What Is Database Contention, and Why Should You Care?
In this article, we’re going to look at both how to avoid contention issues and how to diagnose and resolve them when they do arise.
Join the DZone community and get the full member experience.
Join For FreeDealing with slow database performance? One potential cause of this problem is database contention.
Even if you’re not struggling with a slow database right now, database contention is important to understand. The contention monster often doesn’t rear its ugly head until an application has reached significant scale. It’s best to be prepared, so in this article, we’re going to look at both how to avoid contention issues and how to diagnose and resolve them when they do arise.
But first, we have to understand what they are.
What Is Database Contention?
Lock contention happens when multiple processes are trying to access the same data at the same time. In the context of a SQL database, this might mean that multiple transactions are trying to update the same row at the same time, for example.
To understand why that can cause problems, we need to take a quick detour into a couple of important concepts that relate to how databases handle transactions.
ACID Transactions and Isolation Levels
Processing transactions requires precision. ACID is an acronym that stands for Atomicity, Consistency, Isolation, and Durability — four properties that allow us to guarantee the validity of data in a database even in the event of errors, machine crashes, etc. Specifically, transactions must have:
- Atomicity — Transactions may have multiple steps (for example, check account balance, add $50 to balance, return confirmation of final balance number). Atomicity states that a transaction must be treated as a single unit, such that either all of the steps are completed (the transaction commits) or none of them are (the transaction aborts).
- Consistency — The database must be consistent before and after each transaction. In other words, there must not be any point (even a temporary one) where the data in the database is incorrect.
- Isolation — Transactions are processed independently from each other until they are committed. Different database systems can handle this differently (we’ll get into that in a moment), but this generally requires some form of locking, i.e. a database row is “locked” at the beginning of a transaction processing and will not unlock and allow modification from other transactions until that first transaction either commits or aborts.
- Durability — Changes associated with a transaction that has been committed must persist even in the event of something like a hardware crash.
Digging a bit deeper into isolation, the standards for SQL spell out four isolation levels that govern different approaches to how transactions can interact with data in the database and with each other. In this article, we’ll focus on serializable isolation, which is the strongest isolation level and the only one that completely ensures data integrity. Serializable isolation allows transactions to process concurrently but affect the database as if they had occurred one-by-one.
Why Database Contention Happens
To maintain this isolation, “locks” are required so that multiple transactions aren’t trying to change the same row of data (for example) at the same time. This ensures correctness and consistency, so it’s important for mission-critical transactional workloads. However, it can also lead to processing delays if multiple transactions are trying to access the same “locked” data at the same time.
To illustrate this, let’s imagine a simplified example: two transactions, all acting on the same bank account, and thus both trying to update the same row in our database:
- Query balance, deposit $50, and update balance
- Query balance, withdraw $40, and update balance
If both of these transactions come in at almost the same time (but in the order they’re listed), they would be processed by the database in the manner illustrated in the table below. (Remember: because of isolation, each transaction processes independently and can’t see what’s happening with the other transactions until the results are committed.)
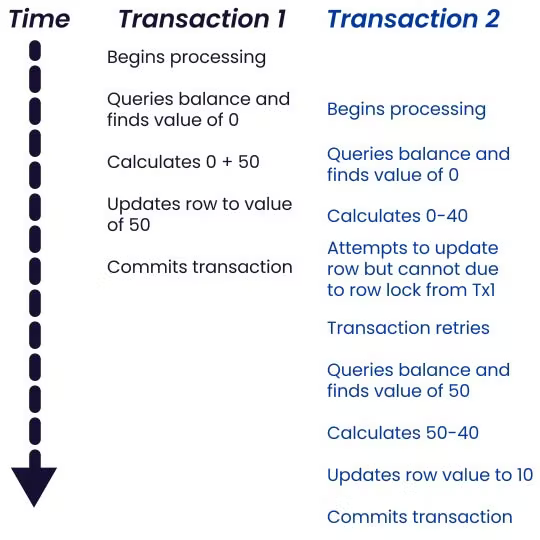
While this is a simplified example, it illustrates how delays can emerge when lots of transactions are trying to act on the same data at the same time.
Examples of Database Contention
Let’s look at a more realistic scenario to further illustrate how contention happens:
Example: Imagine we’ve built a video streaming site. In our database, we have a table called videos with a column called views, and each time a video is viewed, a transaction is sent to the database to add 1 to the value for that video in videos.views.
When traffic is low, this system would work fine. But what happens if a video goes viral or hosts some kind of “premiere” event that generates many new views at the same time? Contention issues are likely to emerge, as each video view is generating a new transaction that’s trying to access the same row of videos.views, but only one transaction can act on that data at a time.
Diagnosing Database Contention
Now that we understand what contention is, how can we tell when it’s happening? Unfortunately, it’s difficult to give a general answer to this question, as it varies significantly based on the database system you’re using. Here, we’ll take a look at several ways to diagnose contention when using CockroachDB specifically — you may find that similar approaches apply to other databases, as well.
Checking performance and error messages. If you’re noticing a decrease in your application’s performance and frequent errors such as SQLSTATE: 40001, RETRY_WRITE_TOO_OLD, and RETRY_SERIALIZABLE, these are signs that you likely have a contention issue.
Querying internal tables to find contention. CockroachDB itself tracks contention problems, and you can access this information by querying the relevant tables in crdb_internal(there are tables for contended indexes and contended tables.
To find contended indexes and tables, use the relevant query from the code snippet below (remembering to replace yourdb with the name of the database you’re using):
SELECT * FROM yourdb.crdb_internal.cluster_contended_indexes;
SELECT * FROM yourdb.crdb_internal.cluster_contended_tables;Consult the SQL Statement Contention graph. The SQL Dashboard of CockroachDB’s DB Console contains a statement contention graph that illustrates the number of queries causing contention issues over time:
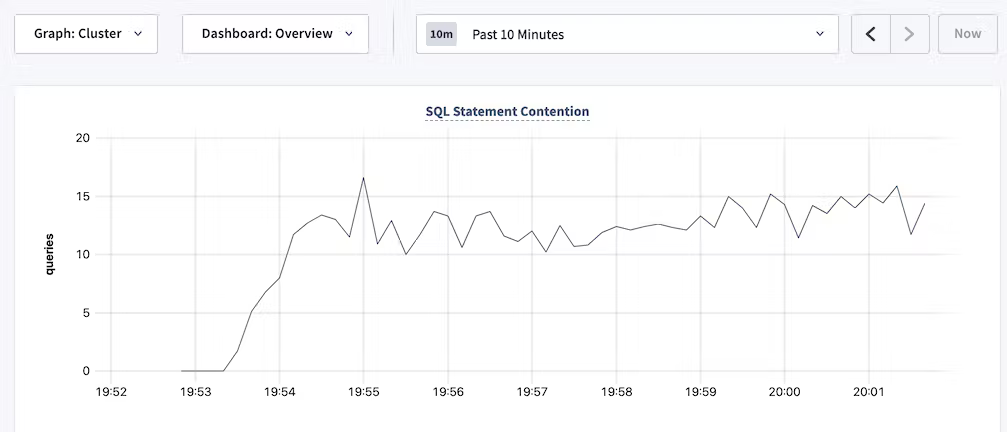
Consult the Transaction Restarts graph. Similarly, the Transactions page in DB Console includes a Restarts graph that can also be helpful — a spike in restarts indicates that there could be a contention issue.
Best Practices for Avoiding Contention in CockroachDB
So now that you’ve identified a contention problem, how can you resolve it? And more importantly, how can you avoid contention problems in the future?
Again, the answer to these questions will vary somewhat depending on your database technology of choice. Here, we’ll present some of the recommended solutions for CockroachDB users:
- Use random index key values (such as UUIDs). Because rows in CockroachDB are distributed across ranges, using randomized values means that transactions operating on different rows in the same table are more likely to be operating on different ranges, reducing the chances of contention.
- Break up large transactions into smaller ones.
- Use
SELECT FOR UPDATEin transactions that will be reading a row and then subsequently updating that same row. - When replacing values in a row, use
UPSERT(rather thanSELECT,INSERT, orUPDATE) and specify values for all columns in the row being updated. - Increase normalization of the data (although this has trade-offs, and won’t always be the best option).
Published at DZone with permission of Charlie Custer. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments