A Deep Dive Into Apache Parquet With ClickHouse (Part 2)
Read about the internals of the Parquet format and how the ClickHouse integration exploits these structures, with recent improvements for speed and usability.
Join the DZone community and get the full member experience.
Join For FreeThis post is the second part of our Parquet and ClickHouse blog series. In this post, we explore the Parquet format in more detail, highlighting key details to consider when reading and writing files with ClickHouse. For more experienced Parquet users, we also discuss optimizations that users can make when writing Parquet files to maximize compression, as well as some recent developments to optimize read performance using parallelization.
For our examples, we continue to utilize the UK house price dataset. This contains data about prices paid for real estate property in England and Wales from 1995 to the time of writing. We distribute this in Parquet format in the public s3 bucket s3://datasets-documentation/uk-house-prices/parquet/. We read and write local and S3-hosted Parquet files using ClickHouse Local. ClickHouse Local is an easy-to-use version of ClickHouse that is ideal for developers who need to perform fast processing on local and remote files using SQL without having to install a full database server. Most importantly, ClickHouse Local and ClickHouse Server share the same code for Parquet reading and writing, so any details apply to both. For further details, see our previous post in this series and other recent dedicated content.
Parquet Format Overview
Structure
Understanding the Parquet file format allows users to make important decisions when writing files, which will directly impact the level of compression and subsequent read performance. The below description is a simplification but covers the details most users need.
The Parquet format relies on three principal concepts that are hierarchically related: row groups, column chunks, and pages.
At a high level, a Parquet file is separated into row groups. A row group contains up to N rows, determined at the time of writing.
Within each row group, we have a chunk per column - with each containing the data for its respective column and thus providing the column orientation. While it is theoretically possible for the number of rows to be different per column chunk, we assume this is identical for simplification. These chunks are composed of pages. It is within these data pages that the raw data is stored. The maximum size of each data page is potentially configurable but not currently exposed in ClickHouse, which uses the default value of 1MB. Data blocks are also compressed (see below) prior to writing.
