Zero to AI Hero, Part 4: Harness Local Language Models With Semantic Kernel; Your AI, Your Rules
Explore how to harness local language models with Semantic Kernel. Discover the power of running AI on your terms — secure, private, and under your control.
Join the DZone community and get the full member experience.
Join For FreeWe have covered a lot of grounds in this series so far. If you are looking to start with Semantic Kernel, I highly recommend starting with Part 1. In this AI developer series, I write articles on AI developer tools and frameworks and provide working GitHub samples at the end of each one. We have already experimented with AI Agents, Personas, Planners, and Plugins. One common theme so far has been we have used an Open AI GPT-4o model deployed in Azure to do all our work. Now it is time for us to pivot and start using local models such as Phi-3 in Semantic Kernel so that you can build AI automation systems without any dependencies. This would also be a favorite solution for cyber security teams, as they don't need to worry about sensitive data getting outside of an organization's network. But I believe the happiest would be the indie hackers who want to save on cost and still have an effective Language Model that they can use without worrying about token cost and tokens per minute.
What Is the Small Language Model?
Small language models (SLMs) are increasingly becoming the go-to choice for developers who need robust AI capabilities without the baggage of heavy cloud dependency. These nimble models are designed to run locally, providing control and privacy that large-scale cloud models can’t match. SLMs like Phi-3 offer a sweet spot — they’re compact enough to run on everyday hardware but still pack enough punch to handle a range of AI tasks, from summarizing documents to powering conversational agents. The appeal? It’s all about balancing power, performance, and privacy. By keeping data processing on your local machine, SLMs help mitigate privacy concerns, making them a natural fit for sensitive sectors like healthcare, finance, and legal, where every byte of data matters.
Open-source availability is another reason why SLMs are catching fire in the developer community. Models like LLaMA are free to tweak, fine-tune, and integrate, allowing developers to mold them to fit specific needs. This level of customization means you can get the exact behavior you want without waiting for updates or approvals from big tech vendors. The pros are clear: faster response times, better data security, and unparalleled control. But it’s not all smooth sailing — SLMs do have their challenges. Their smaller size can mean less contextual understanding and a limited knowledge base, which might leave them trailing behind larger models in complex scenarios. They’re also resource-hungry; running these models locally can strain your CPU and memory, making performance optimization a must.
Despite these trade-offs, SLMs are gaining traction, especially among startups and individual developers who want to leverage AI without the cloud's costs and constraints. Their rising popularity is a testament to their practicality — they offer a hands-on, DIY approach to AI that’s democratizing the field, one local model at a time. Whether you’re building secure, offline applications or simply exploring the AI frontier from your own device, small language models are redefining what’s possible, giving developers the tools to build smarter, faster, and with more control than ever before.
I know that's a long introduction. But here is the gist you must know about SLMs:
- Small (e.g., Phi-3 small is just over 2GB)
- It can run on your laptop without the need for the internet (offline apps).
- Secure: Your data, documents, etc, are not traveling over the wire.
- Open source — mostly
- Control: If necessary, fine-tuning can be done locally. Developers like the feeling of being in control, don't they?
- You pay nothing (my favorite). Of course, you need hardware, but that's about it. You don't have to pay for tokens sent or received.
What Do SLMs Like Phi-3 Have To Do with Semantic Kernel and Ollama?
Semantic Kernel doesn't care about the model underneath. It can talk to a local Phi-3 with the same enthusiasm as speaking with an Azure-hosted GPT-4o. For this article, even though we will focus on Phi-3, you can replace it with any of the models available in the model directory of Ollama.
Think of Ollama as a Docker for AI models designed to simplify the download, management, and deployment of SLMs. With a simple command-line interface, Ollama lets you pull models and get them running in minutes, giving you complete control over your data and environment — no more privacy worries or latency issues. This tool is a game-changer for developers who need fast, secure, and cost-effective AI solutions, whether you’re building offline apps, experimenting with new models, or working in data-sensitive fields. Ollama makes it easy to keep AI close to home, where it belongs.
Enough talk. Let's write some code. Before that, let's take a few small steps to get Ollama up and running on our machine.
Set Up Phi-3 With Ollama
1. Download Ollama
Head over to the Ollama website and download the latest version suitable for your operating system.
