Anomaly Detection: Leveraging Rule Engines to Minimize False Alarms
This article presents a rule-engine-based method on top of anomaly detection algorithm that cross-references multiple KPIs for faster, more accurate anomaly detection.
Join the DZone community and get the full member experience.
Join For FreeAnomalies are deviations from expected patterns and can occur in a plethora of contexts — be it in banking transactions, industrial operations, the marketing industry, or healthcare monitoring. Traditional detection approaches often yield a high rate of false positives. False positives are instances where the system incorrectly identifies a regular event as an anomaly, leading to unnecessary investigative efforts and operational delays. This inefficiency is a pressing concern, as it can drain resources and divert attention from genuine issues that need addressing. This article delves into a specialized approach for anomaly detection that makes extensive use of a rule-based engine. This method enhances the accuracy of identifying irregularities by cross-referencing multiple Key Performance Indicators (KPIs). Not only does this approach validate or refute the presence of anomalies more effectively, but it also occasionally isolates and identifies the underlying root cause of the issue.
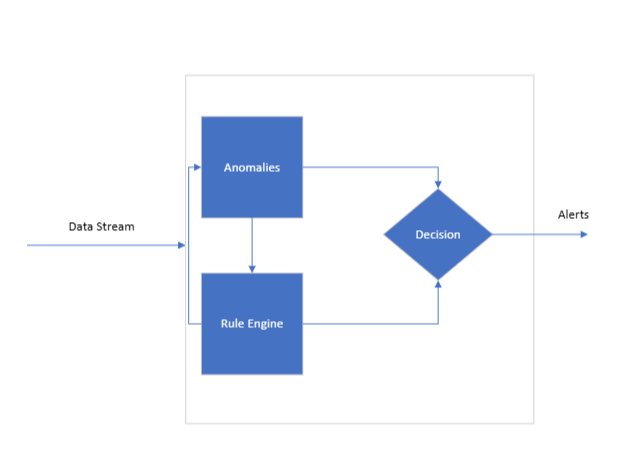
Overview of the System Architecture
Data Stream
This is the continuous flow of data that the engine reviews. Each point in this stream may relate to one or more KPIs, which the rule engine uses to evaluate against its set of trained rules. The constant flow of data is essential for real-time monitoring, providing the engine with the necessary information to work on.
Rule Engine Architecture
At the core of the system lies the rule engine, which needs to be trained to understand the nuances of the KPIs it will monitor. This is where a set of KPI rules come into play. These rules serve as the algorithmic foundation for the engine and are designed to associate two or more KPIs together.
Types of KPI Rules:
- Data Quality: Rules that focus on the consistency, accuracy, and reliability of data flow.
- KPI Correlation: Rules that focus on the correlation of certain KPIs
Rule Application Process
Upon receiving the data, the engine immediately looks for deviations or anomalies in the incoming KPIs. An anomaly here refers to any metric that falls outside of a predetermined acceptable range. The engine flags these anomalies for further investigation, which can be categorized into three primary actions: Accept, Reject, and Narrow Down. This can involve correlating one KPI with another to validate or negate the detected anomaly.
Methodology
Rule Formation
The foundational step involves creating a series of rules that interrelate multiple KPIs. For example, a rule might associate product quality metrics with production speed in a factory setting. For example:
- Direct relationship between KPIs: A "direct relationship" between two KPIs implies that when one KPI increases, the other also increases, or when one decreases, the other also decreases. For instance, in a retail business, an increase in advertising spending (KPI1) might be directly related to an increase in sales revenue (KPI2). In this case, an increase in one positively affects the other. Such knowledge is invaluable for businesses as it helps in strategic planning and resource allocation.
- Inverse relationship between KPIs: On the other hand, an "inverse relationship" means that when one KPI goes up, the other goes down, or vice versa. For example, in a manufacturing setting, the time it takes to produce a product (KPI1) may have an inverse relationship with production efficiency (KPI2). As the production time decreases, the production efficiency may increase. Understanding inverse relationships is also critical for business optimization because it may require a balancing act to optimize both KPIs.
- Combining KPIs to formulate new rules: Sometimes, it may be beneficial to combine two or more KPIs to create a new metric that offers valuable insights into business performance. For instance, combining 'Customer Lifetime Value' (KPI1) and 'Customer Acquisition Cost' (KPI2) can yield a third KPI: 'Customer Value to Cost Ratio.' This new KPI could provide a more comprehensive understanding of whether the cost of acquiring a new customer is justified by the value they bring over time.
Training the Rule Engine
The rule engine undergoes comprehensive training to effectively apply these rules in real time.
Real-Time Scrutiny
The rule engine actively monitors incoming data, applying its trained rules to identify anomalies or potential anomalies.
Decision Making
On identifying a potential anomaly, the engine:
- Accepts the anomaly: The confirmation phase: Once an anomaly is flagged, the engine uses its pre-trained KPI rules to compare it with other associated KPIs. The focus here is to ascertain whether the anomaly is indeed an issue or a mere outlier. This confirmation is done based on the correlation between the primary and secondary KPIs.
- Rejects the anomaly: The false alarm phase: Not all anomalies indicate a problem; some could be statistical outliers or data errors. In such cases, the engine utilizes its training to reject the anomaly, essentially identifying it as a false alarm. This is crucial for eliminating unnecessary alert fatigue and for focusing resources on genuine issues.
- Narrows down the anomaly: The refinement phase: Sometimes, an anomaly may be part of a bigger problem affecting multiple components. Here, the engine goes a step further to pinpoint the exact nature of the issue by narrowing it down to specific KPI components. This advanced filtering helps quickly identify the issue and resolve the root cause.
Advantages
- Reduced false alarms: By using the rule engine that cross-references multiple KPIs, the system significantly lowers the occurrence of false alarms.
- Time and cost efficiency: The speed at which anomalies are detected and addressed is increased, cutting down operational time and associated costs.
- Enhanced accuracy: The ability to compare and contrast multiple KPIs provides a more nuanced and accurate representation of anomalous events.
Conclusion
This article provides an overview of an approach to anomaly detection using a rule engine trained with a diverse set of KPI rules. In contrast to traditional anomaly detection systems, which often rely solely on statistical algorithms or machine learning models, this approach incorporates a specialized rule engine as its cornerstone. By delving deeper into the relationships and interactions between different KPIs, a business can gain more nuanced insights that simple, standalone metrics can't provide. This allows for more robust strategic planning, better risk management, and an overall more effective approach to achieving business objectives. Once an anomaly is flagged, the engine uses its pre-trained KPI rules to compare it with other associated KPIs. The focus here is to ascertain whether the anomaly is indeed an issue or a mere outlier. This confirmation is done based on the correlation between the primary and secondary KPIs.
Opinions expressed by DZone contributors are their own.
Comments