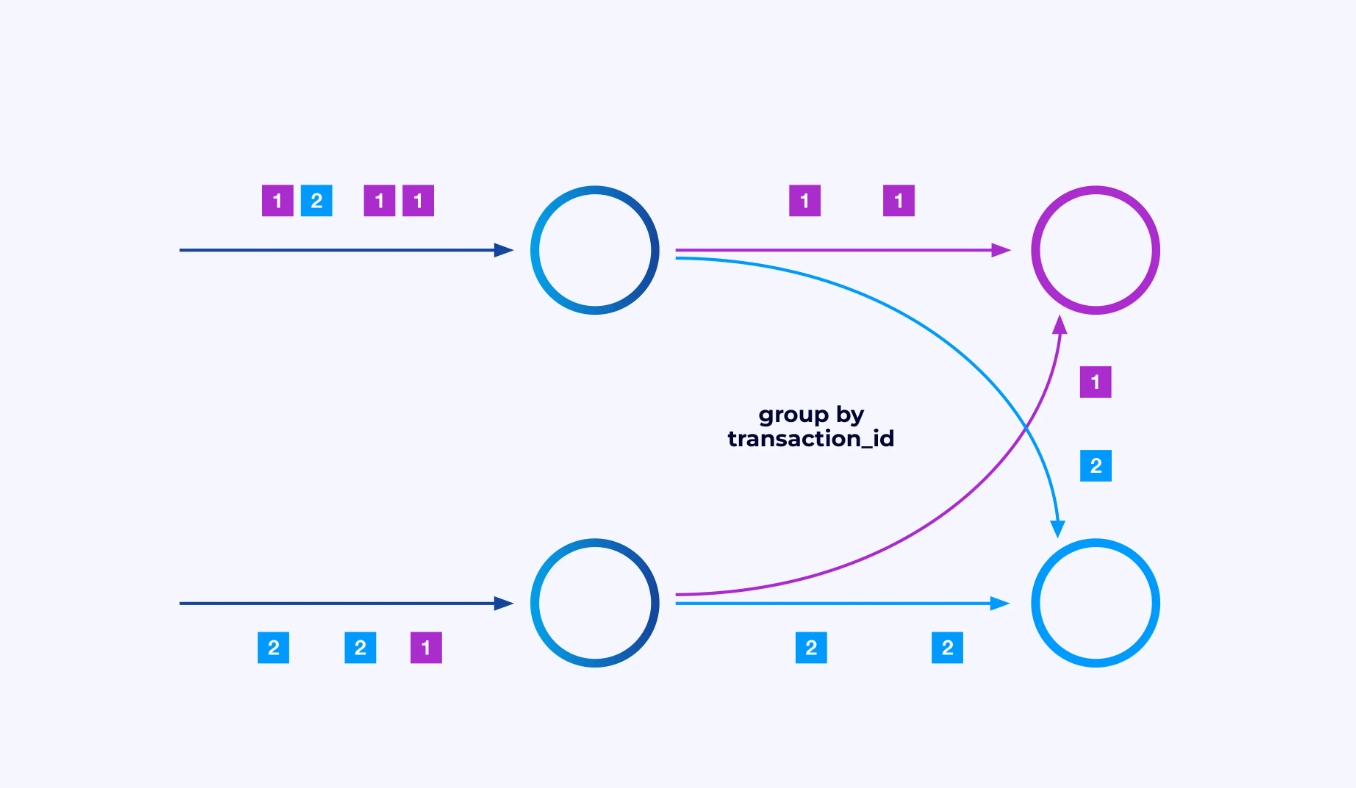
Sometimes you will want to impose a specific partitioning scheme on these sub-streams so that the events are grouped together according to some application-specific logic. For example, if you’re processing financial transactions, you might need to arrange for every event for any given transaction to be processed by the same thread. This will allow you to connect together the various events that occur over time for each transaction
In Flink SQL, you would do this with GROUP BY transaction_id, while in the DataStream API you would use keyBy(event -> event.transaction_id) to specify this grouping or partitioning. In either case, this will show up in the job graph as a fully connected network shuffle between two consecutive stages of the graph.
State
Operators working on key-partitioned streams can use Flink's distributed key/value state store to durably persist whatever they want. The state for each key is local to a specific instance of an operator, and cannot be accessed from anywhere else. The parallel sub-topologies share nothing — this is crucial for unrestrained scalability.
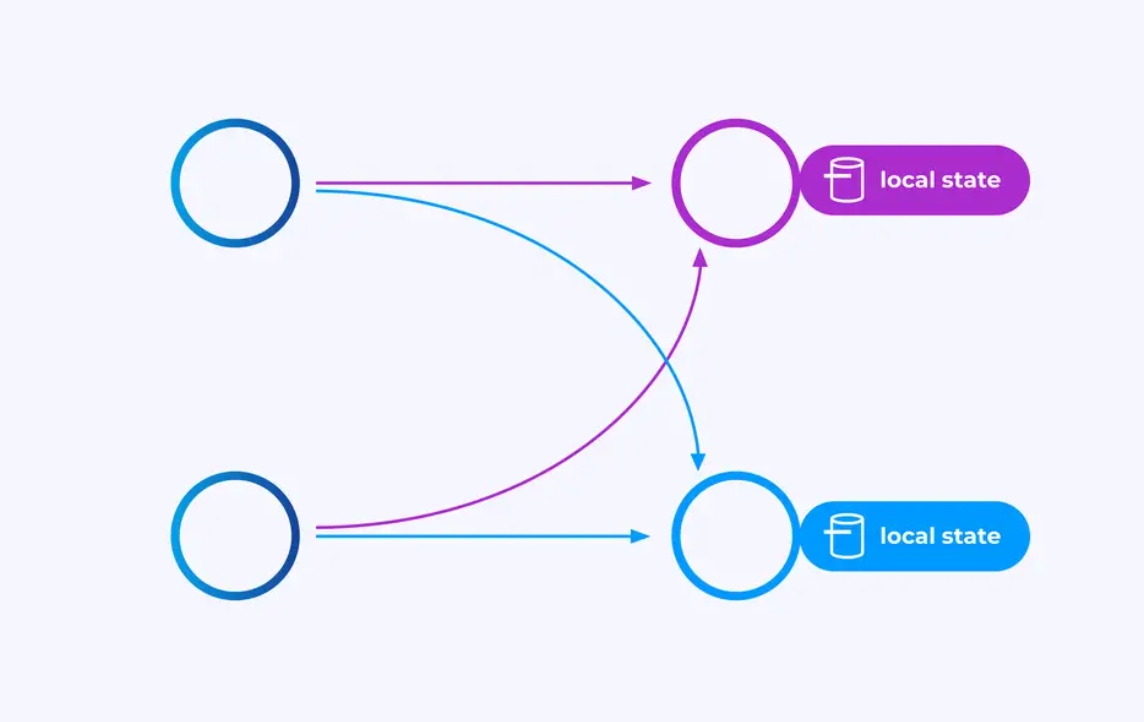
A Flink job might be left running indefinitely. If a Flink job is continuously creating new keys (e.g., transaction IDs) and storing something for each new key, then that job risks blowing up because it is using an unbounded amount of state. Each of Flink's APIs is organized around providing ways to help you avoid runaway explosions of state.
Time
One way to avoid hanging onto a state for too long is to retain it only until some specific point in time. For instance, if you want to count transactions in minute-long windows, once each minute is over, the result for that minute can be produced, and that counter can be freed.
Flink makes an important distinction between two different notions of time:
- Processing (or wall clock) time, which is derived from the actual time of day when an event is being processed
- Event time, which is based on timestamps recorded with each event
To illustrate the difference between them, consider what it means for a minute-long window to be complete:
- A processing time window is complete when the minute is over. This is perfectly straightforward.
- An event time window is complete when all events that occurred during that minute have been processed. This can be tricky since Flink can’t know anything about events it hasn’t processed yet. The best we can do is to make an assumption about how out-of-order a stream might be and apply that assumption heuristically.
Checkpointing for Failure Recovery
Failures are inevitable. Despite failures, Flink is able to provide effectively exactly-once guarantees, meaning that each event will affect the state Flink is managing exactly once, just as though the failure never occurred. It does this by taking periodic, global, self-consistent snapshots of all the states. These snapshots, created and managed automatically by Flink, are called checkpoints.
Recovery involves rolling back to the state captured in the most recent checkpoint and performing a global restart of all of the operators from that checkpoint. During recovery, some events are reprocessed, but Flink is able to guarantee correctness by ensuring that each checkpoint is a global, self-consistent snapshot of the complete state of the system.
System Architecture
Flink applications run in Flink clusters, so before you can put a Flink application into production, you’ll need a cluster to deploy it to. Fortunately, during development and testing it’s easy to get started by running Flink locally in an integrated development environment (IDE) like IntelliJ or Docker.
A Flink cluster has two kinds of components: a Job Manager and a set of Task Managers. The task managers run your application(s) (in parallel), while the job manager acts as a gateway between the task managers and the outside world. Applications are submitted to the job manager, which manages the resources provided by the task managers, coordinates checkpointing, and provides visibility into the cluster in the form of metrics.
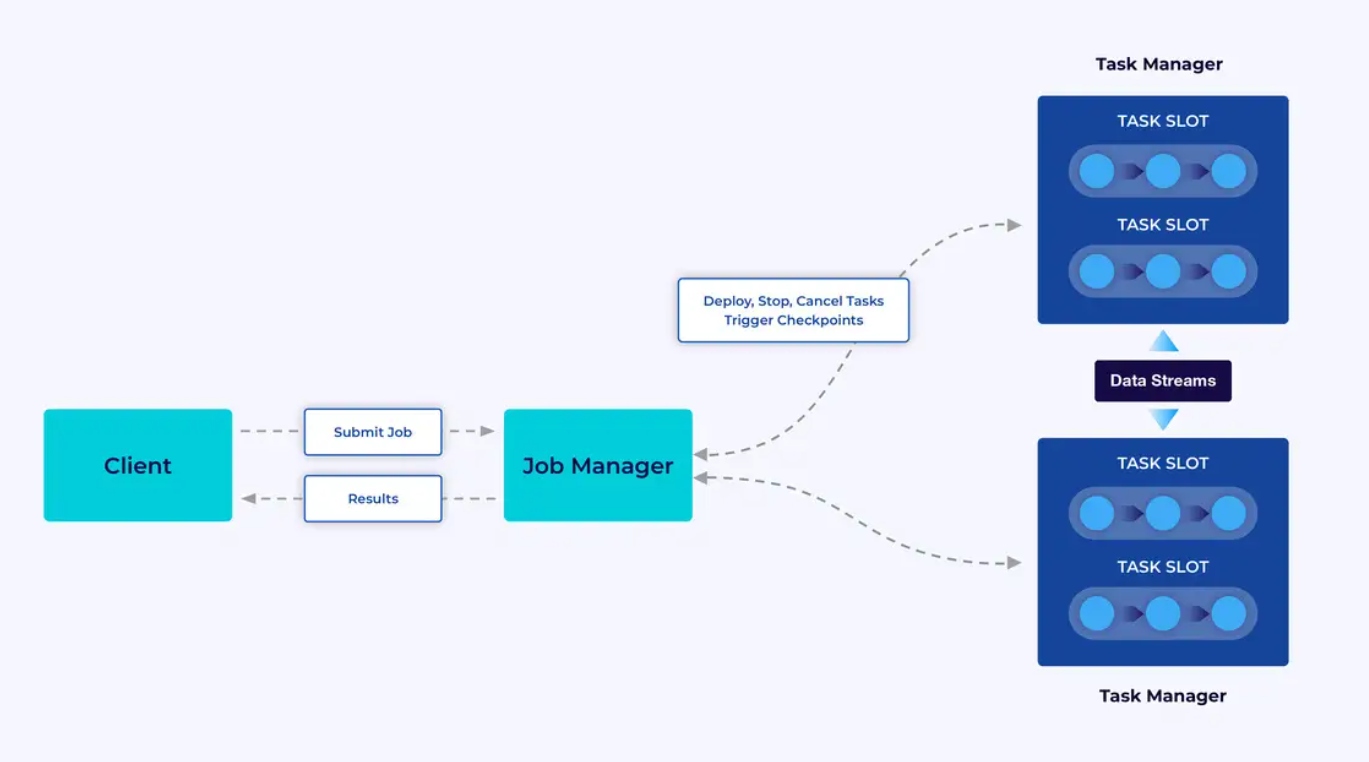
The Developer Experience
The experience you’ll have as a Flink developer depends, to a certain extent, on which of the APIs you choose: either the older, lower-level DataStream API or the newer, relational Table and SQL APIs.
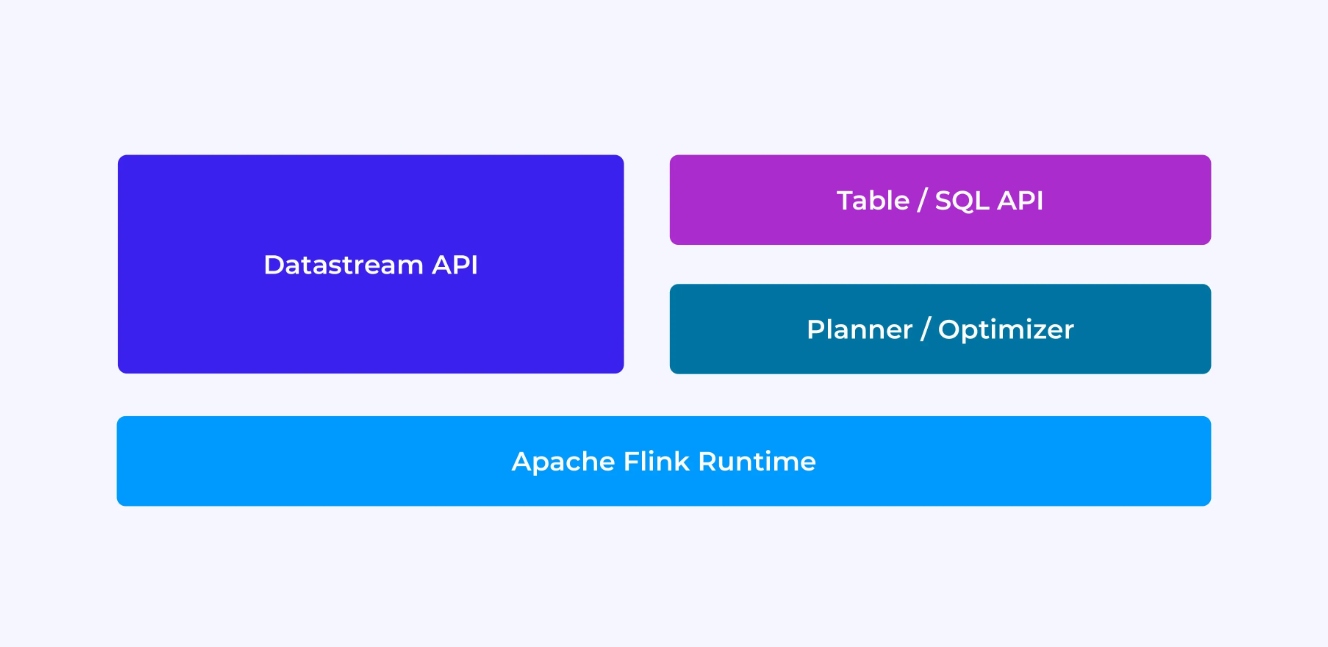
When you are programming with Flink’s DataStream API, you are consciously thinking about what the Flink runtime will be doing as it runs your application. This means that you are building up the job graph one operator at a time, describing the state you are using along with the types involved and their serialization, creating timers, and implementing callback functions to be executed when those timers are triggered, etc. The core abstraction in the DataStream API is the event, and the functions you write will be handling one event at a time, as they arrive.
