Airbyte and Llamaindex: ELT and Chat With Your Data Without Writing SQL
Discover the power of querying databases with natural language, bypassing the need for SQL expertise and memorization of complex database schemas.
Join the DZone community and get the full member experience.
Join For FreeThere are some great guides out there on how to create long-term memory for AI applications using embedding-based vector stores like ChromaDB or Pinecone. These vector stores are well-suited for storing unstructured text data. But what if you want to query data that’s already in a SQL database - or what if you have tabular data that doesn’t make sense to write into a dedicated vector store?
For example, what if we want to ask arbitrary historical questions about how many GitHub issues have been created in the Airbyte repo, how many PRs have been merged, and who was the most active contributor overall time? Pre-calculated embeddings would not be able to answer these questions, since they rely upon aggregations that are dynamic and whose answers are changing constantly. It would be nearly impossible - and efficient - to try to answer these questions with pre-formed text documents and vector-based document retrieval.
In this post, we’ll show how to chat with your SQL data warehouse using LlamaIndex. We’ll ask questions in plain English, and the AI model will write and run SQL queries to answer our questions. Unlike similar “bring-your-own-data” projects, we won’t need to calculate embeddings or use an external vector store database.
We’ll use Airbyte to set up a production data pipeline, which feeds data incrementally from GitHub into Snowflake on our chosen frequency: daily, weekly, or even hourly. Airbyte makes this fast, easy, and secure by streamlining authentication to GitHub and Snowflake, handling rate limiting, and tracking tokens securely so we don’t have to worry about a separate credential management system.
Your LLM output is only going to be as good as the underlying data. Using Airbyte to automatically sync all your data to a warehouse makes sure everything is available for the LLM and in a consistent format.
Why Chat-To-SQL Interfaces Are So Powerful
Querying databases and data warehouses has traditionally required the questioner to have a high proficiency in SQL. Even for practitioners well-versed in SQL, there’s always a learning curve associated with learning new tables and data models. Even if you are an expert in SQL, you can’t write queries until you’ve learned the data model, and learning each new data model takes up valuable time.
Now, with LLMs and new libraries like LlamaIndex, we can use natural language to interact with our data - without SQL expertise and without needing to learn or memorize database schemas ourselves. The LLM will generate SQL to answer our natural language question and then run the SQL and return the result. The LLM will automatically scan the table metadata to get column and table names so that it can create valid SQL for our specific data model.
We’ll show how this new and novel approach can be used to answer real-world questions like "Who has opened the largest number of issues this month?" without writing any SQL and without requiring us to use a dedicated vector store. As a bonus, we’ll be able to see exactly what SQL the LLM is creating - so we can better understand what actions it is performing and we can learn SQL a little better in the process.
Ready to go? Let's get started!
Step 1 - Populate GitHub Source Data in Snowflake Using Airbyte
We’ll start by using Airbyte’s GitHub connector to pull data into Snowflake. With a few clicks, we’ll create a connection from GitHub to Snowflake, and Airbyte will take care to keep the pipeline running and always up-to-date.
Add the GitHub Source Connector
Log in to Airbyte and click “New Connection”.

Select GitHub from the list of source connectors and then use the “Authenticate” option to connect your own GitHub account using OAuth. You can use your repo or copy the below configuration to analyze data from the Airbyte Github repository.

Add the Snowflake Destination Connector
For this example, we’ll use Snowflake destination, but you can use whatever database or data warehouse destination you would like.
When prompted for a destination, you can configure Snowflake as in the below example.

