What Is Static Code Analysis?
Static code analysis is the practice of examining application’s source, bytecode, or binary code without ever executing the program code itself. Instead, the code under review is analyzed to identify any defects, flaws, or vulnerabilities which may compromise the integrity or security of the application itself.
The roots for static code analysis actually pre-date the existence of computers and transistors themselves. In 1936, mathematician and computer scientist Alan Turing studied “the halting problem”, which determines whether an arbitrary computer program will finish running or continue to run forever, based upon an input source of data. Turing concluded that — while it is possible to provide specific input to cause a given program to halt, it is not possible to create a generic algorithm that applies to all such computer programs. It was at this point the concept of static code analysis was born.
However, it was not until forty-two years later (in 1978) when static code analysis options started to emerge as commercially available products. The first product to reach the market was called “lint”, a product of Stephen C. Johnson (AT&T Bell Laboratories). The term is a metaphorical reference to small programming errors that can result in big consequences — similar to small pieces of fabric which are caught in the lint trap of a drying machine used to launder clothes.
The lint program, originally examining C-based source code, processed in a manner more strictly than the C compiler to identify programming errors, bugs, code-style errors, and suspicious constructs. The lint program would also issue warning and error messages as well to assist the programmer.
Since the late 1970s, static code analysis tooling has continued to evolve and become part of the application security testing (AST) market segment. In fact, linters exist for most modern languages in use today, including interpreted languages (like JavaScript and Python), which do not contain a compiling phase.
Key Components of Static Code Analysis
Static code analysis solutions focus on one (or more) of the following aspects of the application under review:
- General vulnerability analysis
- Language and framework security
- Compliance
- End-to-end analysis
The illustration below provides a conceptual view of how these components work together, overlapping slightly, to protect the integrity of the source code being analyzed:
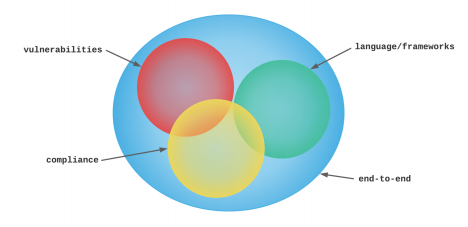
Static code analysis tools often do not focus on every aspect noted above, which is why categories of static code analysis were defined.
General Vulnerability Analysis
General vulnerability analysis includes the original work completed by the “lint” program, but has been expanded to include: logic flaws, hardcoded secrets, data leaks, authorization bypass, back doors, or logic bombs in the source code.
Language and Framework Security
The language and framework security component focuses on locating items such as: cross-site request forgery (unauthorized requests), session fixation (assume a valid user’s session), and clickjacking (tricking the user into clicking an element disguised as another) within a given application instance.
Compliance
The compliance component seeks potential violations with standards like: SOC 2 (Secure Data Management), PCI-DSS (Payment Card Industry/Data Security Standard), GDPR (EU General Data Protection Regulation), and CCPA (California Consumer Privacy Act).
End-to-End Analysis
The end-to-end component focuses on customer-facing client tier validation and can also include services and APIs that are available for end-user consumption. While the end-to-end component does not interact with the lower-level categorizations, the results of non-compliance for those categories may surface to this level.