Writing Simple REST Clients for Azure Search
How to write a REST client to call Azure Search in Java.
Join the DZone community and get the full member experience.
Join For Freein my last blog post about rest clients " why azure rest apis and how to prepare for using them? " i explained how to write a simple base class for azure rest apis. in this post, we will implement a simple rest client for azure search. this is the same code that i'm using in my beer store sample application. i also make some notes about how to use search clients in domain models.
planning search indexes is important part of successful search in every system. to get started with planning of search indexes on azure search, feel free to read my blog post planning and creating azure search indexes that uses same product catalogue stuff that i use here.
getting started with the azure search client
first, let's focus on some azure search specifics. to make requests to azure search rest api end-points we need the following information to be available for our client:
- api version : the version of api we are consuming (if we don’t specify correct version then we cannot be sure if api interface is the one we expect).
- service name : name of our search service, part of api url.
- admin key : this is the key to validate that request is coming from valid source.
the code that uses our azure search rest client must provide these values to us because our rest client does'’t deal with configuration settings.
we'll use the rest client base class from my blog post " why azure rest apis and how to prepare for using them? " in its most primitive form, our rest client for azure search looks like this:
public class restclient : restclientbase
{
private const string _apiversion = "2015-02-28";
private readonly string _adminkey;
private readonly string _servicename;
public restclient(string servicename, string adminkey)
{
_servicename = servicename;
_adminkey = adminkey;
}
public override void addheaders(httprequestheaders headers)
{
headers.add("api-key", _adminkey);
}
}
the addheaders() method is defined in the base class. with this method, we add search-specific headers to the headers collection. this method is called by the base class when it builds http requests for search service calls. the api version and service name are used in search methods later.
updating product index
search is only useful when there is data in search index and therefore we start with product indexing. we create data transfer object (dto) for search index update. by structure this dto is simple – it has product properties and some additional properties to tell azure search what product it is and what we want to do with it.
[datacontract]
public class productupdatedto
{
[datamember(name = "@search.action")]
public string searchaction { get; set; }
[datamember(name = "id")]
public string id { get; set; }
[datamember]
public string name { get; set; }
[datamember]
public string shortdescription { get; set; }
[datamember]
public string description { get; set; }
[datamember]
public decimal price { get; set; }
[datamember]
public int productcategoryid { get; set; }
[datamember]
public double? alcvol { get; set; }
[datamember]
public string imageurl { get; set; }
[datamember]
public string[] alcvoltags { get; set; }
[datamember]
public string manufacturername { get; set; }
public productupdatedto()
{
alcvoltags = new string[] { };
}
}
and here is the rest client method that sends products to the search index:
public async task<indexitemsresponse> indexproduct(productupdatedto dto)
{
var url = string.format("https://{0}.search.windows.net/indexes/products/docs/index", _servicename);
url += "?api-version=" + _apiversion;
var producttosave = new { value = new productupdatedto[] { dto } };
var productjson = jsonconvert.serializeobject(producttosave);
var result = await download<indexitemsresponse>(url, httpmethod.post, productjson);
return result;
}
one thing to notice: search api methods that update or maintain indexes will also return a response with data when called. when updating an index, we can update multiple items with the same call, and this is why the response has multiple response values. to represent it in object-oriented code we need two classes — one for response object and one for each products indexing result:
[datacontract]
public class indexitemsresponse
{
[datamember(name = "value")]
public indexitemresponse[] items { get; set; }
}
[datacontract]
public class indexitemresponse
{
[datamember(name = "key")]
public string key { get; set; }
[datamember(name = "status")]
public bool status { get; set; }
[datamember(name = "errormessage")]
public string errormessage { get; set; }
}
now we have an azure search client with one method that indexes products. i skipped some architectural stuff here to keep the post smaller. in a real scenario, you should have some domain-level service interface for searches and at least one implementation class. this class knows the specifics of a given search client and mapping data from domain classes to search dtos also happens there.
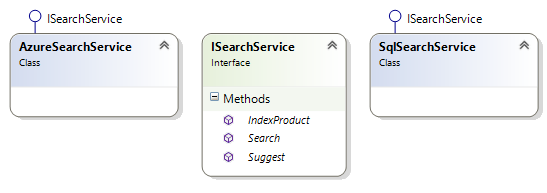
also, you can have more than one implementation if you introduce a search service interface. if you have to switch from one search service to another, then you just have to write a new implementation and make minor modifications to your dependency injection code.
searching from product index
now let's implement searching. we are using same request-and-response interface classes as before, but now we create classes for search. we'll start with a query class. the only purpose of this class is to move query parameters from the client layers to domain services and data layers. i also define abstract query base class because some things are common for almost all queries in a system.
public abstract class basequery
{
public int page { get; set; }
public int pagesize { get; set; }
public string orderby { get; set; }
public bool ascending { get; set; }
public basequery()
{
page = 1;
pagesize = 10;
ascending = true;
}
}
public class productquery : basequery
{
public int? productcategoryid { get; set; }
public int? producttypeid { get; set; }
public string term { get; set; }
public int? alcvolmin { get; set; }
public int? alcvolmax { get; set; }
public decimal? minprice { get; set; }
public decimal? maxprice { get; set; }
}
as you can see, all queries inheriting from the basequery class have some paging and ordering readiness.
usually, we have some model classes or dtos that are easier to use in client layers, and we often want client layers to communicate with the service layer — where use cases are implemented. here is an example:
public class productdto
{
public int id { get; set; }
public string name { get; set; }
public string shortdescription { get; set; }
public string description { get; set; }
public int manufacturerid { get; set; }
public string manufacturername { get; set; }
public decimal price { get; set; }
public int productcategoryid { get; set; }
public string productcategoryname { get; set; }
public string imageurl { get; set; }
public int producttypeid { get; set; }
public string producttypename { get; set; }
public bool hasimage { get; set; }
}
but search response contains some general data, not just an array of items found. for example, if we want to implement paging correctly, then we need to also ask for the total number of results. it's a common attribute that is independent from the results returned. for this, we will define productsearchresult class.
[datacontract]
public class productsearchresponse
{
[datamember(name = "@odata.count")]
public int count;
[datamember(name = "value")]
public list<productdto> values;
}
now we have everything we need to make a call to the search service. we add new public method for this to our azure search rest client.
public async task<productsearchresponse> searchproducts(productquery query)
{
var url = string.format("https://{0}.search.windows.net/indexes/products/docs/", _servicename);
url += "?api-version=" + _apiversion + "&search=" + webutility.urlencode(query.term);
var skip = (query.page - 1) * query.pagesize;
var take = query.pagesize;
string filter = buildfilter(query);
if (!string.isnullorempty(filter))
url += "&$filter=" + webutility.urlencode(filter);
if (skip > 0)
url += "&$skip=" + skip;
url += "&$take=" + take;
url += "&$count=true";
var result = await download<productsearchresponse>(url);
return result;
}
private static string buildfilter(productquery query)
{
var filter = "";
if (query.alcvolmax.hasvalue)
filter += "alcvol le " + query.alcvolmax;
if (query.alcvolmin.hasvalue)
{
if (!string.isnullorempty(filter))
filter += " and ";
filter += "alcvol ge " + query.alcvolmin;
}
// apply more filters here
return filter;
}
now our rest client supports also searching and paging.
although azure search service can return many properties for a given entity, it is still possible that you have to query the entity later from the database to get another set of properties that are not available in the search index. this kind of "materialization" happens in domain search service classes that hide all those dirty details from calling code.
wrapping up
using azure search without ready-made client classes is not very complex. we wrote a simple rest client that builds calls to azure search service and returns dtos known to our domain. i admit that perhaps we got too many classes for this simple thing, but we still have a valid object model we can use. of course, all search-related classes can be extended by adding more search properties. i also admit that domain part of this story may be a little too general and it's not very easy to catch on for everybody, but those who know domain model world better should understand how to interface the code with their systems. other guys can just take the search client code and roll with it. as a conclusion, we can say that azure search is easy also without ready-made api packages.
Published at DZone with permission of Gunnar Peipman, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments