Running Streaming ETL Pipelines with Apache Flink on Zeppelin Notebooks
A step-by-step tutorial for running Streaming ETL with Flink on Zeppelin. Let's dive deeper into the Flink interpreter in Zeppelin Notebooks.
Join the DZone community and get the full member experience.
Join For FreeApache Zeppelin 0.9 comes with a redesigned interpreter for Apache Flink that allows developers and data engineers to use Flink directly on Zeppelin notebooks for interactive data analysis. Over the next paragraphs, we describe why Streaming ETL is a great fit for stream processing frameworks like Apache Flink and we dive deeper into the Flink interpreter in Zeppelin Notebooks by showcasing a tutorial of how developers can run Streaming ETL data pipelines with Flink on Zeppelin.

Streaming ETL and Apache Flink
Extract-transform-load (ETL) is a common operation related to massaging and moving data between storage systems. ETL jobs have historically been triggered periodically, frequently copying data from transactional database systems to an analytical database or a data warehouse.
Streaming ETL pipelines serve a similar purpose traditional ETL: they transform and enrich data and can move it from one storage system to another. However, streaming ETL pipelines are different from traditional ETL in that they operate continuously and are capable of both reading records from sources that continuously produce data as well as moving the data, with low latency, to their desired destination.
Streaming ETL is a common use case for Apache Flink because of its ability to address most common data transformation or enrichment tasks with Flink SQL (or Table API) and its support for user-defined functions. Additionally, Flink provides a rich set of connectors to various storage systems such as Kafka, Kinesis, Elasticsearch, and JDBC database systems. It also features continuous sources for file systems that monitor directories and sinks and write files in a time-bucketed fashion. Let us now describe how the Flink interpreter works in Zeppelin notebooks.
The Flink Interpreter in Zeppelin 0.9
The Flink interpreter can be accessed and configured from Zeppelin’s interpreter settings page. The interpreter has been refactored so that Flink users can now take advantage of Zeppelin to write Flink applications in three languages, namely Scala, Python (PyFlink), and SQL (for both batch & streaming executions). Zeppelin 0.9 now comes with the Flink interpreter group, consisting of the below five interpreters:
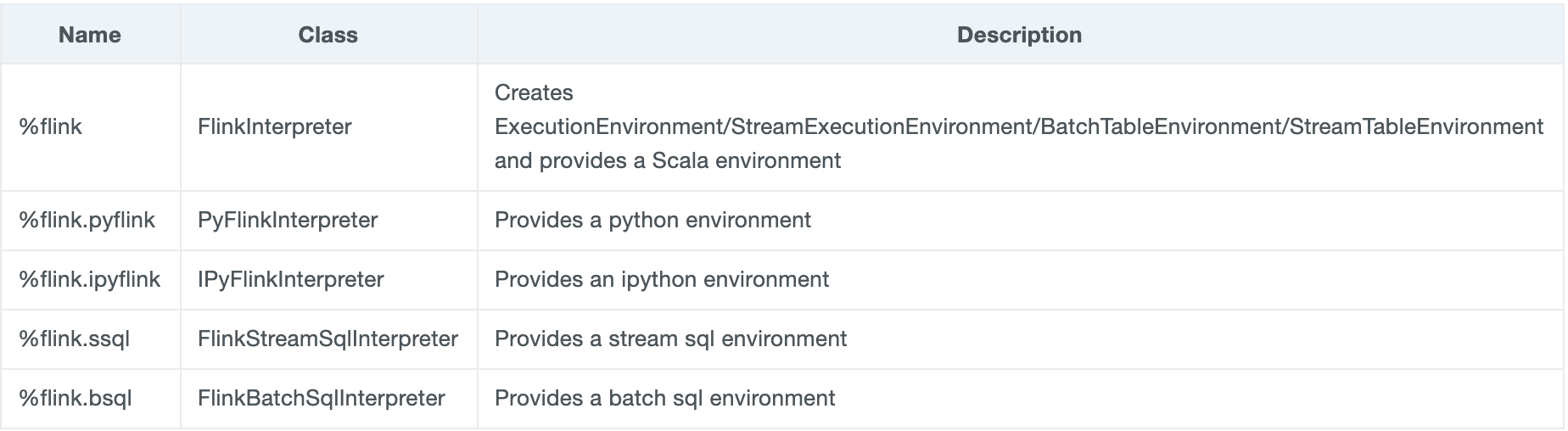
The Flink interpreter has been brought to a new level and now provides support for both writing Flink applications in three languages (Scala, Python [PyFlink] and SQL) as well as running such applications in different execution modes, such as running Flink in Local, remote or Yarn Mode. if you are interested in learning more about the Flink interpreter and for more information on how to get started with Zeppelin and all the execution modes for Flink applications you can check this article.
Flink on Zeppelin for Stream ETL pipelines
The Flink interpreter allows developers to build stream processing Flink applications, such as streaming ETL and real-time data analytics directly on Zeppelin Notebooks. This can be easily executed by taking advantage of Flink SQL along with specific UDFs (user-defined functions). Let us now showcase how you can execute streaming ETL using Flink on Zeppelin:
You can use Flink SQL to perform streaming ETL by following the steps below (for the full tutorial, please refer to the Flink Tutorial/Streaming ETL tutorial of the Zeppelin website):
Create a source table to represent the source data.
We will use%flink.ssqlto represent the following SQL are streaming SQL which will be executed viaStreamTableEnvironment. You can write multiple SQL statements in one paragraph, just separate them with a semicolon.
- Create a sink table to represent the processed data.
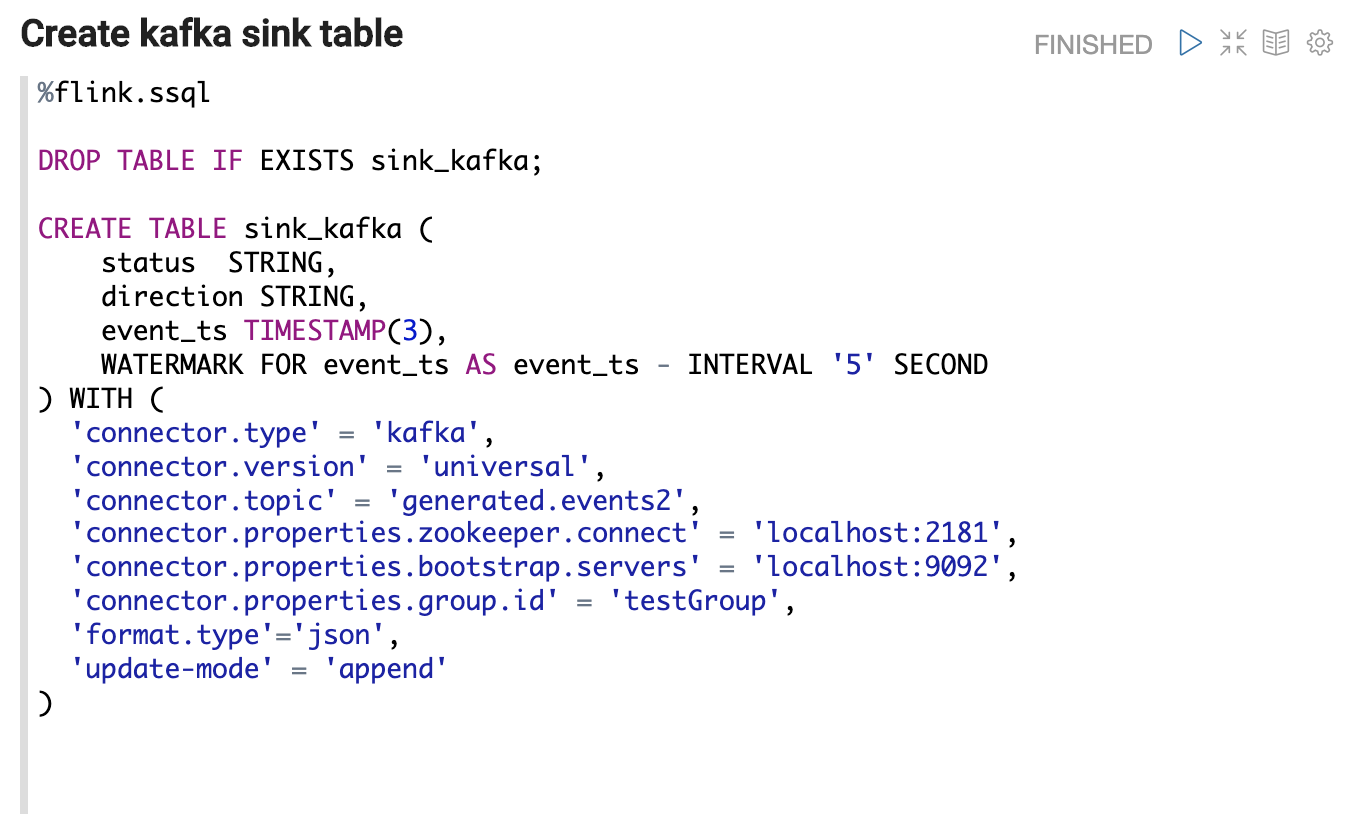
- After creating the source and sink table, we can use insert them to our statement to trigger the streaming processing job as the following:

- After initiating the streaming job, you can use another SQL statement to query the sink table to verify your streaming job.
Here you can see the top 10 records which will be refreshed every 3 seconds.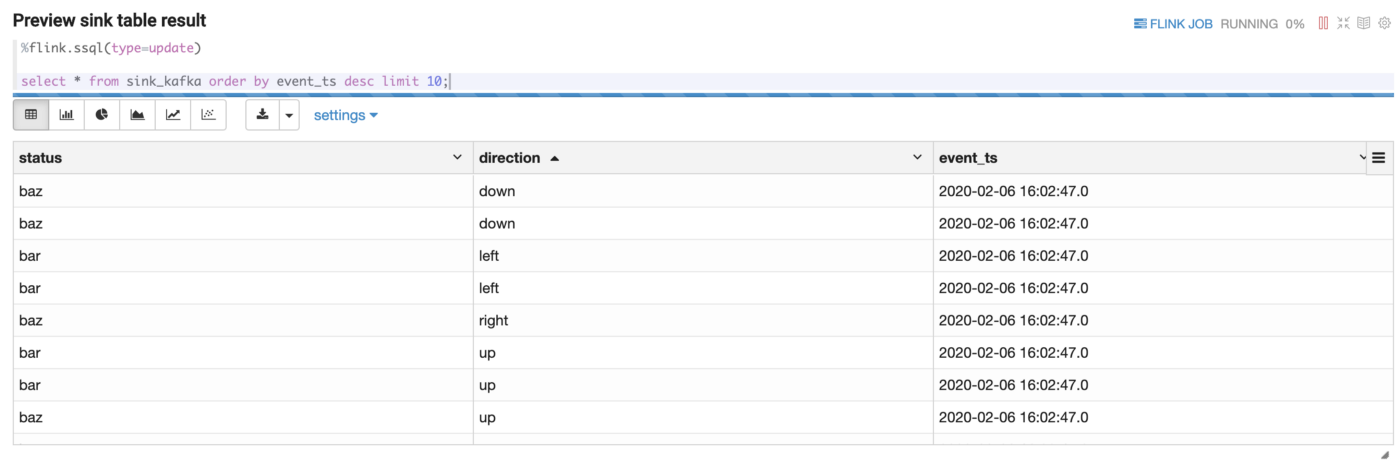
This article discusses how the redesigned Flink interpreter works in Zeppelin 0.9.0 and provides some step-by-step guidance on how to perform streaming ETL jobs with Flink and Zeppelin. You can find additional tutorials, such using Flink on Zeppelin for batch processing, as well as performing more advanced operations with Flink on Zeppelin (e.g. resource isolation, job concurrency & parallelism, multiple Hadoop & Hive environments and more) on this series of posts. We hope you enjoy this new addition to the Zeppelin project and you try the Flink interpreter soon!
Opinions expressed by DZone contributors are their own.
Comments