2. Install Ollama
Follow the installation instructions for your OS (Windows, macOS, or Linux). Once installed, open your terminal and boot up Ollama with:
ollama serve
3. Download Phi-3 Model
With Ollama installed, pull the Phi-3 model using the following command:
ollama pull phi3
4. Run Phi-3
Start the Phi-3 model on your local machine with:
ollama run phi3
5. Test Phi-3
Ask something.
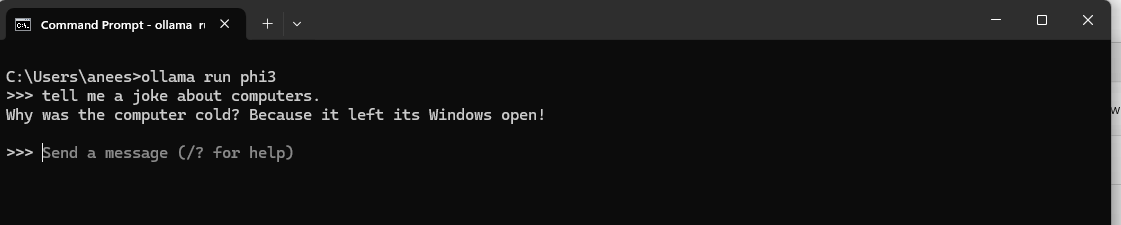
6. Works
We have AI on our computer. Cool!
This setup makes Phi-3 ready to serve as a local language model, waiting for instructions from applications like Semantic Kernel.
Let’s Connect Our Local Phi-3 With Semantic Kernel
Now that we have downloaded Phi-3 and it is available on our computer, it's time to talk to it using the Semantic Kernel. As usual, let's start with code first.
using Microsoft.SemanticKernel;
# pragma warning disable SKEXP0010
var builder = Kernel.CreateBuilder();
builder.AddOpenAIChatCompletion(
modelId: "phi3",
apiKey: null,
endpoint: new Uri("http://localhost:11434")
);
var kernel = builder.Build();
Console.Write("User: ");
var input = Console.ReadLine();
var response = await kernel.InvokePromptAsync(input);
Console.WriteLine(response.GetValue<string>());
Console.WriteLine("------------------------------------------------------------------------");
Console.ReadLine();
Where is the apiKey? Surprise — there is none. We are just hooking up with a local model; we don't need an API or an API key. What is the localhost:11434 endpoint, then? The Ollama is running at this port, and our local models (yes, more than one if we downloaded and installed more) are running here. Can we get rid of the localhost and just run the local model from a file? Yes, we can. We will look into this in another part of this series.
Let's run our code and see what happens.

I didn't get Phi-3's joke (bad joke?), but you got the idea. Semantic Kernel was able to use the local SLM we put in place to do some ChatGPT-type stuff. Cool, isn't it?
Though we covered a lot of ground on Small Language Models and their local availability, we didn't make it do much like our trip planner. That's because function calling is not yet available on Phi-3 (as of this writing), and hopefully, it will be added in the future. Does this mean that we are limited? No. We can choose models like llama3.1 or mistral-nemo from the Ollama library, which supports tools (in other words, function calling). However, these are a bit heavier than the Phi-3 mini and weigh upwards of 5GBs.
Like other articles in the series, I have provided a working sample, which you can find on GitHub. You may clone it, and it should run seamlessly after you set up Ollama and Phi-3, as described in the article.
Wrap Up
In this article, we explored the exciting intersection of Phi-3 and Semantic Kernel, highlighting how local language models are becoming essential tools in the AI toolkit. Integrating these models with Semantic Kernel opens new avenues for creating secure, high-performance applications that keep your data private and your AI flexible. As the AI landscape continues shifting towards local, privacy-first solutions, tools like Phi-3 and Semantic Kernel are paving the way for developers to build more innovative, responsive applications.
What's Next?
We have covered a lot of ground with Semantic Kernel but never explored beyond console apps. It is time to build an SK solution as an aspnetcore API, callable from a front-end app, and use the semantic kernel to answer users' questions and leave them in awe! Also, since we started with local models, it would be nice to try building agents with a local model that supports tools and plan our day trip without consuming the costs for tokens. On another note, we forgot to talk about LM Studio, another powerful tool we should explore if we want to travel further in the local model path. You are in for a treat as we explore further this developer's AI hero journey.
Opinions expressed by DZone contributors are their own.
Comments