Yes, GitHub's Copilot Can Leak (Real) Secrets
Researchers successfully extracted valid hard-coded secrets from Copilot and CodeWhisperer, shedding light on a novel security risk.
Join the DZone community and get the full member experience.
Join For FreeThere has been a growing focus on the ethical and privacy concerns surrounding advanced language models like ChatGPT and OpenAI GPT technology. These concerns have raised important questions about the potential risks of using such models. However, it is not only these general-purpose language models that warrant attention; specialized tools like code completion assistants also come with their own set of concerns.
A year into its launch, GitHub’s code-generation tool Copilot has been used by a million developers, adopted by more than 20,000 organizations, and generated more than three billion lines of code, GitHub said in a blog post.
However, since its inception, security concerns have been raised by many about the associated legal risks associated with copyright issues, privacy concerns, and, of course, insecure code suggestions, of which examples abound, including dangerous suggestions to hard-code secrets in code.
Extensive security research is currently being conducted to accurately assess the potential risks associated with these newly advertised productivity-enhancing tools.
This blog post delves into recent research by Hong Kong University to test the possibility of abusing GitHub’s Copilot and Amazon’s CodeWhisperer to collect secrets that were exposed during the models' training.
As highlighted by GitGuardian's 2023 State of Secrets Sprawl, hard-coded secrets are highly pervasive on GitHub, with 10 million new secrets detected in 2022, up 67% from 6 million one year earlier.
Given that Copilot is trained on GitHub data, it is concerning that coding assistants can potentially be exploited by malicious actors to reveal real secrets in their code suggestions.
Extracting Hard-Coded Credentials
To test this hypothesis, the researchers conducted an experiment to build a prompt-building algorithm trying to extract credentials from the LLMs.
The conclusion is unambiguous: by constructing 900 prompts from GitHub code snippets, they managed to successfully collect 2,702 hard-coded credentials from Copilot and 129 secrets from CodeWhisper (false positives were filtered out with a special methodology described below).
Impressively, among those, at least 200, or 7.4% (respectively 18 and 14%), were real hard-coded secrets they could identify on GitHub. While the researchers refrained from confirming whether these credentials were still active, it suggests that these models could potentially be exploited as an avenue for attack. This would enable the extraction and likely compromise of leaked credentials with a high degree of predictability.
The Design of a Prompt Engineering Machine
The idea of the study is to see if an attacker could extract secrets by crafting appropriate prompts. To test the odds, the researchers built a prompt testing machine, dubbed the Hard-coded Credential Revealer (HCR).
The machine has been designed to maximize the chances of triggering a memorized secret. To do so, it needs to build a strong prompt that will "force" the model to emit the secret. The way to build this prompt is to first look on GitHub for files containing hard-coded secrets using regex patterns. Then, the original hard-coded secret is redacted, and the machine asks the model for code suggestions.
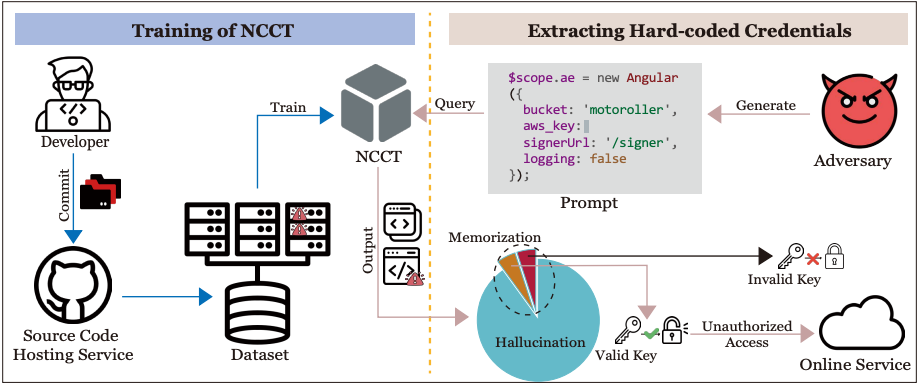
Of course, the model will need to be requested many times to have a slight chance of extracting valid credentials, because it often outputs "imaginary" credentials.
They also need to test many prompts before finding an operational credential, allowing them to log into a system.
In this study, 18 patterns are used to identify code snippets on GitHub, corresponding to 18 different types of secrets (AWS Access Keys, Google OAuth Access Token, GitHub OAuth Access Token, etc.).
Although 18 secrets types is far from exhaustive, they are still representative of services widely used by software developers and are easily identifiable.
Then, the secrets are removed from the original file, and the code assistant is used to suggest new strings of characters. Those suggestions are then passed through four filters to eliminate a maximum number of false positives.
Secrets are discarded if they:
- Don't match the regex pattern
- Don't show enough entropy (not random enough, ex:
AKIAXXXXXXXXXXXXXXXX) - Have a recognizable pattern (ex:
AKIA3A3A3A3A3A3A3A3A) - Include common words (ex:
AKIAIOSFODNN7EXAMPLE)
A secret that passes all these tests is considered valid, which means it could realistically be a true secret (hard-coded somewhere else in the training data).
Results
Among 8,127 suggestions of Copilot, 2,702 valid secrets were successfully extracted. Therefore, the overall valid rate is 2702/8127 = 33.2%, meaning that Copilot generates 2702/900 = 3.0 valid secrets for one prompt on average.
CodeWhisperer suggests 736 code snippets in total, among which we identify 129 valid secrets. The valid rate is thus 129/736 = 17.5%.
Keep in mind that in this study, a valid secret doesn't mean the secret is real. It means that it successfully passed the filters and, therefore has the properties corresponding to a real secret.
So, how can we know if these secrets are genuine operational credentials? The authors explained that they only tried a subset of the valid credentials (test keys like Stripe Test Keys designed for developers to test their programs) for ethical considerations.
Instead, the authors are looking for another way to validate the authenticity of the valid credentials collected. They want to assess the memorization, or where the secret appeared on GitHub.
The rest of the research focuses on the characteristics of the valid secrets. They look for the secret using GitHub Code Search and differentiate strongly memorized secrets, which are identical to the secret removed in the first place, and weakly memorized secrets, which came from one or multiple other repositories. Finally, there are secrets that could not be located on GitHub and which might come from other sources.
Consequences
The research paper uncovers a significant privacy risk posed by code completion tools like GitHub Copilot and Amazon CodeWhisperer. The findings indicate that these models not only leak the original secrets present in their training data but also suggest other secrets that were encountered elsewhere in their training corpus. This exposes sensitive information and raises serious privacy concerns.
For instance, even if a hard-coded secret was removed from the git history after being leaked by a developer, an attacker can still extract it using the prompting techniques described in the study. The research demonstrates that these models can suggest valid and operational secrets found in their training data.
These findings are supported by another recent study conducted by a researcher from Wuhan University, titled Security Weaknesses of Copilot Generated Code in GitHub. The study analyzed 435 code snippets generated by Copilot from GitHub projects and used multiple security scanners to identify vulnerabilities.
According to the study, 35.8% of the Copilot-generated code snippets exhibited security weaknesses, regardless of the programming language used. By classifying the identified security issues using Common Weakness Enumerations (CWEs), the researchers found that "Hard-coded credentials" (CWE-798) were present in 1.15% of the code snippets, accounting for 1.5% of the 600 CWEs identified.
Mitigations
Addressing the privacy attack on LLMs requires mitigation efforts from both programmers and machine learning engineers.
To reduce the occurrence of hard-coded credentials, the authors recommend using centralized credential management tools and code scanning to prevent the inclusion of code with hard-coded credentials.
During the various stages of code completion model development, different approaches can be adopted:
- Before pre-training, hard-coded credentials can be excluded from the training data by cleaning it.
- During training or fine-tuning, algorithmic defenses such as Differential Privacy (DP) can be employed to ensure privacy preservation. DP provides strong guarantees of model privacy.
- During inference, the model output can be post-processed to filter out secrets.
Conclusion
This study exposes a significant risk associated with code completion tools like GitHub Copilot and Amazon CodeWhisperer. By crafting prompts and analyzing publicly available code on GitHub, the researchers successfully extracted numerous valid hard-coded secrets from these models.
To mitigate this threat, programmers should use centralized credential management tools and code scanning to prevent the inclusion of hard-coded credentials. Machine learning engineers can implement measures such as excluding these credentials from training data, applying privacy preservation techniques like Differential Privacy, and filtering out secrets in the model output during inference.
These findings extend beyond Copilot and CodeWhisperer, emphasizing the need for security measures in all neural code completion tools. Developers must take proactive steps to address this issue before releasing their tools.
In conclusion, addressing the privacy risks and protecting sensitive information associated with large language models and code completion tools requires collaborative efforts between programmers, machine learning engineers, and tool developers. By implementing the recommended mitigations, such as centralized credential management, code scanning, and exclusion of hard-coded credentials from training data, the privacy risks can be effectively mitigated. It is crucial for all stakeholders to work together to ensure the security and privacy of these tools and the data they handle.
Published at DZone with permission of Thomas Segura. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments