This section will cover some of the common patterns — along with their respective anti-patterns — for Kafka Producer and Consumer APIs, Kafka Connect, and Kafka Streams.
Kafka Client API – Producer
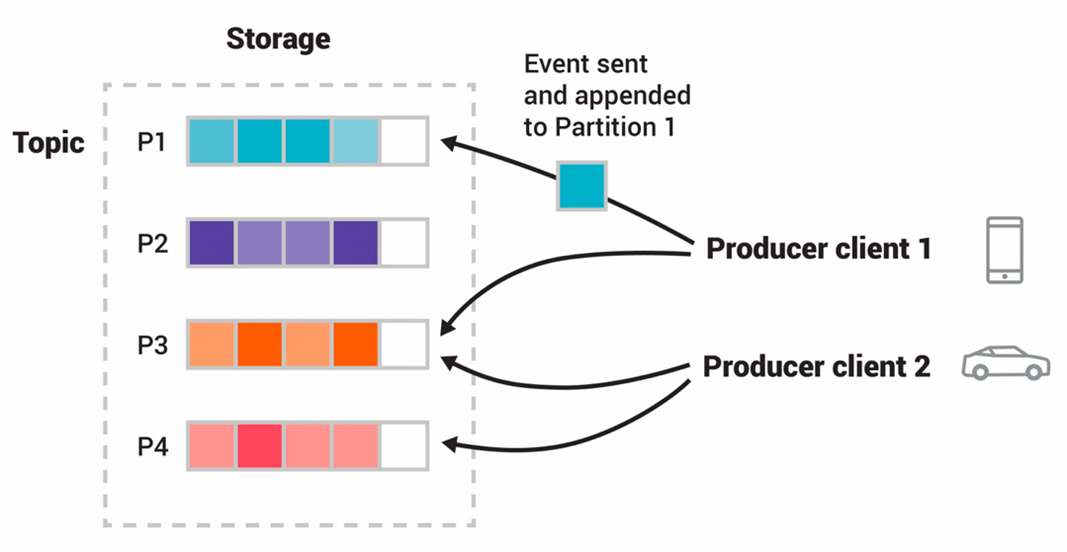
The Kafka Producer API sends data to topics in a Kafka cluster. Here are a couple of patterns and anti-patterns to consider:
Reliable Producer
|
Goal |
While producing a message, you want to ensure that it has been sent to Kafka. |
|
Pattern |
Use the acks=all Configuration for producer. |
|
Anti-Pattern |
Using the default configuration (acks = 1). |
The acks property allows producer applications to specify the number of acknowledgments that the leader node should have received before considering a request complete. If you don’t provide one explicitly, acks=1 is used by default. The client application will receive an acknowledgment as soon as the leader node receives the message and writes it to its local log. If the message has not yet been replicated to follower nodes and the current leader node, it will result in data loss.
If you set acks=all (or -1), your application only receives a successful confirmation when all the in-sync replicas in the cluster have acknowledged the message. There is a trade-off between latency and reliability/durability here: Waiting for acknowledgment from all the in-sync replicas will incur more time, but the message will not be lost as long as at least one of the in-sync replicas is available.
A related configuration is min.in.sync.replicas. Guidance on this topic will be covered later in this Refcard.
No More Duplicates
|
Goal |
The producer needs to be idempotent because your application cannot tolerate duplicate messages. |
|
Pattern |
Set enable.idempotence=true. |
|
Anti-Pattern |
Using a default configuration. |
It is possible that the producer application may end up sending the same message to Kafka more than once. Imagine a scenario where the message is actually received by the leader (and replicated to in-sync replicas if acks=all is used), but the application does not receive the acknowledgment from the leader due to request timeout, or maybe the leader node just crashed. The producer will try to resend the message — if it succeeds, you will end up with duplicate messages in Kafka. Depending upon your downstream systems, this may not be acceptable.
The Producer API provides a simple way to avoid this by using the enable.idempotence property (which is set to false by default). When set to true, the producer attaches a sequence number to every message. This is validated by the broker so that a message with a duplicate sequence number will get rejected.
From Apache Kafka 3.0 onwards, acks=all and enable.idempotence=true are set by default, thereby providing strong delivery guarantees for producer.
