Apache Camel 101
This article is the beginning of the Apache Camel series where we will go into more detail, some specific components, with examples and best practices.
Join the DZone community and get the full member experience.
Join For FreeApache Camel is an integration framework, which basically means that it is a set of tools that will help you connect one system to another. A basic example could be listening to an AWS SQS queue and saving a file in Google Cloud Storage Bucket for each message that has been received.
It comes already with an implementation of the most used patterns defined in the book “Enterprise Integration Patterns“, which we could make a similarity with the book of Design Patterns by “the Gang of Four” but at the level of systems integration. A book that defines a series of patterns and blueprints to help us to better design large component-based applications.
Why Is an Integration Framework Necessary?
Clearly, Apache Camel (as any other integration framework) is a solution to a problem – either an essential or an accidental one. In microservices oriented applications, the communication between them can be of many types, as discussed in DDD’s “strategic design”, there are many ways to communicate between bounded contexts (microservices), for example, the mapping of the “Conformist” type:
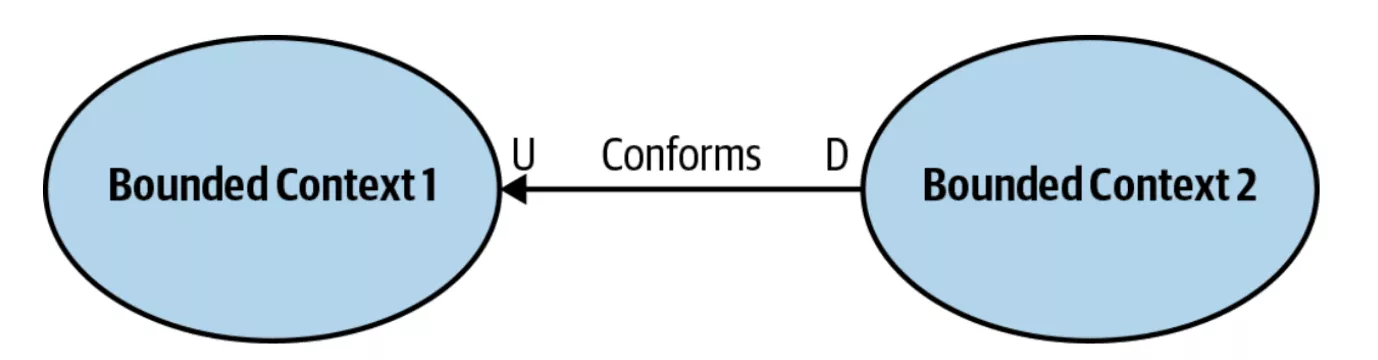
It tells us that the downstream service (D) conforms to the information that comes to it and as it comes to it, it has no choice since the power lies with the upstream service (U).
Take it or leave it
This type of communication is an example that we will have to adapt to any communication (integration) that we have with this service, sometimes we will have some power to define this communication channel and sometimes not, in others there will be no room for definition because there already was in its day, legacy projects where there are systems that have been running for many years and are “untouchable”.
Running Camel
Camel can be executed in multiple ways, from standalone, as part of SpringBoot or Quarkus, or even as part of Kubernetes (with Camel K), although it is not limited to these, it can always be extended more easily to more systems.
Enterprise Integration Patterns (EIP)
It is rare that when you look for information about Apache Camel you do not find the acronym EIP, and that is because Apache Camel was developed as an implementation of the patterns described in the book Enterprise Integration Patterns by Gregor Hohpe and Bobby Woolf. Comparable to the Gang of Four’s Design Patterns book but at the systems integration level.
To give some examples and to know what we are talking about, here is a sample of some EIPs (you will find all of them in EIP and in the Apache Camel documentation).
Content-Based Router
It will help us to route our incoming message to different destinations according to its content.
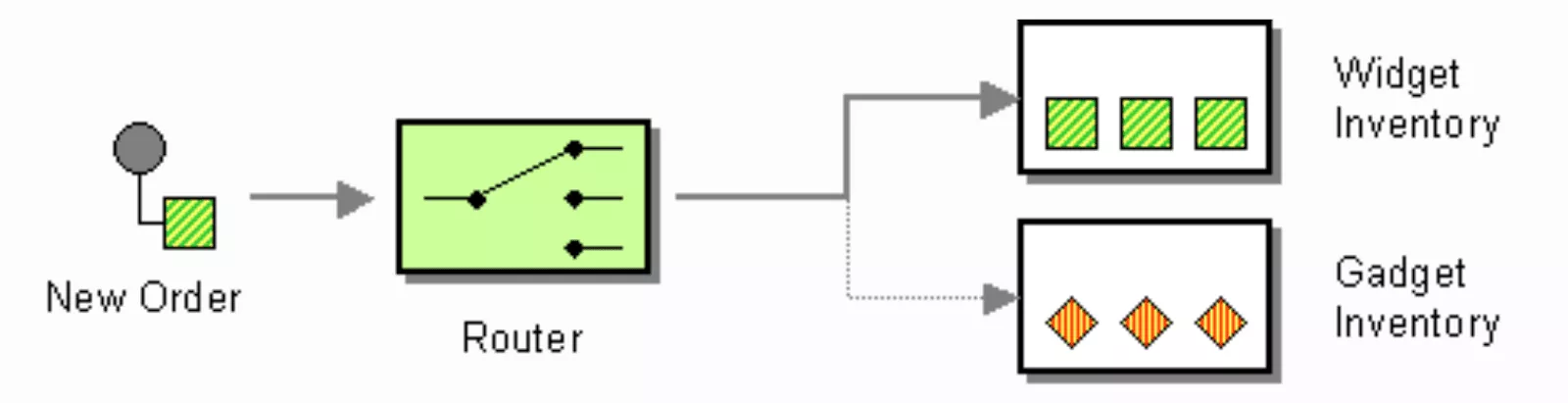
from("direct:in")
.choice()
.when(header("type").isEqualTo("widget"))
.to("direct:widget")
.when(header("type").isEqualTo("gadget"))
.to("direct:gadget")
.otherwise()
.to("direct:other");Filter
With it, we will filter the messages we are really interested in and discard the rest.

from("direct:a")
.filter(simple("${header.foo} == 'bar'"))
.to("direct:b");Enricher
When the message we receive does not have all the data we need, with this pattern we can look for the missing information in another data source and add it to the original message.
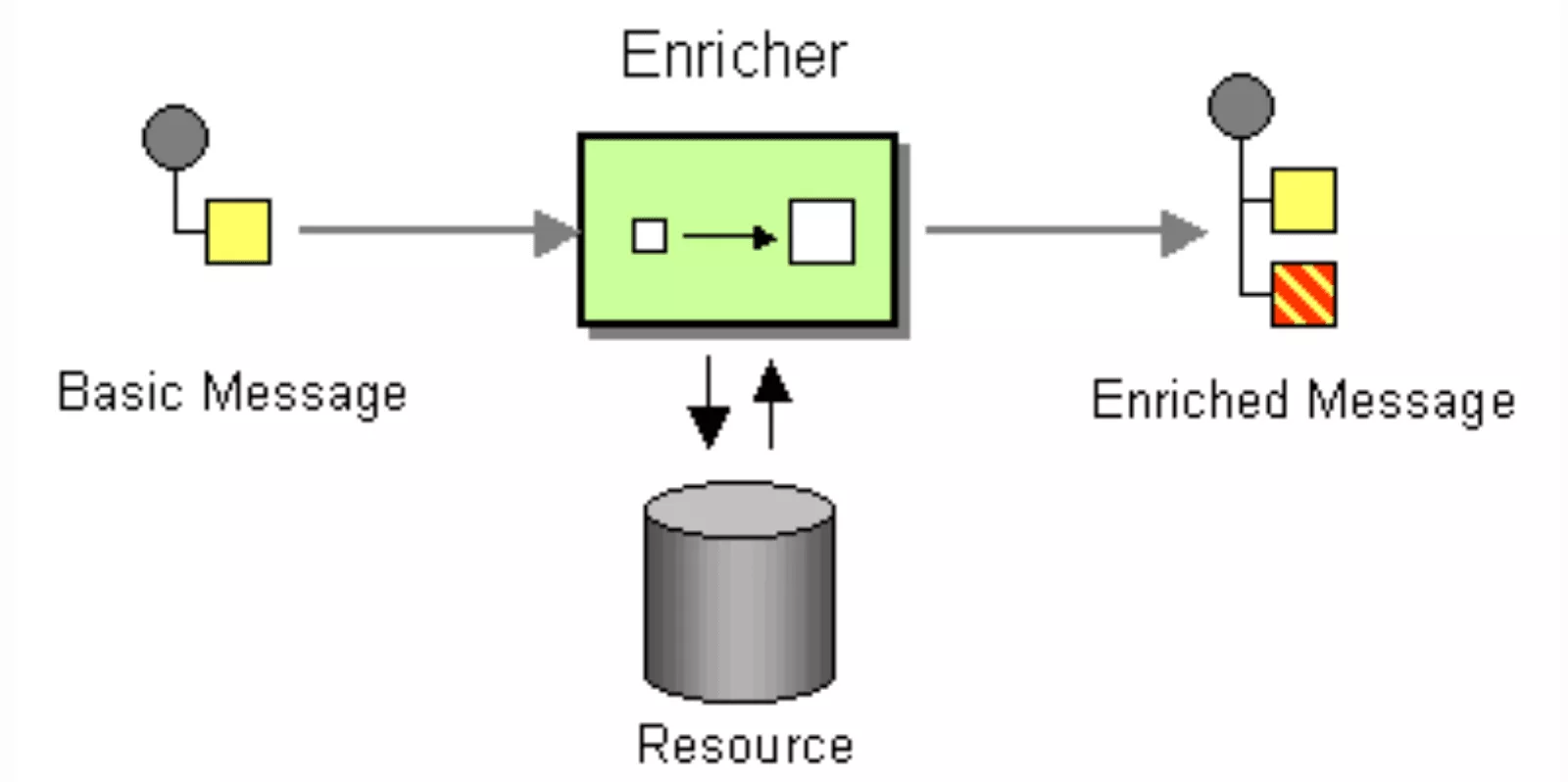
from("direct:start")
.enrich("direct:resource", aggregationStrategy)
.to("direct:result");There are two Enrich’s strategies in Camel, we will go deeper into them in future articles.
What Does Camel Offer?
We cannot reduce Apache Camel to an implementation of the EIPs (although a good part of its power comes from it), but it also provides a wide list of Components (more than 300) to connect with, either as source or destination of data, since at the end, in Camel we will be developing Routes where we will connect a Component A with Component B, for example:
from("aws-sqs://queue-name")
to("aws-s3://bucket-name")
It is possible that two components that must communicate with each other do not speak the same “language” (format), it is possible that the output of one is XML while the input of the other is a JSON, for that camel allows you to configure a series of Data Format within its runtime to be able to convert from one type to another easily.
Not only the format is relevant in the communication, but there are also different types of data, you can receive a message in JSON format from a queue and want to persist that message in a file in an S3 bucket, Apache Camel will try to convert that same body that it receives as JSON in the file automatically (as long as it has the necessary component to do it since Camel is not a single package, it usually has a package for each component).
When To Use Camel?
This question has been in my mind since I created my first route in Apache Camel. It is easy to see that when a project has many integrations, Apache Camel will help us, it will manage a lot of complexity and will unify the way in which we integrate, since for Camel everything is considered a Message, regardless of the data source.
The fact that Camel standardizes all data, in the same way, will simplify our integrations with other systems. At the routing level, the type of data that travels when you read a file in an S3 bucket or when you read a message in a queue is the same, and Exchange with the Message in it.
Since the decision is very subjective and it will depend a lot on the project and the team, I will leave here some points to take into account that can help to make the decision whether to use Apache Camel or not:
- How many sources/destinations your application has?
- How many protocols does it speak?
- What kind of communication (at the Mapping Context level) exists between the different bounded contexts? If there is fluid communication, where you work as a team, it is possible to unify the protocol, format, and so on (although it is somewhat utopian).
Infrastructure or Business?
This other question arises once you already use Apache Camel in your application, and it is where to put the logic, if as part of the Camel route, or in the destination of the route? Should I use the Splitter pattern plus the Content-Based Router inside the Camel route to then send it to one endpoint or another in the destination, or should I create a single endpoint in the destination that will take care of splitting it and do what it has to do? Should I enrich the message before it reaches the destination or after?
These are difficult questions to answer, but I would try to follow the concept of smart endpoints and dumb pipes, which means that the logic should be mostly at the destination, avoiding as much as possible to put business logic (rules and invariants that cover the need of the end-user) inside the routes.
Endpoints
The concept of Endpoint is not a concept exclusive to Apache Camel. When we talk about Endpoint, we are referring to a connection point to a service, for example, it could be an HTTP endpoint, a subscriber in an SNS topic, etc.
At Apache Camel level, an Endpoint is an interface where we will create the Consumer or Producer (or both) from where to start/end a route.
Continuing with the first example: aws-sqs://queue-name is an Endpoint, and since we are calling it from the from(), it requires the Component aws-sqs to be of type Consumer. The same happens with the .to() method, we could use the same Endpoint as long as the component is also Producer. (To know if a component is a Consumer or Producer is in the first line of the component documentation).
Why “Smart Endpoints and Dumb Pipes”?
It would be logical to think (and this is defined in some articles on the Internet), that pipes should only redirect the output message from one point to the input of another. A good example of this type of pipes are those of Unix systems: ls | grep dir, where the stdout of the command ls, is redirected to the stdin of grep, the pipe does not have more work than that, the rest is done by the endpoints.
If we continue with the Unix example, it is true that the pipe only does one thing, but the protocol that all the endpoints follow is the same, stdout -> stdin. In a large application, it is more than likely that we will find several protocols in play (SQS -> http, Kafka -> FTP, and a long, etc.), but this is something that we solve with the components that Camel brings, it is something that does not affect the concept of dumb pipes.
However, the format of the data in Unix while executing our programs can change, it can be that the stdout of the data source is JSON while the input of the destination we are looking for is a simple string (an id, for example). In Unix, we would do something like curl http://product/list | jq .id | http://product/register (pseudo-code), although it is true that the pipes are limited to moving the message from one side to another, in the complete path we have added a program that transforms the output of our data source and adapts it to the input of our destination.
It is in this type of case where Camel will help us without breaking this principle (being strict we are breaking it… but not everything is black and white).
Another very different thing would be, following the previous example, to add in the route a check that the product has stock in the warehouse before registering it, this is an invariant that we could put previously before registering the product, but then we would be separating our business logic to register a product in two different services, with all the problems that this entails.
In my opinion, endpoints understand business concepts, they speak the business language (ubiquitous language) – invariants, business rules, business flows, etc. While at the dumb pipes level, if I see well to be able to have some infrastructure logic as could be filtering of some unwanted message by the destination endpoint, the transformation of message format (XML to JSON), normalize messages arriving from various systems (SQS, Kafka, RabbitMQ) removing metadata that includes each system and a long etcetera that we will find, as you see, closely related to infrastructure issues.
Conclusions
Camel has a medium learning curve, it is not difficult to start developing robust routes that can reach production, but it will be complex to master the whole system that is mounted, there are always details that make you not stop learning (and block you sometimes in your development).
Nor will it prevent you from having to read the documentation for any component, if for example, you are using aws-s3 (either for source or target), if we read the implementation, we will see that it is using the AWS SDK so nothing will avoid having to know it, all the configuration properties you will find them in the Camel documentation but also in the AWS documentation. Comparable to wanting to use Terraform without knowing AWS, GCP, or Azure, or wanting to use TailwindCSS without knowing CSS.
Published at DZone with permission of Oscar Galindo. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments