Accumulator and Broadcast Variables in Spark
Join the DZone community and get the full member experience.
Join For FreeAt a high level, accumulators and broadcast variables both are Spark-shared variables. In distributed computing, understanding closure is very important. Often, it creates confusion among programmers in understanding the scope and life cycle of variables and methods while executing code in a cluster. Most of the time, you will end up getting :
org.apache.spark.SparkException: Job aborted due to stage failure: Task not serializable: java.io.NotSerializableException: ...
The above error can be triggered when you initialize a variable on the driver, but try to use it on one of the executors. In such a case, Spark will first try to serialize the object to send it across executors and fail if the object is not serializable. It will then throw a java.io.NotSerializableException. From this, it is evident that the concept of a shared variable (rather than a global variable) in Spark is different, and that will introduce you to Accumulator and Broadcast Variables, two special kinds of shared variables that Spark provides.
This article will dive into the details of Accumulators and Broadcast Variables.
So, let's dive in.......
Accumulators
Accumulators are a special kind of variable that we basically use to update some data points across executors. One thing we really need to remember is that the operation by which the data point update happens has to be an associated and commutative operation. Let's take an example to have a better understanding of accumulator:
Lets say, you have a big text file, and you need to find out the count of the number of lines containing "_".
This is a good scenario where you can use an accumulator. So, first, we'll read the file which will create an RDD out of it.
xxxxxxxxxx
val inputRdd = sc.textFile("D:\\intelliJ-Workspace\\spark_application\\src\\main\\sampleFileStorage\\rawtext")
It will distribute the file in multiple partitions across all the executors. Now, we need to create an accumulator in the driver. We will be using an Accumulator of type Long, as we are going to count the lines with '_'.
xxxxxxxxxx
val acc = sc.longAccumulator("Underscore Counter")
Now, we will check if each line of the inputRdd contains '_' and increase the accumulator count by 1 if we find it. so, in the end, if we print the value of the accumulator, will see the exact count of lines having '_'.
xxxxxxxxxx
inputRdd.foreach { line =>
if (line.contains("_"))
acc.add(1)
}
println(acc.value);
So, the bottom line is when you want Spark workers to update some value, you should go with accumulator. For more details regarding accumulator, please go through the RDD programming guide.
Broadcast Variables
Broadcast variables are read-only variables that will be cached in all the executors instead of shipping every time with the tasks. Basically, broadcast variables are used as lookups without any shuffle, as each executor will keep a local copy of it, so no network I/O overhead is involved here. Imagine you are executing a Spark Streaming application and for each input event, you have to use a lookup data set which is distributed across multiple partitions in multiple executors; so, each event will end up doing network I/O that will be a huge, costly operation for a streaming application with such frequency.
Now, the question is how big of a lookup dataset do you want to broadcast!! The answer lies in the amount of memory you are allocating for each executor. See, if we broadly look at memory management in Spark, we'll observe that Spark keeps 75% of the total memory for its own storage and execution. Out of that 75%, 50% is allocated for storage purposes, and the other 50% is allocated for execution purposes.