Kafka Client API – Consumer
With the Kafka Consumer API, applications can read data from topics in a Kafka cluster.
Idle Consumers Instances
|
Goal |
Scale out your data processing pipeline. |
|
Pattern |
Run multiple instances of your consumer application. |
|
Anti-Pattern |
Number of consumer instances is more than the number of topic partitions. |
A Kafka consumer group is a set of consumers that ingest data from one or more topics. The topic partitions are load-balanced among consumers in the group. This load distribution is managed on the fly when new consumer instances are added or removed from a consumer group. For example, if there are ten topic partitions and five consumers in a consumer group for that topic, Kafka will make sure that each consumer instance receives data from two topic partitions of the topic.
You can end up with a mismatch between the number of consumer instances and topic partitions. This could be due to incorrect topic configuration, wherein the number of partitions is set to one. Or, maybe your consumer applications are packaged using Docker and operated on top of an orchestration platform such as Kubernetes, which can, in turn, be configured to auto-scale them.
Keep in mind: You might end up with more instances than partitions. You need to be mindful of the fact that such instances remain inactive and do not participate in processing data from Kafka. Thus, the degree of consumer parallelism is directly proportional to the number of topic partitions. In the best-case scenario, for a topic with N partitions, you can have N instances in a consumer group, each processing data from a single topic partition.
Figure 2: Inactive consumers

Committing Offsets: Automatic or Manual?
|
Goal |
Avoid duplicates and/or data loss while processing data from Kafka. |
|
Pattern |
Set enable.auto.commit to false and use manual offset management. |
|
Anti-Pattern |
Using default configuration with automatic offset management. |
Consumers acknowledge the receipt (and processing) of messages by committing the offset of the message they have read. By default, enable.auto.commit is set to true for consumer apps, which implies that the offsets are automatically committed asynchronously (for example, by a background thread in the Java consumer client) at regular intervals (defined by auto.commit.interval.ms property that defaults to 5 seconds). While this is convenient, it allows for data loss and/or duplicate message processing.
Duplicate messages: Consider a scenario where the consumer app has read and processed messages from offsets 198, 199, and 200 of a topic partition — and the automatic commit process was able to successfully commit offset 198 but then crashed/shutdown after that. This will trigger a rebalance to another consumer app instance (if available), and it will look for the last committed offset, which in this case was 198. Hence, the messages at offsets 199 and 200 will be redelivered to the consumer app.
Data loss: The consumer app has read the messages for offsets 198, 199, and 200. The auto-commit process commits these offsets before the application is able to actually process these messages (perhaps through some transformation and store the result in a downstream system), and the consumer app crashes. In this situation, the new consumer app instance will see that the last committed offset is 200 and will continue reading new messages from thereon. Messages from offsets 198, 199, and 200 were effectively lost.
To have greater control over the commit process, you need to explicitly set enable.auto.commit to false and handle the commit process manually. The manual commit API offers synchronous and asynchronous options, and as expected, each of these has its trade-offs.
The code block below shows how to explicitly commit the offset for each message using the synchronous API:
try {
while(running) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(Long.MAX_VALUE));
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
System.out.println(record.offset() + ": " + record.value());
}
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));
}
}
} finally {
consumer.close();
}
Kafka Connect
Thanks to the Kafka Connect API, there are a plethora of ready-to-use connectors. But you need to be careful about some of its caveats:
Handling JSON Messages
|
Goal |
Read/write JSON messages from/to Kafka using Kafka Connect. |
|
Pattern |
Use a Schema Registry and appropriate JSON schema converter implementation. |
|
Anti-Pattern |
Embedding a schema with every JSON message or not enforcing a schema at all. |
Although JSON is a common message format, it does not have a strict schema associated with it. By design, Kafka producers and consumer apps are decoupled from each other. Imagine a scenario where your producer applications introduce additional fields to the JSON payload/events, and your downstream consumer applications are not equipped to handle that and hence fail — this can break your entire data processing pipeline.
For a production-grade Kafka Connect setup, it’s imperative that you use a Schema Registry to provide a contract between producers and consumers while still keeping them decoupled. For source connectors, if you want data to be fetched from an external system and stored in Kafka as JSON, you should configure the connector to point to a Schema Registry and also use an appropriate converter.
For example:
value.converter=<fully qualified class name of json schema converter implementation>
value.converter.schema.registry.url=<schema registry endpoint e.g. http://localhost:8081>
When reading data from Kafka topic, the sink connector also needs the same configuration as above.
However, if you are not using a Schema Registry, the next best option is to use JSON converter implementation, which is native to Kafka. In this case, you would configure your source and sink connectors as follows:
value.converter=org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable=true
Thanks to value.converter.schemas.enable=true, the source connector will add an embedded schema payload to each of your JSON messages, and the sink connector will respect that schema as well. An obvious drawback here is the fact that you have schema information in every message. This will increase the size of the message and can impact latency, performance, costs, etc. As always, this is a trade-off that you need to accept.
If the above is unacceptable, you will need to make a different trade-off with the following configuration:
value.converter=org.apache.kafka.connect.json.JsonConverter
value.converter.schemas.enable=false
Now, your JSON messages will be treated as ordinary strings, hence prone to the aforementioned risks to your data processing pipeline. Evolving the structure of your messages will involve scrutinizing and (re)developing your consumer apps to ensure they don’t break in response to changes — you need to constantly keep them in-sync (manually).
Another thing to be careful about is using the same configuration for both source and sink connectors. Not doing so will cause issues. For example, if you produce messages without a schema and use value.converter.schemas.enable=true in your sink configuration, Kafka Connect will fail to process those messages.
Error Handling in Kafka Connect
|
Goal |
Handle errors in your Kafka Connect data pipeline. |
|
Pattern |
Use a dead-letter queue. |
|
Anti-Pattern |
Using the default configuration, thereby ignoring errors. |
When you’re stitching together multiple systems using Kafka and building complex data processing pipelines, errors are inevitable. It’s important to plan on how you want to handle them, depending on your specific requirements. Apart from exceptional scenarios, you don’t want your data pipeline to terminate just because there was an error. But, by default, Kafka Connect is configured to do exactly that:
It does what it says and does not tolerate any errors — the Kafka Connect task shuts down as soon as it encounters an error. To avoid this, you can use:
But this is not useful in isolation. You should also configure your connector to use a dead-letter queue, a topic to which Kafka Connect can automatically route messages it failed to process. You just need to provide a name for that topic in the Kafka Connect config:
errors.tolerance=all
errors.deadletterqueue.topic.name=<name of the topic>
Since it’s a standard Kafka topic, you have flexibility in terms of how you want to introspect and potentially (re)process failed messages. Additionally, you would also want these to surface in your Kafka Connect logs. To enable this, add the following config:
An even better option would be to embed the failure reason in the message. All you need is to add this configuration:
errors.deadletterqueue.context.headers.enable=true
This will provide additional context and details about the error so that you can use it in your re-processing logic.
Kafka Streams
This section introduces some advanced options to help the Kafka Streams library for large-scale stream processing scenarios.
Rebalances and Their Impact on Interactive Queries
|
Goal |
Large state stores to minimize recovery/migration time during rebalance. |
|
Pattern |
Use standby replicas. |
|
Anti-Pattern |
Using the default configuration. |
Kafka Streams provides state stores to support stateful stream processing semantics — these can be combined with interactive queries to build powerful applications whose local state can be accessed externally (by an RPC layer such as HTTP or gRPC API).
These state stores are fault-tolerant since their data is replicated to changelog topics in Kafka, and updates to the state stores are tracked and kept up-to-date in Kafka. In case of failure or restart of a Kafka Streams app instance, new or existing instances fetch the state store data from Kafka. As a result, you can continue to query your application state using interactive queries.
However, depending on the data volume, these state stores can get quite large (in order of 10s of GBs). A rebalance event in such a case will result in a large amount of data being replayed and/or restored from the changelog topics — this can take a lot of time. However, during this timeframe, the state of your Kafka Streams apps in not available via interactive queries. It’s similar to a “stop-the-world” situation, during the JVM garbage collection. Depending upon your use case, the non-availability of state stores might be unacceptable.
To minimize the downtime in such cases, you can enable standby replicas for your Kafka Streams application. By setting thenum.standby.replicas config (defaults to 0), you can ask Kafka Streams to maintain additional instances that simply keep a backup of the state stores of your active app instances (by reading it from the changelog topics in Kafka). In case of rebalance due to restart or failure, these standby replicas act as “warm” backups and are available for serving interactive queries — this reduces the failover time duration.
Stream-Table Join in Kafka Streams
|
Goal |
Enrich streaming data in your Kafka Streams application. |
|
Pattern |
Use stream-table join. |
|
Anti-Pattern |
Invoking external data store(s) for every event in the stream. |
A requirement for stream processing apps is to be able to access an external SQL database often to enrich streaming data with additional information. For example, it will fetch customer details from an existing customer’s table to supplement and enrich the stream of order information.
The obvious solution is to query the database to get the information and add it to the existing stream record.
public Customer getCustomerInfo(String custID) {
//query customers table in a database
}
…..
KStream<String, Order> orders = builder.stream(“orders-topic”); //input KStream contains customer ID (String) and Order info (POJO)
//enrich order data
orders.forEach((custID, order) -> {
Customer cust = getCustomerInfo(custID);
order.setCustomerEmail(cust.getEmail());
});
orders.to(“orders-enriched-topic”); //write to new topic
This is not a viable choice, especially for medium- to large-scale applications. The latency incurred for the database invocation for each and every record in your stream will most likely create pressure on downstream applications and affect the overall performance SLA of your system.
The preferred way of achieving this is via a stream-table join.
First, you will need to source the data (and subsequent changes to it) in the SQL database into Kafka. This can be done by writing a traditional client application to query and push data into Kafka using the Producer API — but a better solution is to use a Kafka Connect connector such as JDBC source, or even better, a CDC-based connector such as Debezium.
Once the data is in Kafka topics, you can use a KTable to read that data into the local state store. This also takes care of updating the local state store since we have a pipeline already created wherein database changes will be sent to Kafka. Now, our KStream can access this local state store to enrich the streaming data with additional content — this is much more efficient than remote database queries.
KStream<String, Order> orders = ...;
KTable<String, Customer> customers = ...;
KStream<String, Order> enriched = orders.join(customers,
(order, cust) -> {
order.setCustomerEmail(cust.getEmail());
return order;
}
);
enriched.to(“orders-enriched-topic”);
General
The following patterns apply to Kafka in general and are not specific to Kafka Streams, Kafka Connect, etc.
Automatic Topic Creation – Boon or Bane?
|
Goal |
Use create topics, keeping reliability and high-availability in mind. |
|
Pattern |
Disable automatic topic creation and provide explicit configuration while creating topics. |
|
Anti-Pattern |
Relying on automatic topic creation. |
Kafka topic configuration properties (such as replication factor, partition count, etc.) have a server default that you can optionally override on a per-topic basis. In the absence of explicit configuration, the server default is used. This is why you need to be mindful of the auto.create.topics.enable configuration of your Kafka broker. It is set to true by default, and it creates topics with default settings such as:
- The replication factor is set to 1 — this is not good from a high-availability and reliability perspective. The recommended replication factor is 3 so that your system can tolerate the loss of two brokers.
- The partition count is set to 1 — this severely limits the performance of your Kafka client apps. For example, you can only have one instance of a consumer app (in a consumer group).
Keeping automatic topic creation enabled also means that you can end up with unwanted topics in your cluster. The reason is that topics (that don’t yet exist) referenced by a producer application and/or subscribed to by a consumer application will automatically get created.
Automatic topic creation creates topics with a cleanup policy set to delete. This means that if you wanted to create a log-compacted topic, you will be in for a surprise!
How Many In-Sync Replicas Do You Need?
|
Goal |
While producing a message, be sure that it has been sent to Kafka. |
|
Pattern |
Specify minimum in-sync replicas along with acks configuration. |
|
Anti-Pattern |
Only relying on acks configuration. |
When tuning your producer application for strong reliability, the min.insync.replicas configuration works hand in hand with the acks property (discussed earlier in this Refcard). It’s a broker-level configuration that can be overridden at the topic level and whose value is set to 1 by default.
As a rule of thumb, for a standard Kafka cluster with three brokers and a topic replication factor of 3, min.insync.replicas should be set to 2. This way, Kafka will wait for acknowledgment from two in-sync replica nodes (including the leader), which implies that you can withstand the loss of one broker before Kafka stops accepting writes (due to lack of minimum in-sync replicas).