A Guide to Vector Embeddings for Product and Software Engineers
This guide helps product and software engineers understand how vector embeddings are generated and how they can be effectively used in various applications.
Join the DZone community and get the full member experience.
Join For FreeVector embeddings are a powerful tool in artificial intelligence. They are mathematical (numerical) representations of words or phrases in a vector space. Usually processed by embedding models, these vector representations capture semantic relationships between words, allowing algorithms to understand the context and meaning of text. By analyzing the context in which a word appears, embeddings can capture its meaning and semantic relationships with other words.
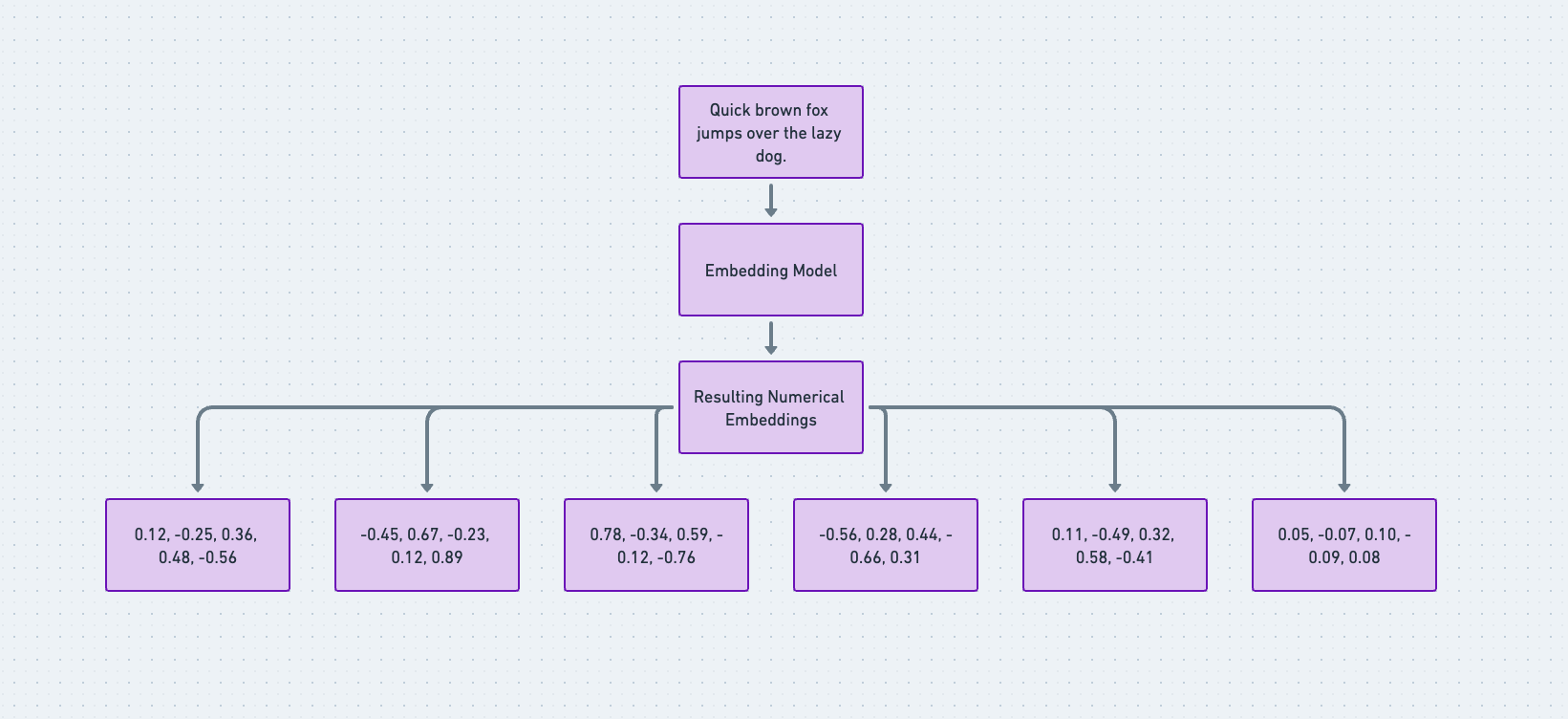
The Role of Embeddings and Vector Stores/Databases in Modern Applications
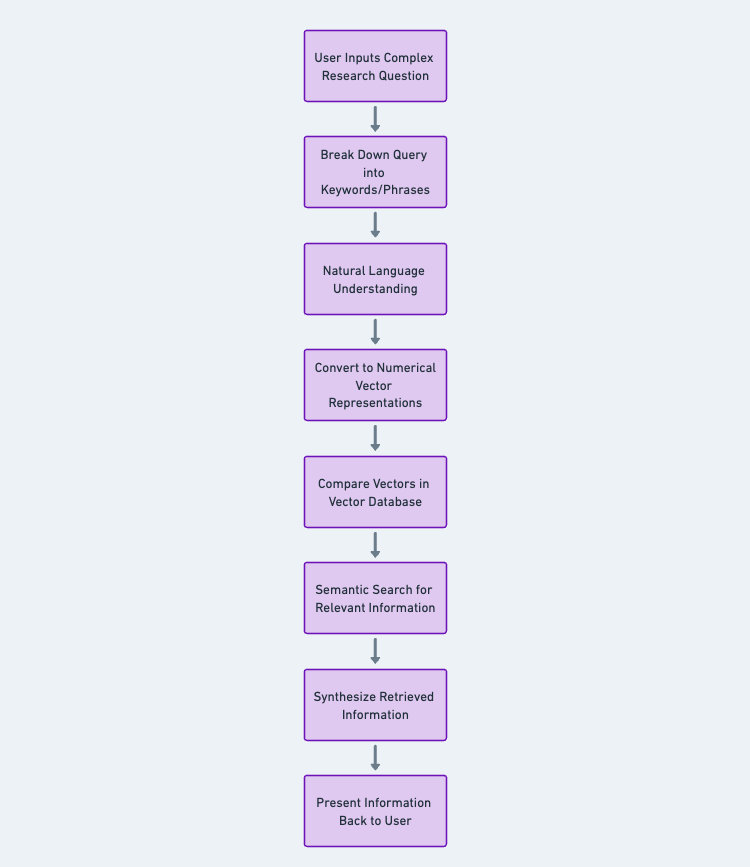
Embeddings are crucial for modern applications like recommendation systems, search engines, and natural language processing. They help understand user preferences, match search queries with relevant documents, and improve the accuracy of language-related tasks.
Alongside embeddings, vector databases play a crucial role in unlocking their power. Vector databases such as Pinecone and ChromaDB provide scalable and efficient storage and retrieval of vector embeddings. They allow for fast similarity searches among extensive collections of embeddings, enabling quick and accurate retrieval of relevant information. You can find a list of vector stores and databases you can use in your application.
Let's take the example of an AI-powered chat application to understand how these two things work. Developers can quickly retrieve relevant chat responses based on user queries by storing and indexing chat messages as vector embeddings in a vector database. These vector embeddings capture the contextual information of the conversation, allowing for coherent and consistent responses over a session. With its stateful interactions and real-time response capabilities, Pinecone can handle the conversational context and maintain the session state effectively in this scenario.
Implementing Embeddings in Your Projects
As a product or software engineer, you can incorporate embeddings into your projects in several ways. You can use pre-trained embedding models, such as ColBERT, Word2Vec, or GloVe, which have been trained on large corpora of text data and are readily available for use. Additionally, there are libraries and frameworks available that make it easier to implement and utilize embeddings in your projects. Here's a list of these open-source embedding models. If you're a Python developer, you can find a list of available sentence transformers (python-based embedders) on Huggingface.
Let's write a sample project using the latest openAI's text-embedding-3-small and text-embedding-3-large embedding models.
Step 1: Create a new folder and run the below command to set up the node project.
npm init -yStep 2: Install the openai package
npm install --save openaiStep 3: Create an index.js file and copy the below therein.
const { OpenAI} = require("openai");
const openai = new OpenAI({
apiKey: ""
});
async function main() {
const embedding = await openai.embeddings.create({
model: "text-embedding-3-small",
input: "Quick brown fox jumps over the lazy dog.",
encoding_format: "float",
});
console.log(embedding);
}
main();N.B. This is just for testing. Make sure you save your `openai key: process.env.OPENAI_API_KEY` in your .env for production environments.
Step 4: Run `node index.js`, and you'll see the embedding array and the number of tokens used.
{
object: 'list',
data: [ { object: 'embedding', index: 0, embedding: [Array] } ],
model: 'text-embedding-3-small',
usage: { prompt_tokens: 9, total_tokens: 9 }
}
Step 5: To access the vector embeddings generated from our prompt text, let's change `console.log(embedding);` to `console.log(embedding.data[0].embedding),` and you should see a huge array of embeddings like the one below:

Best Practices for Working With Embeddings
When working with embeddings, there are several best practices that product and software engineers can follow to maximize their effectiveness:
1. Choose the right embedding model: Various pre-trained embedding models are available, each with its strengths and weaknesses. Product and software engineers need to carefully select the embedding model that best suits their specific application, budget, and data.
2. Preprocess Your Data Effectively: Thoroughly clean and preprocess your text data to enhance the quality of your embeddings. This involves tokenization, stop word removal, and managing out-of-vocabulary words, amongst others. If you're using a framework for developing AI-based applications like Langchain, it comes with a suite of document loaders that will help you cleanly parse and preprocess your data sources.
3. Continuously update and evaluate your embeddings. Retrain them regularly with new data to keep them current and relevant. Also, consistently evaluate the performance of your embeddings in downstream tasks to ensure they effectively contribute to your application's goals. For example, you can get the latest performance benchmarks for text embedding models on the Massive Text Embedding Benchmark (MTEB) Leaderboard.
Conclusion
Incorporating vector embeddings into engineering solutions can unlock significant benefits for product and software engineers. By leveraging vector embeddings and their associated A.I. setups, product and software engineers can build more sophisticated and advanced AI-powered applications to deliver enhanced user experiences.
Opinions expressed by DZone contributors are their own.
Comments