On the other hand, when you use Flink’s Table/SQL API, these low-level concerns are taken care of for you, and you can focus more directly on your business logic. The core abstraction is the table, and you are thinking more in terms of joining tables for enrichment, grouping rows together to compute aggregated analytics, etc. A built-in SQL query planner and optimizer take care of the details. The planner/optimizer does an excellent job of managing resources efficiently, often outperforming hand-written code.
A couple more thoughts before diving into the details: first, you don’t have to choose the DataStream or the Table/SQL API – both APIs are interoperable, and you can combine them. That can be a good way to go if you need a bit of customization that isn’t possible in the Table/SQL API. But another good way to go beyond what Table/SQL API offers out of the box is to add some additional capabilities in the form of user-defined functions (UDFs). Here, Flink SQL offers a lot of options for extension.
Constructing the Job Graph
Regardless of which API you use, the ultimate purpose of the code you write is to construct the job graph that Flink’s runtime will execute on your behalf. This means that these APIs are organized around creating operators and specifying both their behavior and their connections to one another. With the DataStream API, you are directly constructing the job graph, while with the Table/SQL API, Flink’s SQL planner is taking care of this.
Serializing Functions and Data
Ultimately, the code you supply to Flink will be executed in parallel by the workers (the task managers) in a Flink cluster. To make this happen, the function objects you create are serialized and sent to the task managers where they are executed. Similarly, the events themselves will sometimes need to be serialized and sent across the network from one task manager to another. Again, with the Table/SQL API you don’t have to think about this.
Managing State
The Flink runtime needs to be made aware of any state that you expect it to recover for you in the event of a failure. To make this work, Flink needs type information it can use to serialize and deserialize these objects (so they can be written into, and read from, checkpoints). You can optionally configure this managed state with time-to-live descriptors that Flink will then use to automatically expire the state once it has outlived its usefulness.
With the DataStream API, you generally end up directly managing the state your application needs (the built-in window operations are the one exception to this). On the other hand, with the Table/SQL API, this concern is abstracted away. For example, given a query like the one below, you know that somewhere in the Flink runtime some data structure has to maintain a counter for each URL, but the details are all taken care of for you.
SELECT url, COUNT(*)
FROM pageviews
GROUP BY URL;Setting and Triggering Timers
Timers have many uses in stream processing. For example, it is common for Flink applications to need to gather information from many different event sources before eventually producing results. Timers work well for cases where it makes sense to wait (but not indefinitely) for data that may (or may not) eventually arrive.
Timers are also essential for implementing time-based windowing operations. Both the DataStream and Table/SQL APIs have built-in support for Windows and are creating and managing timers on your behalf.
Use Cases
Circling back to the three broad categories of streaming use cases introduced at the beginning of this article, let’s see how they map to what you’ve just been learning about Flink.
Streaming Data Pipeline
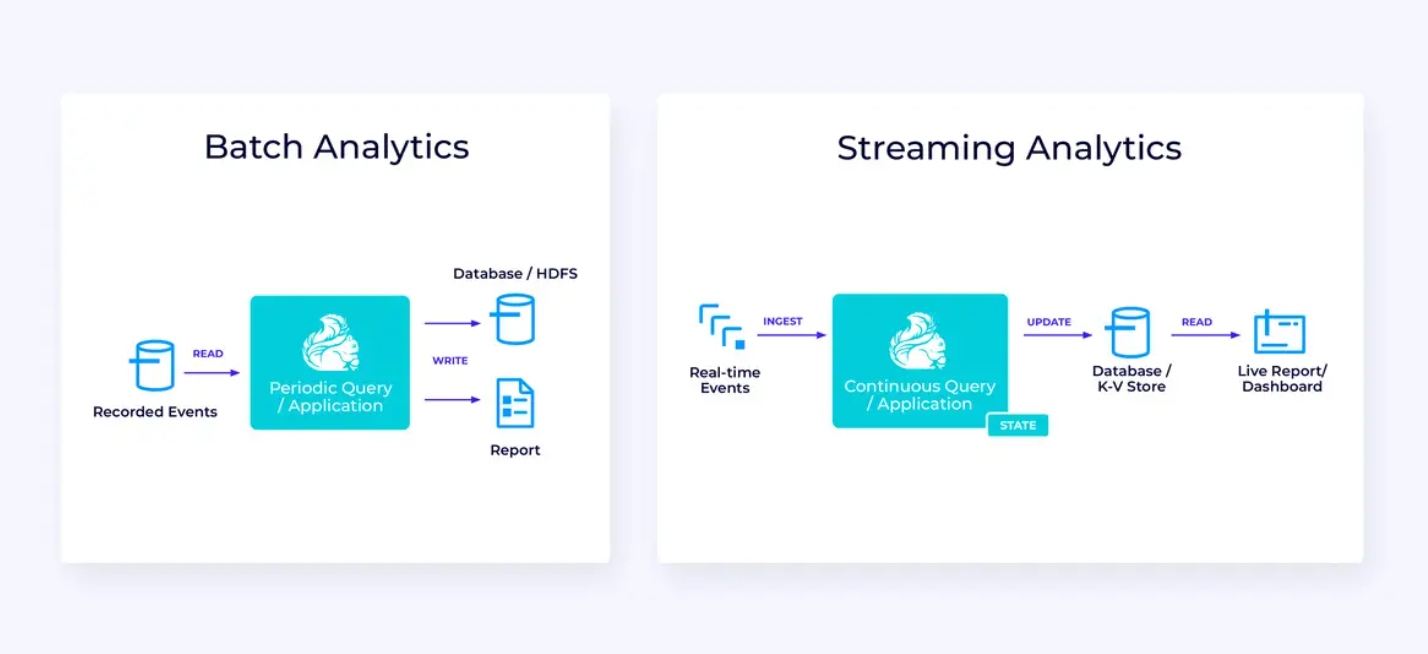
Below, at left, is an example of a traditional batch extract, transform, and load (ETL) job that periodically reads from a transactional database, transforms the data, and writes the results out to another data store, such as a database, file system, or data lake.
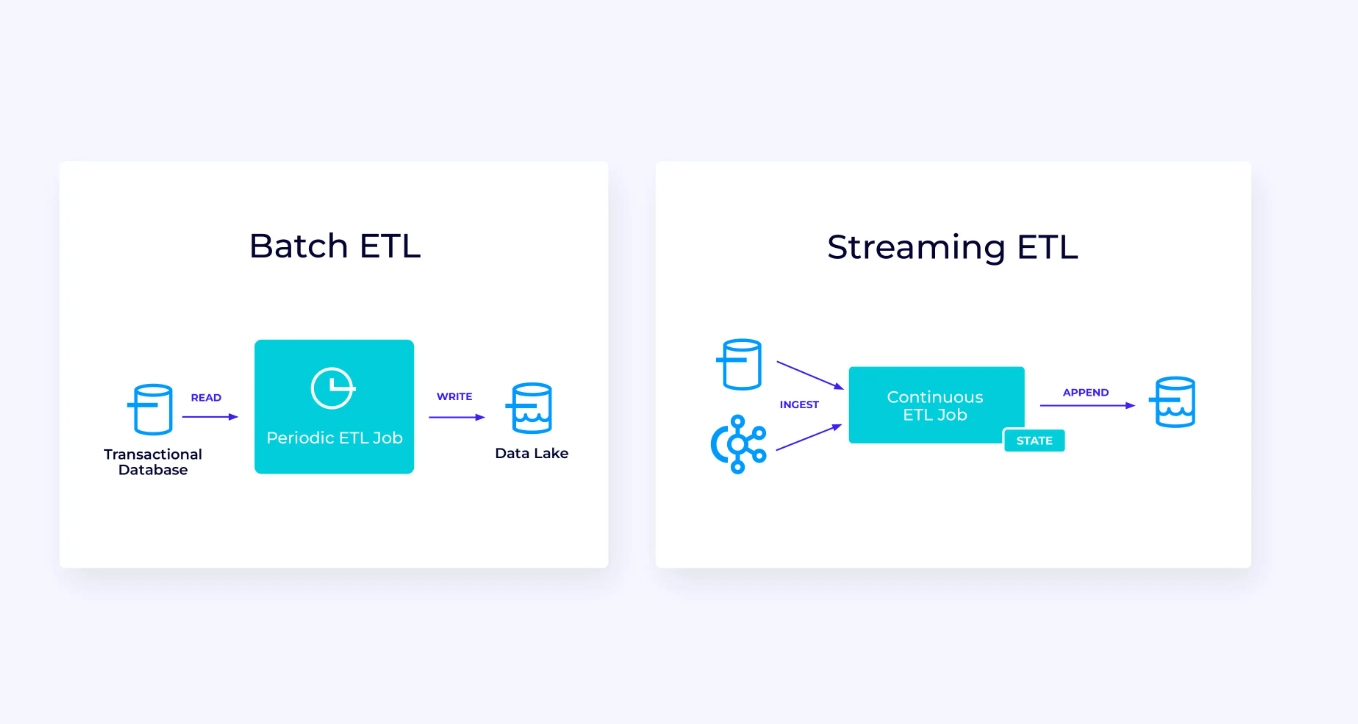
The corresponding streaming pipeline is superficially similar, but has some significant differences:
- The streaming pipeline is always running.
- The transactional data is delivered to the streaming pipeline in two parts: an initial bulk load from the database, in combination with a change data capture (CDC) stream carrying the database updates since that bulk load.
- The streaming version continuously produces new results as soon as they become available.
- The state is explicitly managed so that it can be robustly recovered in the event of a failure. Streaming ETL pipelines typically use very little state. The data sources keep track of exactly how much of the input has been ingested, typically in the form of offsets that count records since the beginning of the streams. The sinks use transactions to manage their writes to external systems, like databases or Kafka. During checkpointing, the sources record their offsets, and the sinks commit the transactions that carry the results of having read exactly up to, but not beyond, those source offsets.
For this use case, the Table/SQL API would be a good choice.
Real-Time Analytics
Compared to the streaming ETL application, this streaming analytics application has a couple of interesting differences:
- Once again, Flink is being used to run a continuous application, but for this application, Flink will probably need to manage substantially more state.
- For this use case, it makes sense for the stream being ingested to be stored in a stream-native storage system, such as Apache Kafka.
- Rather than periodically producing a static report, the streaming version can be used to drive a live dashboard.
Once again, the Table/SQL API is usually a good choice for this use case.
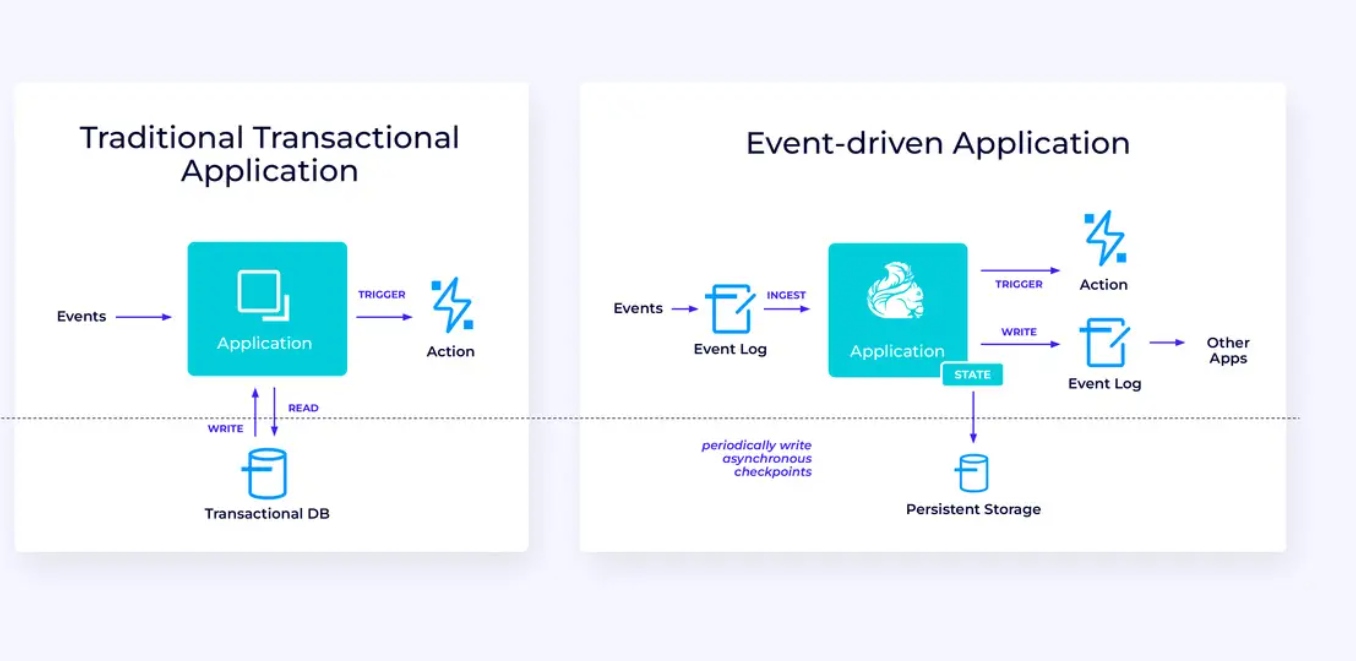
Event-Driven Applications
Our third and final family of use cases involves the implementation of event-driven applications or microservices. Much has been written elsewhere on this topic; this is an architectural design pattern that has a lot of benefits.
Flink can be a great fit for these applications, especially if you need the kind of performance Flink can deliver. In some cases, the Table/SQL API has everything you need, but in many cases, you’ll need the additional flexibility of the DataStream API for at least part of the job.
Getting Started With Flink
Flink provides a powerful framework for building applications that process event streams. As we have covered, some of the concepts may seem novel at first, but once you’re familiar with the way Flink is designed and operates, the software is intuitive to use, and the rewards of knowing Flink are significant.
As a next step, follow the instructions in the Flink documentation, which will guide you through the process of downloading, installing, and running the latest stable version of Flink. Think about the broad use cases we discussed — modern data pipelines, real-time analytics, and event-driven microservices — and how these can help to address a challenge or drive value for your organization.
Data streaming is one of the most exciting areas of enterprise technology today, and stream processing with Flink makes it even more powerful. Learning Flink will be beneficial not only for your organization but also for your career because real-time data processing is becoming more valuable to businesses globally. So check out Flink today and see what this powerful technology can help you achieve.
Published at DZone with permission of David Anderson. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments