Apache Druid: A Hybrid Data Warehouse for Fast Analytics
Deep Dive into Druid’s architecture to understand sub-second query response and parallel batch and streaming ingestion.
Join the DZone community and get the full member experience.
Join For FreeHybrid data warehouses can both ingest and process data in real-time as streams and store and query this data in table formats. This dual functionality allows for low latency and high throughput in data processing, accommodating both streaming and batch analytics. Examples of such hybrid data warehouses include Apache Druid and Delta Lake. These technologies employ various methods like columnar storage, indexing, caching, and concurrency control to facilitate real-time data warehousing. Nonetheless, depending on their specific implementation and the use case, they may present complexity, reliability, or consistency challenges.
As real-time data becomes increasingly critical in data engineering and analytics, choosing an appropriate data warehouse technology hinges on multiple factors. These include the data's volume, velocity, variety, and value, business needs, budget constraints, and available expertise. A thorough understanding of the strengths and limitations of each option can guide you in making a well-informed decision for constructing a robust and efficient data warehouse tailored to your real-time data requirements.
What Is Apache Druid?
Apache Druid is an open-source analytics database designed for high-performance real-time analytics. It's particularly well-suited for business intelligence (OLAP) queries on event data. Druid is commonly used in environments where real-time insights into large-scale data are crucial, such as e-commerce, financial services, and digital advertising.
Key Features of Apache Druid Include:
Real-Time Analytics:
Druid excels at providing fast analytics on data as it's being ingested, enabling immediate insights into data streams. It offers rapid query execution across distributed systems and high-capacity data ingestion, ensuring low latency. It excels in processing various event data types, including clickstream, IoT data, and event data recorders (such as those used in Tesla vehicles).
Scalability:
Designed for scalability, it efficiently handles large volumes of data and can be scaled up to meet increased demand.
Low Latency:
Druid is optimized for low-latency queries, making it ideal for interactive applications where quick response times are critical.
High Throughput Ingestion:
It can ingest massive amounts of event data with high throughput, making it suitable for applications like clickstream analytics, network monitoring, and fraud detection.
Flexible Data Aggregation:
It supports quick and flexible data aggregations, essential for summarizing and analyzing large datasets, and facilitates quick data slicing, dicing, and aggregation queries.
Distributed Architecture:
Its distributed architecture allows for robust fault tolerance and high availability, distributing data and query load across multiple servers.
Columnar Storage:
It uses a columnar storage format, which enhances performance for analytic queries.
Time-Partitioned Data:
It boasts a robust architecture featuring time-based sharding, partitioning, column-oriented storage, indexing, data compression, and maintaining versioned, materialized views for high availability.
Druid is often chosen for its ability to provide immediate insights, supporting both real-time and batch processing, and its robust scalability, making it a favorable choice for organizations needing to analyze large amounts of event-driven data quickly.
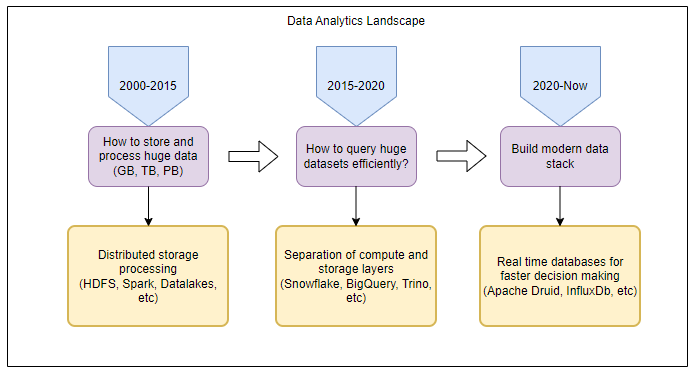
Typical Data ingestion, storage, and data serving layer using Druid:
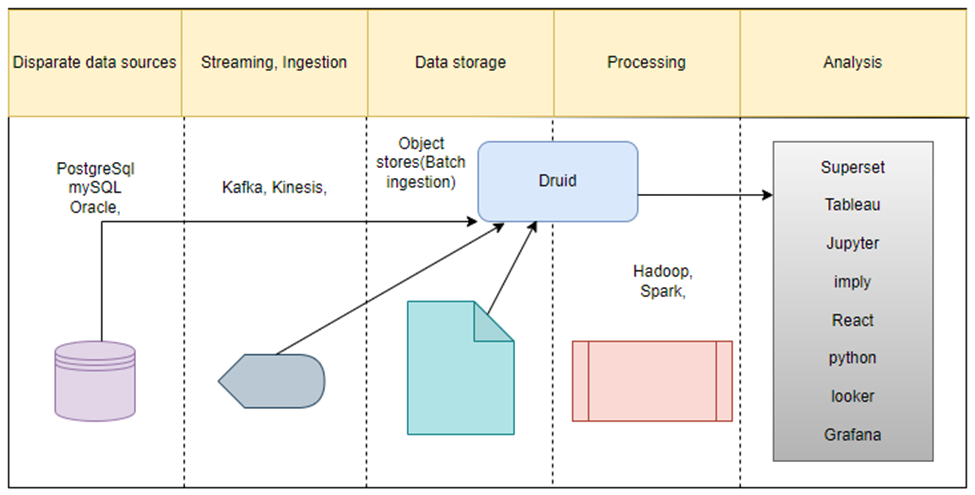
How Druid Operates:
Its architecture is resilient and scalable, optimized for OLAP (Online Analytical Processing) with data formats designed for efficient analysis. Operations are massively parallelized, ensuring resource-aware processing during query execution and data ingestion. Druid allows for simultaneous ingestion of both batch and real-time data. Support for pre-fetch operations facilitates querying in under a second. Data tiering in Druid allows for the strategic utilization of infrastructure resources. It isolates long-running queries, ensuring they don't interfere with other operations.
Key Components of Druid:
Coordinator:
The Druid Coordinator plays a crucial role in data distribution and management. It is responsible for distributing data into Druid Deep storage. It is also responsible for distributing copies of data to historical nodes, significantly enhancing query responses' efficiency and speed. By ensuring that data is appropriately populated into historical nodes, the Druid Coordinator effectively reduces latency, thereby facilitating high-speed queries.
Overlord:
The Druid Overlord is a key component in Apache Druid's architecture, primarily responsible for managing and coordinating data ingestion. Its primary functions include:
- Task Management: The Overlord oversees the assignment and supervision of data ingestion tasks, which can be either real-time or batch. It ensures these tasks are distributed and executed efficiently across the available resources.
- Scalability: It plays a crucial role in scaling the ingestion process, handling varying loads by dynamically assigning tasks to middle manager nodes.
- Fault Tolerance: In case of task failures, the Overlord is responsible for detecting these issues and reassigning the tasks to ensure continuous and reliable data ingestion.
- Load Balancing: The Overlord also manages the load on Druid's middle manager nodes, ensuring an even distribution of tasks for optimal performance.
Router:
The Druid Router is responsible for receiving queries from clients and directing them to the appropriate query-serving nodes, such as Broker nodes or directly to Historical nodes, depending on the query type and configuration.
Broker:
The Druid Broker is a critical component of the Apache Druid architecture, focusing on query processing and distribution. When a query is submitted to Druid, the Broker plays the central role in aggregating the results from various data nodes. It sends parts of the query to these nodes and then combines their results to form the final response.
The Broker node knows the data segments' locations within the cluster. It routes queries intelligently to the nodes containing the relevant data segments, optimizing the query execution process for efficiency and speed. Brokers can also cache query results, which helps speed up the response time for frequent queries, as it avoids reprocessing the same data repeatedly. In summary, the Druid Broker is pivotal in orchestrating query processing within a Druid cluster, ensuring efficient query execution, result aggregation, and load balancing to optimize the performance and scalability of the system.
Historicals:
Druid Historical nodes are key components in the Apache Druid architecture, specifically designed for efficient data storage and retrieval. Here are their main characteristics:
- Single-Threaded Segment Processing: In Druid Historical nodes, each data segment is processed by a single thread. This approach simplifies the processing model and helps in the efficient utilization of system resources for querying and data retrieval.
- Automatic Tiering: Historical nodes support automatic tiering of data. Data can be categorized into different tiers based on usage or other criteria. This tiering helps optimize the storage and query performance, as frequently accessed data can be placed on faster, more accessible tiers.
- Data Management by Coordinator: The Druid Coordinator moves data into the appropriate tier within the Historical nodes. It manages data placement and ensures data is stored on the right tier, balancing load and optimizing storage utilization.
- Memory Mapping: Historical nodes use memory-mapped files for data storage. Memory mapping allows these nodes to leverage the operating system's virtual memory for data management, leading to efficient data access and reduced I/O overhead for queries.
In essence, Druid Historical nodes are specialized for reliable and efficient long-term data storage and retrieval, with capabilities like single-threaded processing, automatic tiering, coordinator-led data management, and memory mapping to enhance performance.
Middle Manager:
The Druid Middle Manager is crucial in Apache Druid's data ingestion process. Druid Middle Managers are pivotal in the data ingestion pipeline of Druid, handling the distribution and execution of ingestion tasks while ensuring scalability and efficient resource management.
- Data Ingestion Management: Middle Managers are responsible for managing data ingestion into the Druid system. They handle both real-time and batch data ingestion tasks.
- Task Distribution: Each Middle Manager node can run one or more tasks that ingest data. These tasks are assigned and monitored by the Druid Overlord, who distributes the ingestion workload among available middle managers.
- Scalability: The architecture of Middle Managers allows for horizontal scalability. As data ingestion demands increase, more Middle Manager nodes can be added to the system to distribute the load effectively.
- Real-Time Data Processing: In the case of real-time data ingestion, Middle Managers are involved in initial data processing and handoff to Historical nodes for long-term storage.
- Worker Nodes: Middle Managers act as worker nodes. They execute the tasks assigned by the Overlord, which can include data indexing, processing, and temporary storage.
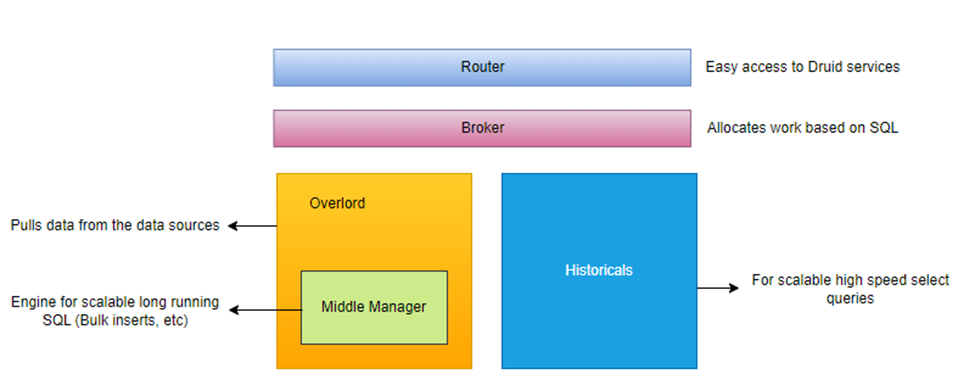
SQL-Based Ingestion (An Example):
INSERT INTO tbl
SELECT
TIME_PARSE("timestamp") AS __time,
XXX,
YYY,
ZZZ
FROM TABLE(
EXTERN(
'{"type": "s3", "uris": ["s3://bucket/file"]}',
'{"type": "json"}',
'[{"name": "XXX", "type": "string"}, {"name": "YYY", "type": "string"}, {"name": "ZZZ", "type": "string"}, {"name": "timestamp", "type": "string"}]'
)
)
PARTITION BY FLOOR(__time TO DAY)
CLUSTER BY XXX JSON-Based Ingestion (An Example):
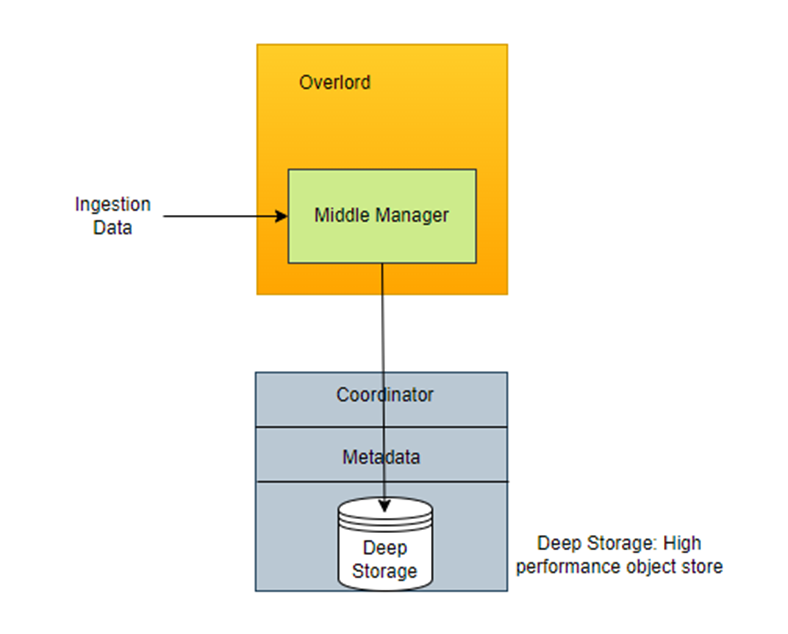
Deep Storage:
Deep storage in Apache Druid is a scalable and durable data storage system for permanent data retention. Deep storage in Druid provides a robust, scalable, and durable solution crucial for maintaining data integrity and availability in large-scale data analytics and business intelligence operations.
- Permanent Storage Layer: Deep storage acts as the primary data repository for Druid, where all the ingested data is stored for long-term retention. This is crucial for ensuring data persistence beyond the lifetime of the individual Druid processes.
- Support for Various Storage Systems: Druid is designed to be agnostic to the underlying storage system. It can integrate with deep storage solutions like Amazon S3, Google Cloud Storage, Hadoop Distributed File System (HDFS), and Microsoft Azure Storage.
- Data Segmentation: Data in deep storage is organized into segments, essentially partitioned, compressed, and indexed files. This segmentation aids in efficient data retrieval and querying.
- Fault Tolerance and Recovery: Deep storage provides the resilience to recover and reload data segments in a system failure. This ensures that data is not lost and can be accessed consistently.
- Scalability: Deep storage scales independently of the compute resources. As data grows, deep storage can be expanded without impacting the performance of the Druid cluster.
- Decoupling of Storage and Processing: Druid allows for flexible and cost-effective resource management by separating storage and processing. Compute resources can be scaled up or down as needed, independent of the data volume in deep storage.
- Data Backup and Archival: Deep storage also serves as a backup and archival solution, ensuring that historical data is preserved and can be accessed for future analysis.
Segments in Deep Storage:
Segments in deep storage within Apache Druid have distinct characteristics that optimize storage efficiency and query performance. Each segment typically contains between 3 to 5 million rows of data. This size is a balance between granularity for efficient data processing and large enough to ensure good compression and query performance.
Data within a segment is partitioned based on time. This time-partitioning is central to Druid's architecture, as it allows for efficient handling and querying of time-series data. Within a segment, data can be clustered by dimension values. This clustering enhances the performance of queries that filter or aggregate data based on these dimensions. Once created, segments are immutable – they do not change. Each segment is versioned, enabling Druid to maintain different versions of the same data. This immutability and versioning are crucial for effective caching, as the cache remains valid until the segment is replaced or updated.
Segments in Druid are self-describing, meaning they contain metadata about their structure and schema. This feature is important for schema evolution, as it allows Druid to understand and process segments even when the schema changes over time. These aspects of segment design in Druid are essential for its high-performance analytics capabilities, especially in handling large volumes of time-series data, optimizing query performance, and ensuring data consistency and reliability.
Some Key Features of Segments Are
Columnar Format: The data in deep storage is stored in a columnar format. This means each column of data is stored separately, enhancing query performance, especially for analytics and aggregation queries, as only the necessary columns need to be read and processed.
- Dictionary Encoding: Dictionary encoding is used to store data efficiently. It involves creating a unique dictionary of values for a column, where a compact identifier replaces each value. This approach significantly reduces the storage space required for repetitive or similar data.
- Compressed Representations: Data in segments is compressed to reduce its size in deep storage. Compression reduces the storage cost and speeds up data transfer between storage and processing nodes.
- Bitmap Indexes: Bitmap indexes are utilized for fast querying, especially for filtering and searching operations. They allow for efficient querying on high-cardinality columns by quickly identifying the rows that match the query criteria.
Other Features of Druid:
Apache Druid includes additional advanced features that enhance its performance and flexibility in data analytics. These features include:
Multiple Levels of Caching
Druid implements caching at various levels within its architecture, from the broker to the data nodes. This multi-tiered caching strategy includes:
- Broker Caching: Caches the results of queries at the broker level, which can significantly speed up response times for repeated queries.
- Historical Node Caching: Caches data segments in historical nodes, improving query performance on frequently accessed data.
- Query-Level Caching: Allows caching of partial query results, which can be reused in subsequent queries.
Query Lanes and Prioritization
Druid supports query planning and prioritization, which are essential for managing and optimizing query workloads. This feature allows administrators to categorize and prioritize queries based on their importance or urgency. For example, critical real-time queries can be prioritized over less urgent batch queries, ensuring that important tasks are completed first.
Approximation and Vectorization:
Approximation Algorithms: Druid can use various approximation algorithms (like HyperLogLog, Theta Sketches, etc.) to provide faster query responses, especially useful for aggregations and counts over large datasets. These algorithms trade a small amount of accuracy for significant gains in speed and resource efficiency.
Vectorization refers to processing data in batches rather than one element at a time. Vectorized query execution allows Druid to perform operations on multiple data points simultaneously, significantly speeding up query performance, especially on modern hardware with SIMD (Single Instruction, Multiple Data) capabilities.
Summary:
The components and features discussed above make Druid a highly efficient and adaptable system for real-time analytics, capable of handling large volumes of data with varying query workloads while ensuring fast and resource-efficient data processing.
Opinions expressed by DZone contributors are their own.
Comments