Make sure your warehouse name, database name, and user name are correct. As with GitHub, you can automatically and securely authenticate to Snowflake using the provided “Authenticate” option.
Configure the Connection
For this example, we only need a few streams: issues, pull requests, and users. From the Airbyte Cloud UI, you can select just those streams, or select additional streams if you would like.
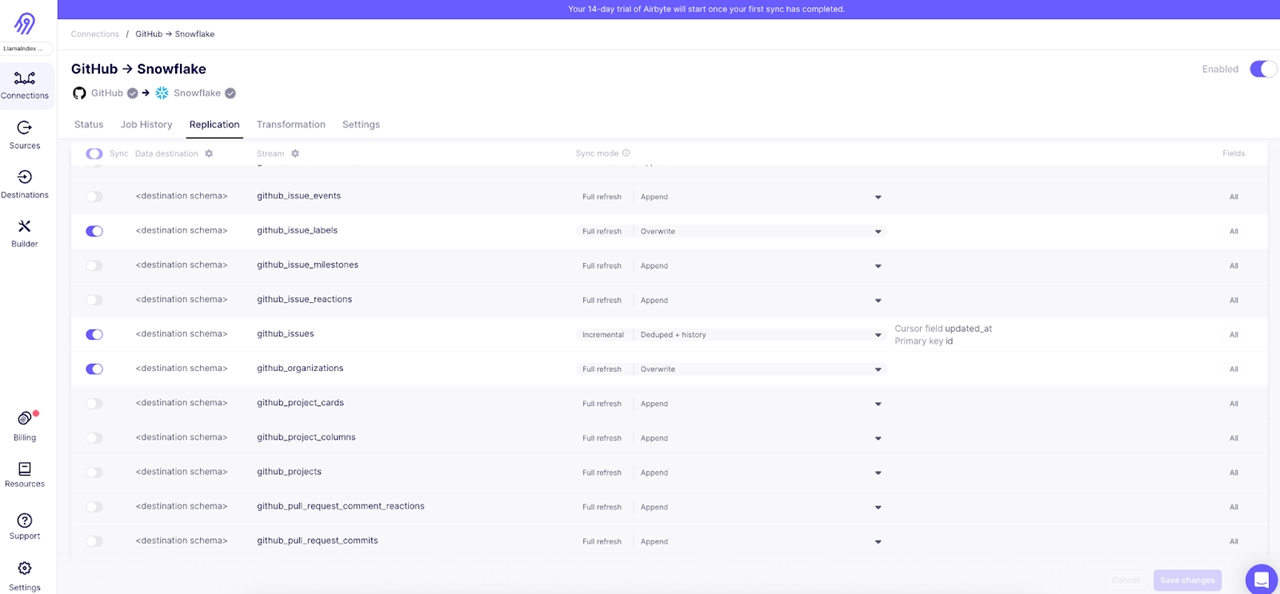
Once you’ve completed the configuration, go ahead and execute the initial data sync using the “Sync now” option.
Once the initial sync completes, you’re all set and we’re ready to analyze the data.
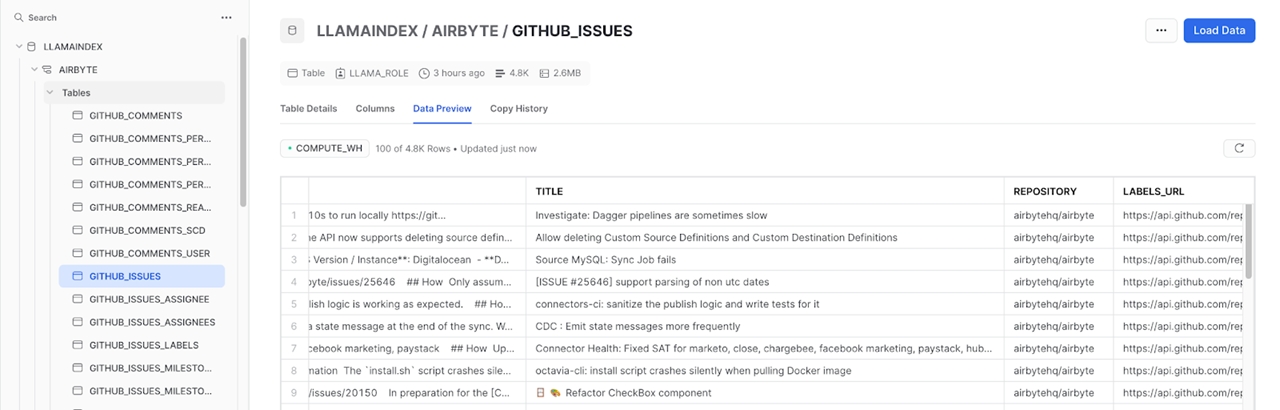
Step 2 - Setting up the Python Libraries
For brevity, I will provide just a summary of the Python libraries we’re using. For full step-by-step instructions, please see the notebook here.
First, we installed LlamaIndex, which handles the translation between SQLAlchemy, LlangChain, and OpenAI. This also installs SQLAlchemy, LangChain, and the OpenAI libraries.

Next, we install the Snowflake driver for SQLAlchemy. This specifically lets us interface with our Snowflake databases.

Tip: If you are following along, you may run into some temporary incompatibility issues between Snowflake and SQLAlchemy 2.0, which is required by LlamaIndex. For more information, see this Snowflake-SQLAlchemyissue and our workaround implementation in this notebook.
Step 3 - Querying The Database With Llamaindex And GPT
Now comes the fun part. We’ve seen that we can query the GitHub data directly in Snowflake but let’s see what LlamaIndex can do with some standard questions we would like to ask in plain English.
We’ll start by creating a helper function to quickly answer our questions using LlamaIndex and OpenAI:

Now we can quickly ask questions just by calling our helper function.

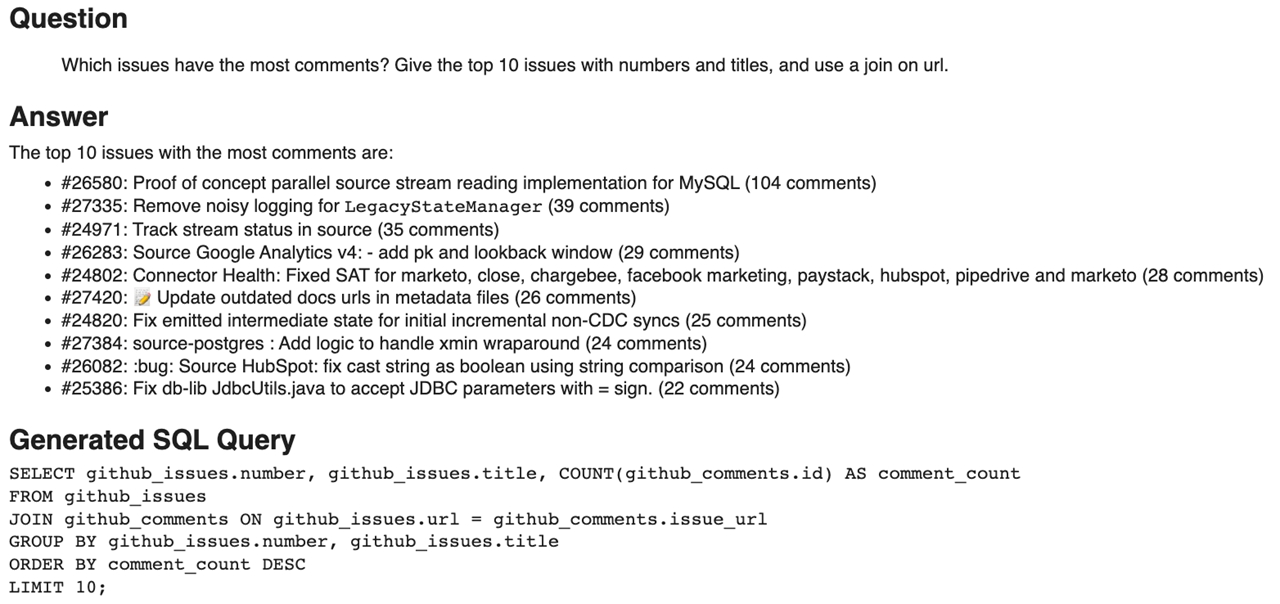
We can also use this capability to understand trends, such as how many new issues are opened each month.


Let’s try something different now. Let’s see if we can better understand who our top contributors are:

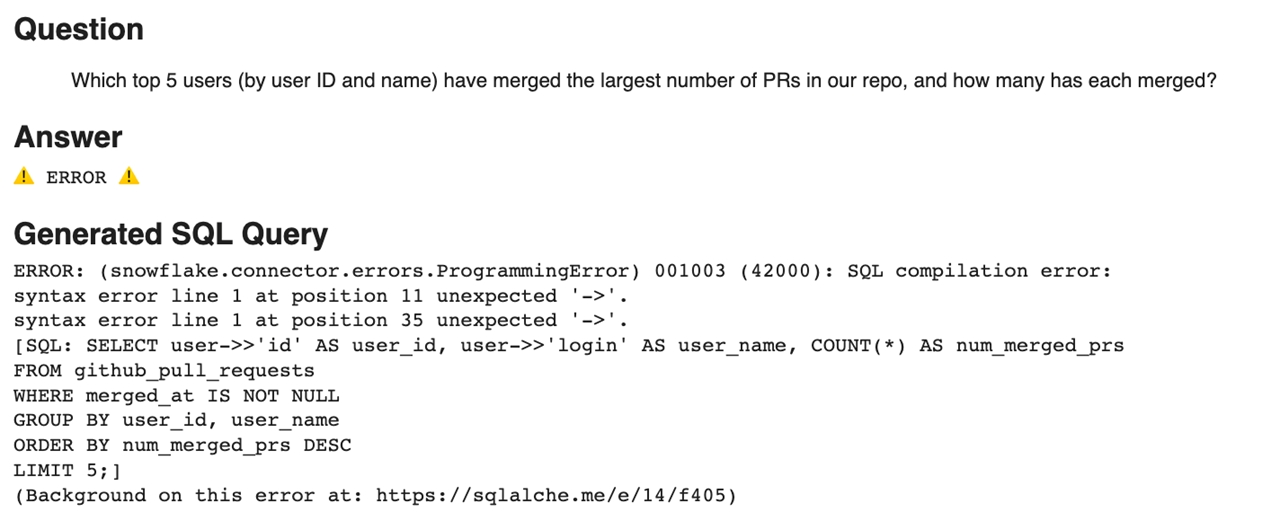
But wait - this attempt failed. After looking more closely at the generated SQL, it appears that LlamaIndex and the LLM are correctly trying to get “id” and “login” from the “user” column, but they don’t generate Snowflake-supported syntax for accessing child elements of variant columns. Instead of using “:”, the AI tries to use “->”, which is a syntax error in Snowflake.
We can easily fix this by giving the LLM an additional hint regarding the specific Snowflake-specific syntax we expect it to use. In Snowflake, we do have a few options but the most common is the colon (“:”) operator. Let’s add a second sentence to the prompt from above, explaining the proper Snowflake syntax:

With just this one change, we can see now that both the Snowflake SQL syntax and the response are correct!

The SQL query is now correctly using user: login to correctly access the user’s name and LlamaIndex is now able to provide us the answer as we requested.
Wrapping Up!
If you’ve followed along this far, congrats! You know how to set up Airbyte to integrate data from virtually any data source, and you can ask questions about your SQL data sources directly in plain English using LlamaIndex and OpenAI.
I’m very excited about the long-term value that Large Language Models (LLMs) can bring to the world of data. We are only just beginning to scratch the surface of what's possible. A big thanks to LlamaIndex for building this tool, and specifically Hongyi Shi, who created the original IPython notebook and who helped make this post possible.
While today’s implementations still have their weaknesses, these technologies will only become more capable and more robust over time. For existing data engineers and analysts, these technologies are bringing about entirely new methods of interacting with our data. For practitioners entering the space for the first time, there’s never been a more exciting time to join in the field of data and AI.
We hope this guide has helped you explore a new way of interacting with your data.
Published at DZone with permission of John Lafleur. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments