A Simple Method for Training GPT-2 To Generate Haiku Using the NanoGPT Repository
In this article, I will show how to fine-tune a pre-trained GPT-2 model using a smaller dataset, which anyone can easily make or find online.
Join the DZone community and get the full member experience.
Join For FreePurpose
In this article, I will show how to easily train GPT-class neural networks from home. Let me start by saying that we won’t train NN from scratch, as that would require 8 (eight!) A100-class GPUs at least and a massive dataset. Instead, we’ll focus on fine-tuning a pre-trained GPT-2 model using a smaller dataset, which anyone can easily make or find online. OpenAI has kindly released GPT-2 under Modified MIT License.
nanoGPT
We’ll use the nanoGPT repository created by Andrej Karpathy for fast and easy GPT training. He has a comprehensive video lecture explaining how GPT-2 works and how to train such a neural network. However, we’re interested in fine-tuning the model using our own dataset and seeing the difference from the original (GPT-2 trained by OpenAI).
Choosing Dataset
I decided to try teaching GPT-2 some poetry with a clearly identifiable style. Poetry is often quite simple, and GPT-2 can demonstrate good results in that domain. I chose to focus on haiku, a form of Japanese poetry in which each verse consists of three short lines.
An old silent pond
A frog jumps into the pond —
Splash! Silence again. -- “The Old Pond” by Matsuo Bashō
Haiku Dataset Preparation
I found a dataset of haiku collections on Kaggle. It is protected by a license (CC BY 4.0, link to the source). The dataset is not so big, ~340k tokens (~20MB). In order to adapt the dataset to my needs, I cleaned it up by removing spaces, dashes, and other punctuation that, in my opinion, was unnecessary. In the end, I made sure that each line of the dataset was one haiku, separated by a semicolon ; and generate input.txtfile.
fishing boats;colors of;the rainbow
import csv
import re
with open('all_haiku.csv', 'r') as csv_file:
reader = csv.reader(csv_file)
i = 0
txt_file = open('input.txt', 'w')
for row in reader:
strings = row[1:4]
upd_strings = []
for str in strings:
if len(str) > 0:
if str[0] == ' ':
while str[0] == ' ':
str = str[1:]
if str[-1] == ' ':
while str[-1] == ' ':
str = str[:-1]
upd_strings.append(re.sub(r"[^a-zA-Z ]+", "", str))
else:
upd_strings.append('')
# skip text and label
if i > 0:
txt_file.write(upd_strings[0] + ';' + upd_strings[1] + ';' + upd_strings[2] +'\n')
i+=1
print("Added", i-1, "strings of text")After that, I used the prepare.py file from data/shakespeare to convert the input.txt into two files, train.bin and val.bin. The first file was used for training, and the second file was used for validation, as the name implies. The split was 90/10, but the ratio could always be adjusted (look for the 0.9 value in the file).
Data Preparation and Fine-Tuning
Next, I took the finetune_shakespeare.py file as a basis and modified it accordingly:
import time
out_dir = 'out-haiku'
eval_interval = 5
eval_iters = 40
wandb_log = True # feel free to turn on
wandb_project = 'haiku'
wandb_run_name = 'test3'
dataset = 'haiku'
init_from = 'gpt2-large' # this is the largest GPT-2 model
# only save checkpoints if the validation loss improves
always_save_checkpoint = False
# the number of examples per iter:
# 1 batch_size * 32 grad_accum * 1024 tokens = 32,768 tokens/iter
# shakespeare has 301,966 tokens, so 1 epoch ~= 9.2 iters
# haiku has 2,301,966 tokens, so 1 epoch ~= 70 iters * 10 number of iterations
batch_size = 1
gradient_accumulation_steps = 32
max_iters = 1000
# finetune at constant LR
learning_rate = 1e-6
decay_lr = True
warmup_iters = 200#max_iters/10
lr_decay_iters = max_iters
min_lr = learning_rate/10
compile=FalseI selected a learning rate of 1e-6 through experimentation and also recommend using wandb, which provides better visualization of your experiments. Since I wasn’t using the new PyTorch 2.0, I added compile=False. I chose the ‘gpt2-large’ (772M) network because I was using an RTX3090 with 24GB of video memory, and the ‘gpt2-xl’ (1.5B) wouldn’t fit. You can use a different pre-trained GPT-2 model, depending on the hardware you’re using. The larger the network, the better the results will be.
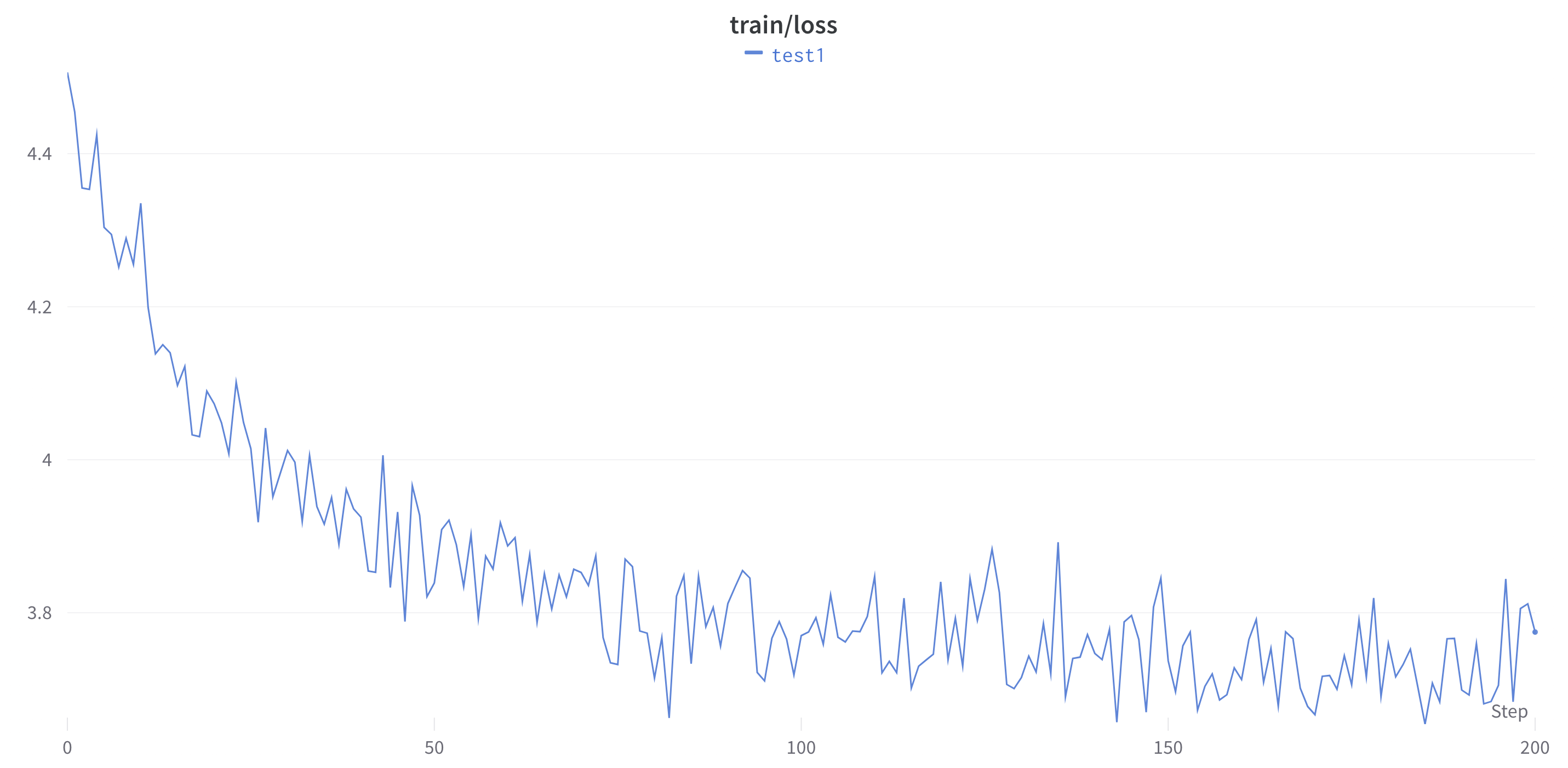
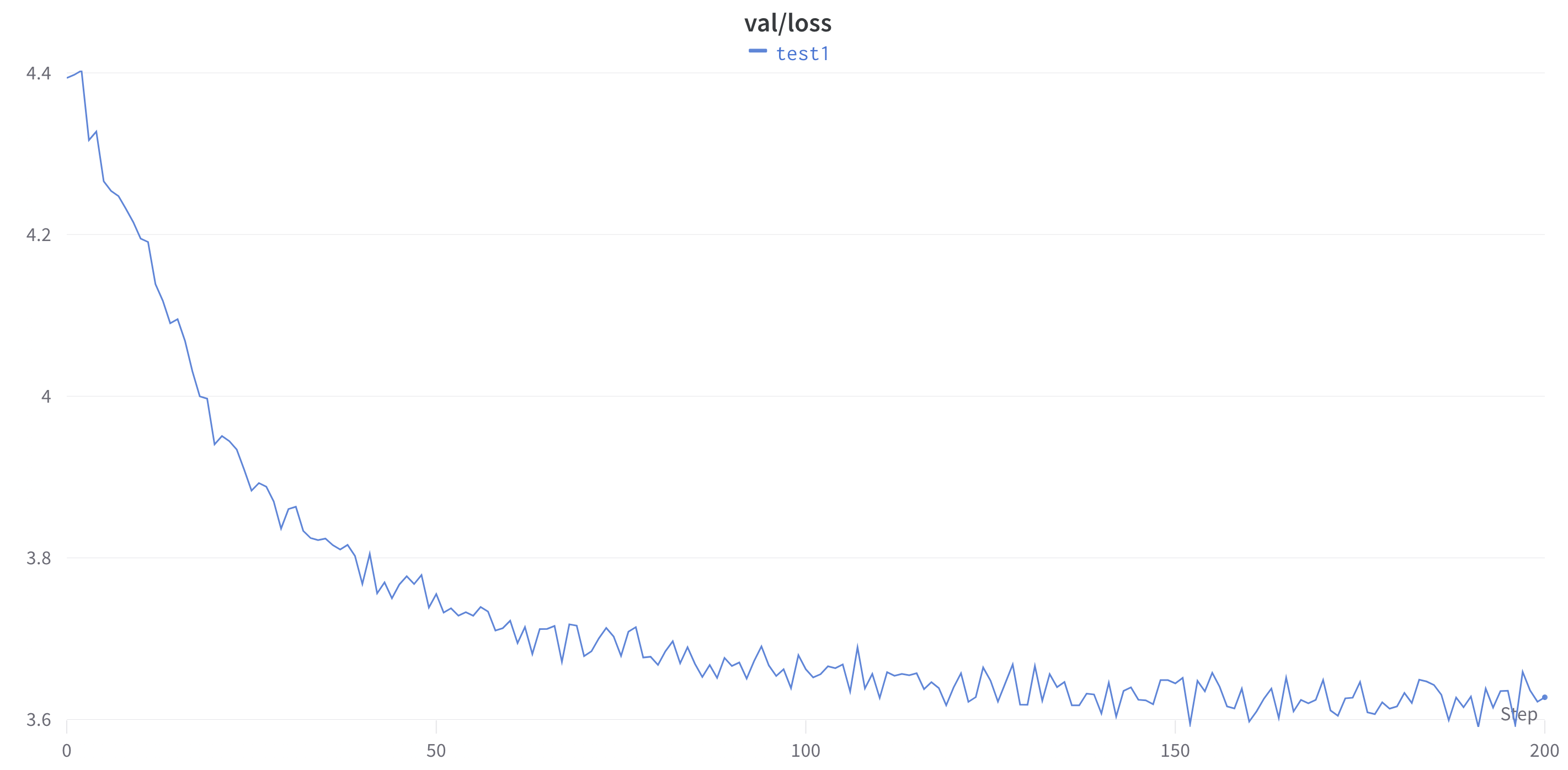
After 1,000 iterations, the validation loss has already stabilized, so we’ll consider the training to be complete. Training on my RTX 3090 was completed in ~170 min.
Testing
To test, I slightly modified the sample.py script, so it generates responses based on the prompt I provided.
"""
Sample from a trained model
"""
import os
import pickle
from contextlib import nullcontext
import torch
import tiktoken
from model import GPTConfig, GPT
promt = "Full Moon is shining\n"
# -----------------------------------------------------------------------------
init_from = 'resume' # either 'resume' (from an out_dir) or a gpt2 variant (e.g. 'gpt2-xl')
out_dir = 'out-haiku_1k' # ignored if init_from is not 'resume'
start = "\n" # or "<|endoftext|>" or etc. Can also specify a file, use as: "FILE:prompt.txt"
num_samples = 10 # number of samples to draw
max_new_tokens = 20 # number of tokens generated in each sample
temperature = 0.9 # 1.0 = no change, < 1.0 = less random, > 1.0 = more random, in predictions
top_k = 200 # retain only the top_k most likely tokens, clamp others to have 0 probability
seed = 1381
device = 'cuda' # examples: 'cpu', 'cuda', 'cuda:0', 'cuda:1', etc.
dtype = 'bfloat16' # 'float32' or 'bfloat16' or 'float16'
compile = False # use PyTorch 2.0 to compile the model to be faster
exec(open('configurator.py').read()) # overrides from command line or config file
# -----------------------------------------------------------------------------
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cuda.matmul.allow_tf32 = True # allow tf32 on matmul
torch.backends.cudnn.allow_tf32 = True # allow tf32 on cudnn
device_type = 'cuda' if 'cuda' in device else 'cpu' # for later use in torch.autocast
ptdtype = {'float32': torch.float32, 'bfloat16': torch.bfloat16, 'float16': torch.float16}[dtype]
ctx = nullcontext() if device_type == 'cpu' else torch.amp.autocast(device_type=device_type, dtype=ptdtype)
# model
if init_from == 'resume':
# init from a model saved in a specific directory
ckpt_path = os.path.join(out_dir, 'ckpt.pt')
checkpoint = torch.load(ckpt_path, map_location=device)
gptconf = GPTConfig(**checkpoint['model_args'])
model = GPT(gptconf)
state_dict = checkpoint['model']
unwanted_prefix = '_orig_mod.'
for k,v in list(state_dict.items()):
if k.startswith(unwanted_prefix):
state_dict[k[len(unwanted_prefix):]] = state_dict.pop(k)
model.load_state_dict(state_dict)
elif init_from.startswith('gpt2'):
# init from a given GPT-2 model
model = GPT.from_pretrained(init_from, dict(dropout=0.0))
model.eval()
model.to(device)
if compile:
model = torch.compile(model) # requires PyTorch 2.0 (optional)
# look for the meta pickle in case it is available in the dataset folder
load_meta = False
if init_from == 'resume' and 'config' in checkpoint and 'dataset' in checkpoint['config']: # older checkpoints might not have these...
meta_path = os.path.join('data', checkpoint['config']['dataset'], 'meta.pkl')
load_meta = os.path.exists(meta_path)
if load_meta:
print(f"Loading meta from {meta_path}...")
with open(meta_path, 'rb') as f:
meta = pickle.load(f)
# TODO want to make this more general to arbitrary encoder/decoder schemes
stoi, itos = meta['stoi'], meta['itos']
encode = lambda s: [stoi[c] for c in s]
decode = lambda l: ''.join([itos[i] for i in l])
else:
# ok let's assume gpt-2 encodings by default
print("No meta.pkl found, assuming GPT-2 encodings...")
enc = tiktoken.get_encoding("gpt2")
encode = lambda s: enc.encode(s, allowed_special={"<|endoftext|>"})
decode = lambda l: enc.decode(l)
# encode the beginning of the prompt
#if start.startswith('FILE:'):
# with open(start[5:], 'r', encoding='utf-8') as f:
# start = f.read()
start_ids = encode(promt)
x = (torch.tensor(start_ids, dtype=torch.long, device=device)[None, ...])
print('---------------')
# run generation
with torch.no_grad():
with ctx:
for k in range(num_samples):
y = model.generate(x, max_new_tokens, temperature=temperature, top_k=top_k)
print(decode(y[0].tolist()))
print('---------------')During text generation, I provided an initial text, “Full Moon is shining,” but did not stop the model at three lines, although I could have — often, interesting verses were longer than three lines. For comparison, I will first show the output of the original GPT-2-large on this prompt and then what I was able to generate.
GPT2-large initial output:
Full Moon is shining
At the end of the month
A beautiful woman is looking
at her face in (the mirror)
And one more:
Full Moon is shining
And it’s getting hard to say goodbye
To the days that were good and true
GPT2-large fine-tuned on haiku:
Full moon is shining
Like the blood, like the flames
To save you from the heart
I pray the fallen
And one more:
Full moon is shining
and when i see it
your eyes can’t hide my tears
one more time i will come
It can be observed that the content of the poems changes significantly — after fine-tuning the model, it produces more poetic expressions, more meaning in the words, and more allegories. One could even argue that there is a deeper meaning in the words, as should be the case in haiku.
Conclusions
GPT-2 is great for generating poetry — here, we can truly see the potential of this technology. Today there are models like GPT-3, which are much larger and have more “general” knowledge, but GPT-2 can be trained on a specific narrow task, fast and at home (in my case). And tools like nanoGPT repository can be great for fast training.
The scope for experimentation is only limited by your imagination, as the text input into the neural network is encoded as a sequence of numbers. Theoretically, one can train not only on text examples, but that’s a topic beyond the scope of this article.
Here is my fork of nanoGPT repository.
Opinions expressed by DZone contributors are their own.
Comments