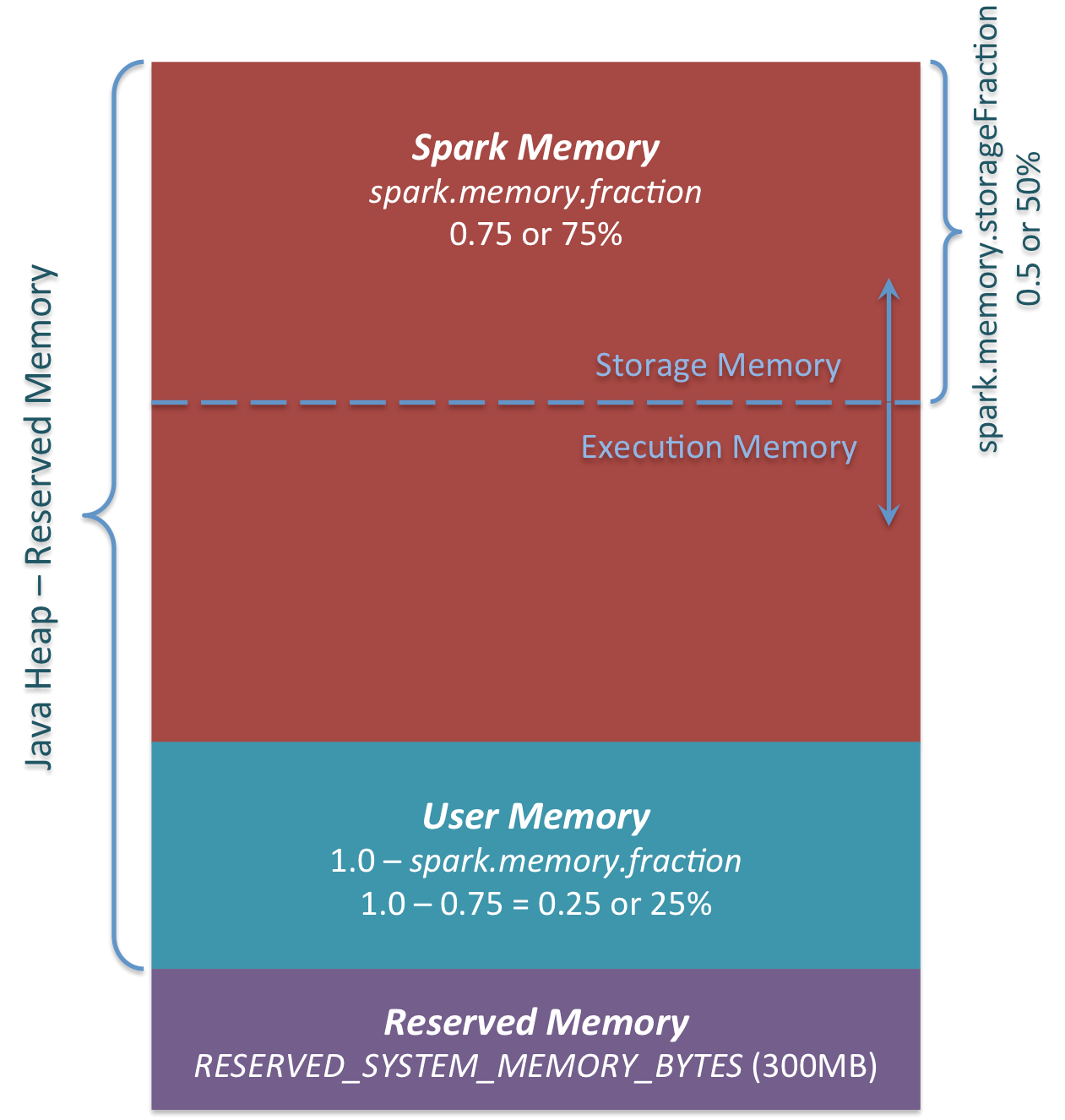
For example, if you allocate 10 GB memory to an executor, then according to the formula, you Spark storage memory would be :
(“Java Heap” – 300MB) * 0.75 * 0.5 = 3.64GB(approx) [ 300MB is reserved memory ]
Spark stores broadcast variables in this memory region, along with cached data. There is a catch here. This is the initial Spark memory orientation. If Spark execution memory grows big with time, it will start evicting objects from a storage region, and as broadcast variables get stored with MEMORY_AND_DISK persistence level, there is a possibility that it also gets evicted from memory. So, you could potentially end up doing disk I/O, which is again a costly operation in terms of performance.
So, the bottom line is, we have to carefully choose the size of the broadcast variables keeping all this in mind. If you want to know more about Spark memory management, please check this blog Spark memory management.
So, in the end, we can say that through accumulators, Spark gives executors provision to coordinate values with each other; whereas through broadcast variables, it provides the same dataset across multiple stages without shuffling.
Opinions expressed by DZone contributors are their own.
Comments