We visualize these concepts and the logical structure below. For illustration purposes, we assume a row group size of 10, with 19 rows in total, each with three columns. We assume our data page size results in consistently three values per page (except for the last chunk on each page for the first-row group):
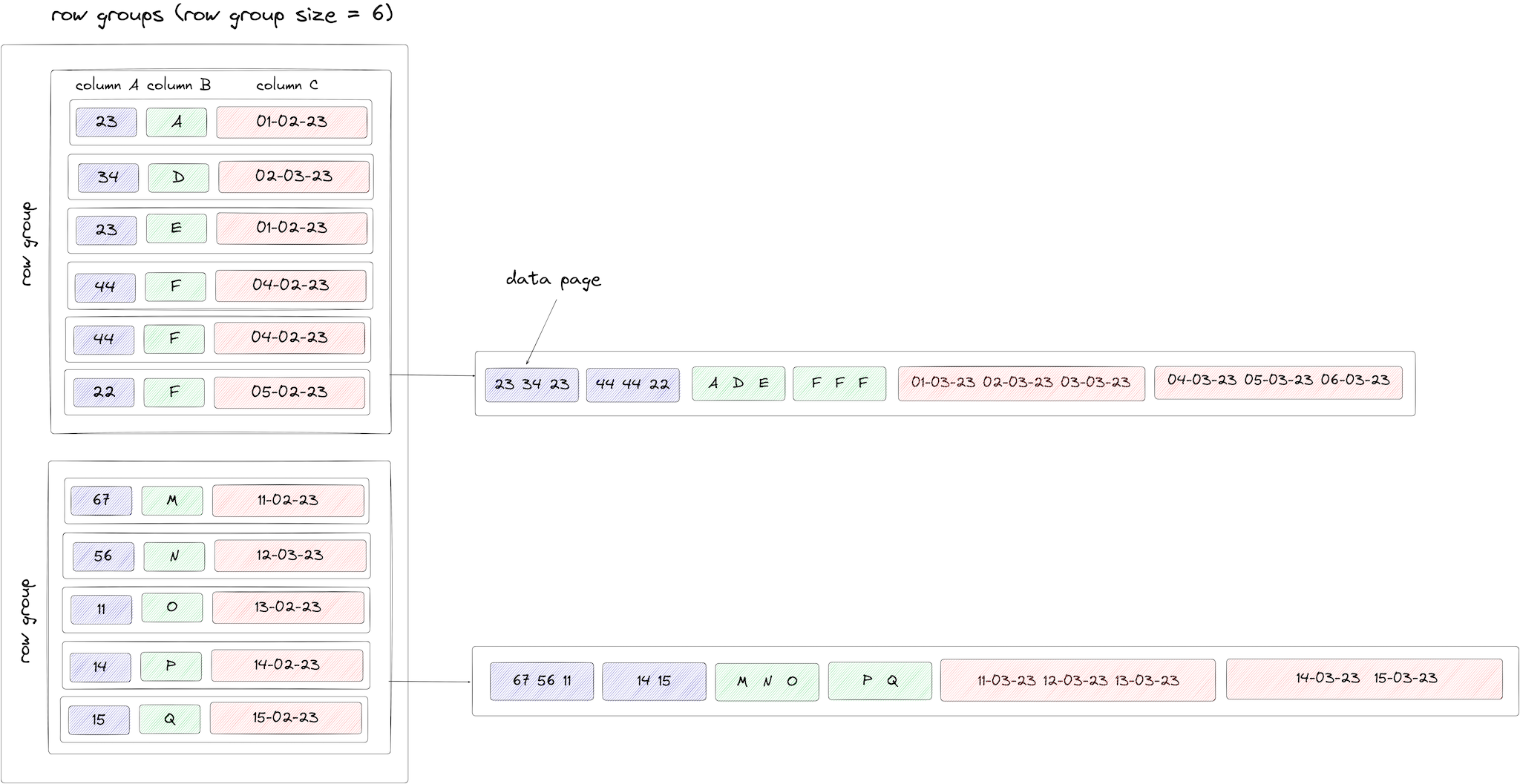
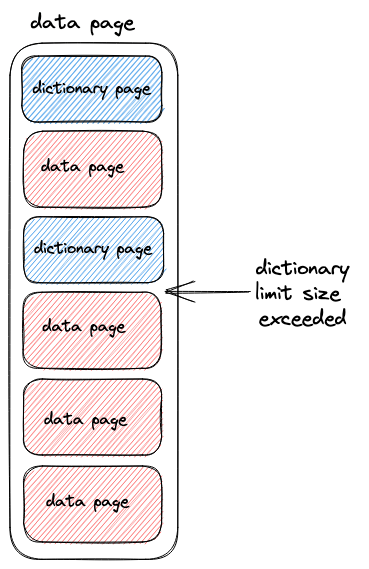
There are two types of pages: data pages and dictionary pages. Dictionary pages result when dictionary encoding is applied to values in a data page. For ClickHouse, this is enabled by default when Parquet files are written. For data pages that have been dictionary encoded, they will be preceded by the dictionary page. This effectively means dictionary and data pages alternate, as shown below. A limit can be imposed on the dictionary page size, which defaults to 1MB. If this is exceeded, the writer reverts to writing plain data pages containing the values.
The above is a simplification of the Parquet format. For users looking for a deeper understanding, we recommend reading about repetition and definition levels, as these are also essential in fully understanding how the data page works with respect to Arrays and Nested types as well as Null values.
Note that while Parquet is officially described as column-based, the introduction of row groups and the sequential storage of chunks of columns means it is often described as a Hybrid-base format. This allows readers of the format to easily implement projections and pushdowns as described below.
Metadata, Projections, and Pushdowns
In addition to storing data values, the Parquet format includes metadata. This is written at the end of the file in the footer to facilitate single-pass writing (more efficient) and includes references back to the row groups, chunks, and pages.
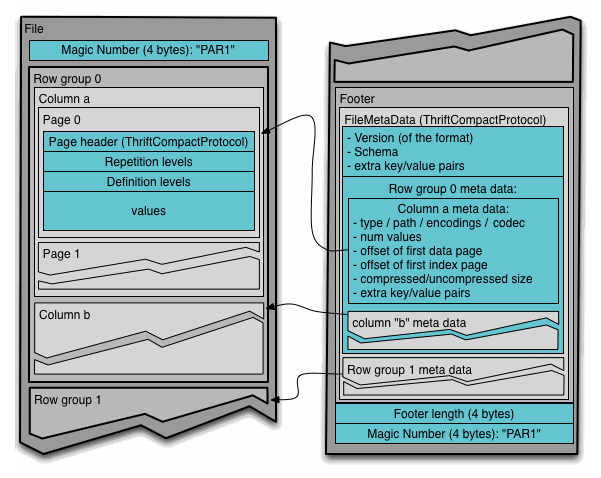
Credit: Parquet Apache
As well as storing the data schema and information to assist with decoding, e.g., offset values and encodings used, Parquet includes information that query engines can exploit to skip column chunks. A reader is first expected to read the file metadata to find all the column chunks they are interested in before only reading those required sequentially. This is known as a projection pushdown and is designed to minimize I/O.
Furthermore, statistics can be included at the row group level, describing each column's minimum and maximum value. This allows a reader to consider this information against any predicate (WHERE clause if querying in SQL), further skipping column chunks. This predicate pushdown is not currently implemented in ClickHouse but is planned for addition[1][2][3]. Finally, the official specification allows for separate metadata files referencing multiple Parquet files, e.g., one per column. ClickHouse doesn't currently support this, although we plan to add support.
Reading and Writing Row Groups
When writing Parquet files with ClickHouse, users may wish to control the number of row groups that are written to increase the amount of parallelization in reads — see “Parallelised Reads” for more details. As of the time of writing, we recommend users use the INSERT INTO FUNCTION <file/s3> syntax should they wish to control the number of row groups when writing. The settings for this syntax allow the number of row groups to be reasoned about easily, with the number of rows equal to the minimum of:
- min_insert_block_size_bytes: Sets the minimum number of bytes in the block, with smaller-sized blocks squashed into bigger ones. This effectively limits the number of rows by a size in bytes. Defaults to 256MB uncompressed.
- min_insert_block_size_rows: The minimum number of rows in the block that is passed to the arrow client, with smaller-sized blocks squashed into bigger ones. Defaults to 1m.
- output_format_parquet_row_group_size: Row group size in rows defaults to 1m.
Users can tune these values based on your total number of rows, their average size, and the target number of row groups.
For SELECT queries using the FORMAT clause, e.g., SELECT * FROM uk_price_paid FORMAT Parquet, as well as the INTO OUTFILE clause, the factors determining the group size are more complex. Most importantly, these approaches tend to result in a very large number of row groups in files — potentially negatively impacting compression and read performance. Further details can be found here. For these reasons, we currently recommend using the INSERT INTO FUNCTION approach.
The differences in these two approaches to exporting Parquet files can lead to varying file sizes depending on the approach and the resulting effective compression. For readers returning from our previous blog post, this addresses why different queries produced variable file sizes — smaller row group sizes don’t compress as well. In general, we recommend the INSERT INTO FUNCTION <file/s3> approach to writing as it utilizes more sensible defaults and allows row group sizes to be controlled easily. In future releases, we plan to address any inconsistencies in behavior.
Other tools, as well as the official Apache Arrow libraries (used by ClickHouse) for writing Parquet files, allow the number of row groups to also be configured. For how the row group size potentially can impact read performance.
Types and Encoding
Parquet is a binary format where column values are stored with a specific type of either boolean, numeric( int32, int64, int96, float, double), byte array(binary), or fixed length binary. These primitive types can be annotated with information specifying how they should be interpreted to create “logical types” such as String and Enum. For example, the logical String type is encoded in a byte array with an annotation indicating UTF8 encoding. See here for further details.
Since its initial inception, Parquet has had numerous extensions, not at least around how data can be encoded. This includes:
- Dictionary encoding builds a dictionary of all the distinct values of a column, replacing the original value with its respective index in the dictionary. This is particularly effective on low cardinality columns and helps deliver consistent performance across column types. This can be applied to numeric and byte array-based types.
- Dictionary-encoded values, booleans, and repetition and definition levels are Run Length Encoded (RLE). This compresses columns by replacing consecutive repeating values with one occurrence and a number indicating the repetition. In this case, higher compression is achieved when more of the same values occur consecutively. The cardinality of a column thus also directly impacts compression efficiency. Note that this RLE is combined with Bit Packing to minimize the number of bits required for storage.
- Delta encoding can be applied to integer values. In this case, the delta between values is stored instead of the real value (except the first value). This is particularly effective when consecutive values have small or constant variations, such as DateTime values with millisecond granularity, since the deltas occupy fewer bits.
- Other encoding techniques are also now available, including Byte Stream Split.
Currently, ClickHouse utilizes the default encodings when writing Parquet files, which enables dictionary encoding by default. The encoding used for a column cannot be controlled with settings, preventing the use of delta encoding for integers, although this is being considered as part of future improvements (see below).
Parquet types must be converted to ClickHouse types during reading and vice versa during writing. A full list of supported Parquet logical types and their equivalent ClickHouse type can be found here, with some pending implementation.
Strings
Files written by ClickHouse will also utilize the primitive BYTE_ARRAY type for strings. This is sufficient if you intend to later read these files with ClickHouse, as this aligns with our own internal representation of strings where bytes are stored as-is (with separate variations of functions that work under the assumption that the string contains a set of bytes representing a UTF-8 encoded text, e.g., lengthUTF8). However, some applications may require strings to be represented by the logical type String. In these cases, you can set the setting output_format_parquet_string_as_string= prior to writing files.
Enums
ClickHouse Enums will be serialized as Int8/Int16 when writing Parquet files in future versions of ClickHouse thanks to recent improvements (support is pending to allow them to be written as strings). Conversely, when reading files, these integer types can be converted to ClickHouse Enums. Strings in Parquet files will also be converted to ClickHouse Enums where possible. Parquet Enums can be read as either string or a compatible ClickHouse Enum.
Inspecting Parquet Structure
To inspect the structure of a Parquet file, users would historically need to use third-party tooling such as parquet-tools. With the pending 22.4 release of ClickHouse, users can obtain this metadata using a simple query thanks to the addition of the ParquetMetadata input format. We use this below to query the metadata for our house prices Parquet file, which outputs the metadata as a single row. To help readability, we also specify the output format PrettyJSONEachRow (also a 22.4 addition) and show only a sample of the metadata. Note how the output includes the number of row groups, encodings utilized, and column statistics such as sizes and compression rates.
./clickhouse local --query "SELECT * FROM file('house_prices.parquet', ParquetMetadata) FORMAT PrettyJSONEachRow"
{
"num_columns": "14",
"num_rows": "28113076",
"num_row_groups": "53",
"format_version": "2.6",
"metadata_size": "65503",
"total_uncompressed_size": "365131681",
"total_compressed_size": "255323648",
"columns": [
{
"name": "price",
"path": "price",
"max_definition_level": "0",
"max_repetition_level": "0",
"physical_type": "INT32",
"logical_type": "Int(bitWidth=32, isSigned=false)",
"compression": "LZ4",
"total_uncompressed_size": "53870143",
"total_compressed_size": "54070424",
"space_saved": "-0.3718%",
"encodings": [
"RLE_DICTIONARY",
"PLAIN",
"RLE"
]
},
...
],
"row_groups": [
{
"num_columns": "14",
"num_rows": "1000000",
"total_uncompressed_size": "10911703",
"total_compressed_size": "8395071",
"columns": [
{
"name": "price",
"path": "price",
"total_compressed_size": "1823285",
"total_uncompressed_size": "1816162",
"have_statistics": 1,
"statistics": {
"num_values": "1000000",
"null_count": "0",
"distinct_count": null,
"min": "50",
"max": "6250000"
}
},
...
]
},
...
]
}Compression
Parquet offers great compression relative to other interchange formats. This is illustrated below, where we compare the sizes of our house price dataset for CSV and line delimited JSON and Parquet with various compression techniques using their default settings. In this example, we export with no ORDER BY clause, relying on the natural ordering of ClickHouse (random, not deterministic), using ClickHouse Local and the file function.
INSERT INTO FUNCTION file('house_prices.<format>.<compression>') SELECT * FROM uk_price_paidhouse_prices.parquet.gzip. This will cause the Parquet file to be compressed again once written - an unnecessary overhead for which there will be minimal benefit.
Compression (level) |
CSV |
JSONEachRow |
Parquet |
None |
3.5 GB |
6.9 GB |
348 MB |
LZ4 (1) |
459 GB |
493 MB |
244 MB |
GZIP (6) |
417 MB |
481 MB |
183 MB |
ZSTD (1) |
388 MB |
434 MB |
196 MB |
Snappy |
Not Supported |
Not Supported |
241 MB |
XZ (6) |
321 MB |
321 MB |
Not Supported |
BZIP2 (6) |
233 MB |
248 MB |
Not Supported |
Brotli (1) |
360 MB |
400 MB |
174 MB |
As shown, Parquet, even without compression, is only 40% larger than the best text-based alternative of CSV with BZIP2. With Brotli compression, Parquet is 30% smaller than this compressed CSV. While BZIP2 achieves the best compression rates for text formats, this compression approach is also considerably slower. This is illustrated below, where we show the timings for the above (fastest of 3 runs). While this will be dependent on the ClickHouse implementation and hardware (Mac Pro 2021), Parquet is comparable to the write speeds of all compressed textual formats and experiences minimal overhead when compressing. Compared to the CSV with BZIP2, Parquet’s best compression (Brotli) is almost 10x faster. This compression technique is also twice as slow for Parquet as other formats, with ZSTD and GZIP offering similar compression to CSV with BZIP2 at over 25x the speed. Despite Parquet encoding currently being single-threaded (unlike text formatting), the format compares favorably regarding write performance. We expect future improvements to parallelize Parquet encoding to have a significant impact on these write timings.
Compression (level) |
CSV |
JSONEachRow |
Parquet |
None |
2.14 s |
4.68 s |
11.78 s |
LZ4 (1) |
16.6 s |
24.4 s |
12.4 s |
GZIP (6) |
14.1 s |
19.6 s |
17.56 s |
ZSTD (1) |
6.5 s |
11.3 s |
12.5 s |
Snappy |
Not Supported |
Not Supported |
12.3 s |
XZ (6) |
176 s |
173 s |
Not Supported |
BZIP2 (6) |
362.5 s |
837.8 s |
Not Supported |
Brotli (1) |
14.8 s |
23.7 s |
31.7 s |
Note: By default (23.3), ClickHouse utilizes LZ4 when compressing Parquet files (although this is subject to change due to compatibility with tooling such as Spark). This differs from the Apache Arrow default of Snappy, although this can be changed via the setting output_format_parquet_compression_method.
The above tests exclude the ClickHouse native format. If moving data between ClickHouse instances (e.g., in air-gapped environments) where a store-independent format is not required, we recommend this format with ZST compression. This will provide a file size comparable to Parquet while providing the fastest format for import into ClickHouse.INSERT INTO FUNCTION file('house_prices.native.zst') SELECT *
FROM uk_price_paid
-rw-r--r-- 1 dalemcdiarmid wheel 189M 26 Apr 14:44 house_prices.native.zstOrdering Data
An astute reader may have noticed that RLE encoding relies on consecutive values. Logically, this compression technique can thus be improved by simply ordering the data when writing using the ORDER BY query clause. This approach has its limitations if writing a large number of rows from a table since arbitrary sort orders can be memory bound: the amount of memory spent is proportional to the volume of data for sorting. The user has several options in this case:
- Utilize the setting
max_bytes_before_external_sort. If it is set to 0 (the default), external sorting is disabled. If it is enabled, when the volume of data to sort reaches the specified number of bytes, the collected data is sorted and dumped into a temporary file. This will be considerably slower than an in-memory sort. This value should be set conservatively and less than themax_memory_usagesetting. - If the
ORDER BYexpression has a prefix that coincides with the table sorting key, you can use theoptimize_read_in_ordersetting. This is enabled by default and means the ordering of the data is exploited, avoiding memory issues. Note that there are performance benefits to disabling this setting, specifically for queries with a large LIMIT and where many rows need to be read before the WHERE condition matches.
ORDER BY clause. Optimal compression is likely achieved when the column order places lower cardinality keys first in the ORDER BY clause (similar to ClickHouse), thus ensuring the most consecutive sequences of values.
Using the ORDER BY key of the UK house price table (postcode1, postcode2, addr1, addr2), we repeat our Parquet export using GZIP. This reduces our parquet file by around 20% to 148MB at the expense of write performance. Again, we can use the new ParquetMetadata to identify the compression of each column — below, we highlight the differences before and after sorting for the postcode1 column. Note how the uncompressed size of this column is dramatically reduced.
INSERT INTO FUNCTION file('house_prices-ordered.parquet') SELECT *
FROM uk_price_paid
ORDER BY
postcode1 ASC,
postcode2 ASC,
addr1 ASC,
addr2 ASC
0 rows in set. Elapsed: 38.812 sec. Processed 28.11 million rows, 2.68 GB (724.34 thousand rows/s., 69.07 MB/s.)
-rw-r--r-- 1 dalemcdiarmid wheel 148M 26 Apr 13:42 house_prices-ordered.parquet
-rw-r--r-- 1 dalemcdiarmid wheel 183M 26 Apr 13:44 house_prices.parquet./clickhouse local --query "SELECT * FROM file('house_prices.parquet', ParquetMetadata) FORMAT PrettyJSONEachRow"
{
"num_columns": "14",
"num_rows": "28113076",
"num_row_groups": "53",
"format_version": "2.6",
"metadata_size": "65030",
"total_uncompressed_size": "365131618",
"total_compressed_size": "191777958",
"columns": [{
"name": "postcode1",
"path": "postcode1",
"max_definition_level": "0",
"max_repetition_level": "0",
"physical_type": "BYTE_ARRAY",
"logical_type": "None",
"compression": "GZIP",
"total_uncompressed_size": "191694",
"total_compressed_size": "105224",
"space_saved": "45.11%",
"encodings": [
"RLE_DICTIONARY",
"PLAIN",
"RLE"
]
},
INSERT INTO FUNCTION file('house_prices-ordered.parquet') SELECT *
FROM uk_price_paid
ORDER BY
postcode1 ASC,
postcode2 ASC,
addr1 ASC,
addr2 ASC
./clickhouse local --query "SELECT * FROM file('house_prices-ordered.parquet', ParquetMetadata) FORMAT PrettyJSONEachRow"
{
"num_columns": "14",
"num_rows": "28113076",
"num_row_groups": "51",
"format_version": "2.6",
"metadata_size": "62305",
"total_uncompressed_size": "241299186",
"total_compressed_size": "155551987",
"columns": [
{
"name": "postcode1",
"path": "postcode1",
"max_definition_level": "0",
"max_repetition_level": "0",
"physical_type": "BYTE_ARRAY",
"logical_type": "None",
"compression": "GZIP",
"total_uncompressed_size": "29917",
"total_compressed_size": "19563",
"space_saved": "34.61%",
"encodings": [
"RLE_DICTIONARY",
"PLAIN",
"RLE"
]
},Parallelized Reads
Historically, the reading of Parquet files in ClickHouse was a sequential operation. This limited performance and meant users wishing to parallelize reads needed to split their Parquet files — ClickHouse will parallelize reads across a set of files where a glob pattern is provided in the path. This difference is shown below by computing the average price per year over one file vs. 29 (partitioned by year) using ClickHouse Local. All files here are written with GZIP and written using the ORDER BY key shown earlier, and we use the fastest of three runs.
SELECT
toYear(toDate(date)) AS year,
round(avg(price)) AS price,
bar(price, 0, 1000000, 80)
FROM file('house_prices.parquet')
GROUP BY year
ORDER BY year ASC
┌─year─┬──price─┬─bar(round(avg(price)), 0, 1000000, 80)─┐
│ 1995 │ 67937 │ █████▍ │
│ 1996 │ 71513 │ █████▋ │
│ 1997 │ 78538 │ ██████▎ │
│ 1998 │ 85443 │ ██████▊ │
│ 1999 │ 96040 │ ███████▋ │
│ 2000 │ 107490 │ ████████▌ │
│ 2001 │ 118892 │ █████████▌ │
│ 2002 │ 137957 │ ███████████ │
│ 2003 │ 155895 │ ████████████▍ │
│ 2004 │ 178891 │ ██████████████▎ │
│ 2005 │ 189361 │ ███████████████▏ │
│ 2006 │ 203533 │ ████████████████▎ │
│ 2007 │ 219376 │ █████████████████▌ │
│ 2008 │ 217043 │ █████████████████▎ │
│ 2009 │ 213423 │ █████████████████ │
│ 2010 │ 236115 │ ██████████████████▉ │
│ 2011 │ 232807 │ ██████████████████▌ │
│ 2012 │ 238385 │ ███████████████████ │
│ 2013 │ 256926 │ ████████████████████▌ │
│ 2014 │ 280024 │ ██████████████████████▍ │
│ 2015 │ 297285 │ ███████████████████████▊ │
│ 2016 │ 313548 │ █████████████████████████ │
│ 2017 │ 346521 │ ███████████████████████████▋ │
│ 2018 │ 351037 │ ████████████████████████████ │
│ 2019 │ 352769 │ ████████████████████████████▏ │
│ 2020 │ 377149 │ ██████████████████████████████▏ │
│ 2021 │ 383034 │ ██████████████████████████████▋ │
│ 2022 │ 391590 │ ███████████████████████████████▎ │
│ 2023 │ 365523 │ █████████████████████████████▏ │
└──────┴────────┴────────────────────────────────────────┘
29 rows in set. Elapsed: 0.182 sec. Processed 14.75 million rows, 118.03 MB (81.18 million rows/s., 649.41 MB/s.)
SELECT
toYear(toDate(date)) AS year,
round(avg(price)) AS price,
bar(price, 0, 1000000, 80)
FROM file('house_prices_*.parquet')
GROUP BY year
ORDER BY year ASC
…
29 rows in set. Elapsed: 0.116 sec. Processed 26.83 million rows, 214.63 MB (232.17 million rows/s., 1.86 GB/s.)The example here is with the file function, but this equally applies to the other table functions such as s3 (although factors will apply here — see “A small note on S3”). On larger files, this difference is likely to be more appreciable.
Fortunately, recent developments to parallelize this work within a file dramatically improve performance (although more can be done — see “Future Work”). These improvements are currently only relevant to s3 and URL functions and represent the first efforts at improving parallelization. Future versions of ClickHouse will parallelize the reading and decoding of a single Parquet file, including for the file function, with the number of threads controlled by the setting max_threads (defaults to the number of CPU cores). Below, we query the single Parquet file with the above query to highlight the difference in performance with and without the changes. Note these files are on s3 for which this recent improvement applies:
SELECT
toYear(toDate(date)) AS year,
round(avg(price)) AS price,
bar(price, 0, 1000000, 80)
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/uk-house-prices/parquet/house_prices_all.parquet')
GROUP BY year
ORDER BY year ASC
29 rows in set. Elapsed: 18.017 sec. Processed 28.11 million rows, 224.90 MB (1.56 million rows/s., 12.48 MB/s.)
//with changes
SET input_format_parquet_preserve_order = 0
SELECT
toYear(toDate(date)) AS year,
round(avg(price)) AS price,
bar(price, 0, 1000000, 80)
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/uk-house-prices/parquet/house_prices_all.parquet')
GROUP BY year
ORDER BY year ASC
29 rows in set. Elapsed: 8.428 sec. Processed 26.69 million rows, 213.49 MB (3.17 million rows/s., 25.33 MB/s.)As shown, performance here is considerably improved.
Importance of Row Groups
Parallelization here is achieved at a row group level. While the implementation is subject to change and further improvements, this improvement assigns a thread to each row group that is responsible for reading and decoding. To avoid excessive memory consumption, theinput_format_parquet_max_block_sizecontrols how much to decode at once per thread and thus determines the amount of uncompressed data held in memory. The ability to control this is useful for highly compressed data or when you have many threads, which can result in high memory usage.
Given parallelization is currently performed at the row group level, users may wish to consider the number of row groups in their files. As shown earlier, ClickHouse Local can be used to determine the number of row groups:
clickhouse@dclickhouse % ./clickhouse local --query "SELECT num_row_groups FROM file('house_prices.parquet', ParquetMetadata)"
53See earlier on how settings can be used to control the number of row groups when writing Parquet files with ClickHouse.
Therefore, you need at least as many row groups as cores for full parallelization. Below, we query a version of the house_price.parquet file, which has only a single row group — see here for how this was created. Note the impact on query performance.
SET input_format_parquet_preserve_order = 0
SELECT
toYear(toDate(date)) AS year,
round(avg(price)) AS price,
bar(price, 0, 1000000, 80)
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/uk-house-prices/parquet/house_prices-1-row-group.parquet')
GROUP BY year
ORDER BY year ASC
29 rows in set. Elapsed: 19.367 sec. Processed 26.64 million rows, 213.12 MB (1.05 million rows/s., 8.40 MB/s.)Conversely, a high number of row groups well beyond the number of cores is also likely to be detrimental to performance. This can potentially cause many tiny reads, increasing the amount of IO latency relative to actual decoding work. This will be most noticeable if only a few columns are read due to the fragmentation of reads. This can be mitigated when selecting all columns as adjacent reads will be coalesced. These behaviors will be most noticeable when reading with the s3 and URL functions (see “A small note on S3”). A balance between parallel decoding and efficient reading is therefore required. Row group sizes in the range of 100 KB to 10MB can be considered sensible sizes. With further testing, we hope our recommendations here can become more specific.
ClickHouse keeps the compressed data for each row group being read in memory (as well as the number of threads * input_format_parquet_max_block_size` for uncompressed data). Large row groups will, therefore, be memory intensive, especially when read with a high number of threads. In summary, defaults are usually sensible, but for machines with a large number of cores or in environments with low memory, users may consider ensuring row group counts are higher and their size aligns with available memory and the number of threads. If reading files, consider memory overhead if memory is low or if it is increasing max_threads.
Finally, note we earlier set the setting input_format_parquet_preserve_order = 0. The default value of 1 is for backward compatibility and ensures the data is returned in the original order, i.e., one-row group at a time. This limits how much work can be parallelized. This is subject to change, but for now, this change in behavior is required for maximum gains.
A Small Note on S3
While the parallel reading of Parquet files promises significant improvements for querying, other factors are also likely to impact the absolute query times experienced by users. If querying data that resides on S3, multiple files still bring significant benefits. For example, the s3Cluster function requires multiple files to distribute reads across all nodes in the cluster, with the initiator node creating a connection to all nodes in the cluster before dispatching each file that matches the glob pattern dynamically. This increases parallelization and performance. Region locality and network throughput of your server instance are also likely to significantly impact query performance.
We noted earlier the impact of small row groups (and thus small column chunks) on read performance. This can also potentially impact S3 charges. When requesting data from S3, a GET request is issued per column chunk. A larger row group size should, therefore, decrease the number of column chunks and resulting GET requests, potentially reducing costs. Again, this is mitigated when requesting consecutive columns, as requests will be coalesced and should be balanced against the potential for parallelized decoding. Users will need to experiment to optimize for cost/performance.
Multiple Files and Data Lake Formats
While Parquet has established itself as the data file format of choice for data lakes, tables would typically be represented as a set of files located in a bucket or folder. While ClickHouse can be used to read multiple Parquet files in a directory, it is typically only sufficient for ad-hoc querying. Managing large datasets becomes cumbersome and means table abstractions by tools such as ClickHouse are loosely established at best, with no support for schema evolution or write consistency. Most importantly for ClickHouse, this approach would rely on file listing operations - potentially expensive on object stores such as s3. Filtering of data requires all data to be opened and read, other than limited abilities to restrict files by using glob patterns on a naming schema.
Modern data formats such as Apache Iceberg aims to address these challenges by bringing SQL table-like functionality to files in a data lake in an open and accessible manner, including features such as:
- Schema evolution to track changes to a table over time
- The ability to create snapshots of data that define a specific version. These versions can be queried, allowing users to "time travel" between generations.
- Support for rolling back to prior versions of data quickly
- Automatic partitioning of files to assist with filtering — historically, users would need to do this error-prone task by hand and maintain it across updates.
- Metadata that query engines can use to provide advanced planning and filtering.
These table capabilities are usually provided by manifest files. These manifests maintain a history of the underlying data files with a complete description of their schema, partitioning, and file information. This abstraction allows for the support of immutable snapshots, organized efficiently in a hierarchical structure that tracks all changes in a table over time.
We defer an exploration of these file formats and how they can be used with ClickHouse to a later blog post. Stay tuned.
Conclusion and Future Work
This blog post has explored the Parquet format in detail, as well as important ClickHouse settings and considerations when reading and writing files. We also have highlighted recent developments concerning parallelization. We continue to evolve and improve our support for Parquet, with planned possible improvements including but not limited to:
- Exploiting metadata for conditions in any
WHEREclause will potentially dramatically improve the performance for queries containing range conditions, e.g., date filtering. This metadata can also be used to improve specific aggregation functions such as count. - On writing Parquet files, we currently don't allow the user to control the encoding used for columns, instead utilizing sensible defaults. Future improvements here would allow us to utilize other compression techniques, such as Delta for encoding for date time and numeric values or turning off dictionary encoding for specific columns.
- The Arrow API exposes several settings when writing files, including the ability to limit dictionary sizes. We welcome users' ideas on which of these would be worth exposing.
- Parallelizing reads is an ongoing effort with multiple low-level improvements possible [1][2]. We expect parallelizing encoding to have a significant impact on write performance.
- Our Parquet support is constantly improving. As well as addressing some inconsistencies in behavior highlighted in this blog, we plan other improvements, such as improving logical type support [1] and ensuring Null columns are correctly identified [2].
Published at DZone with permission of Dale McDiarmid. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments