What Database We Use To Support Our AI Chatbots
In this post, I am going to take you through what data tools and techniques we use at AISPEECH to power our AI services.
Join the DZone community and get the full member experience.
Join For FreeReal-Time vs. Offline: From Separation to Unity
Before 2019, we used Apache Hive + Apache Kylin to build our offline data warehouse, and ApacheSpark + MySQL as a real-time analytic data warehouse:
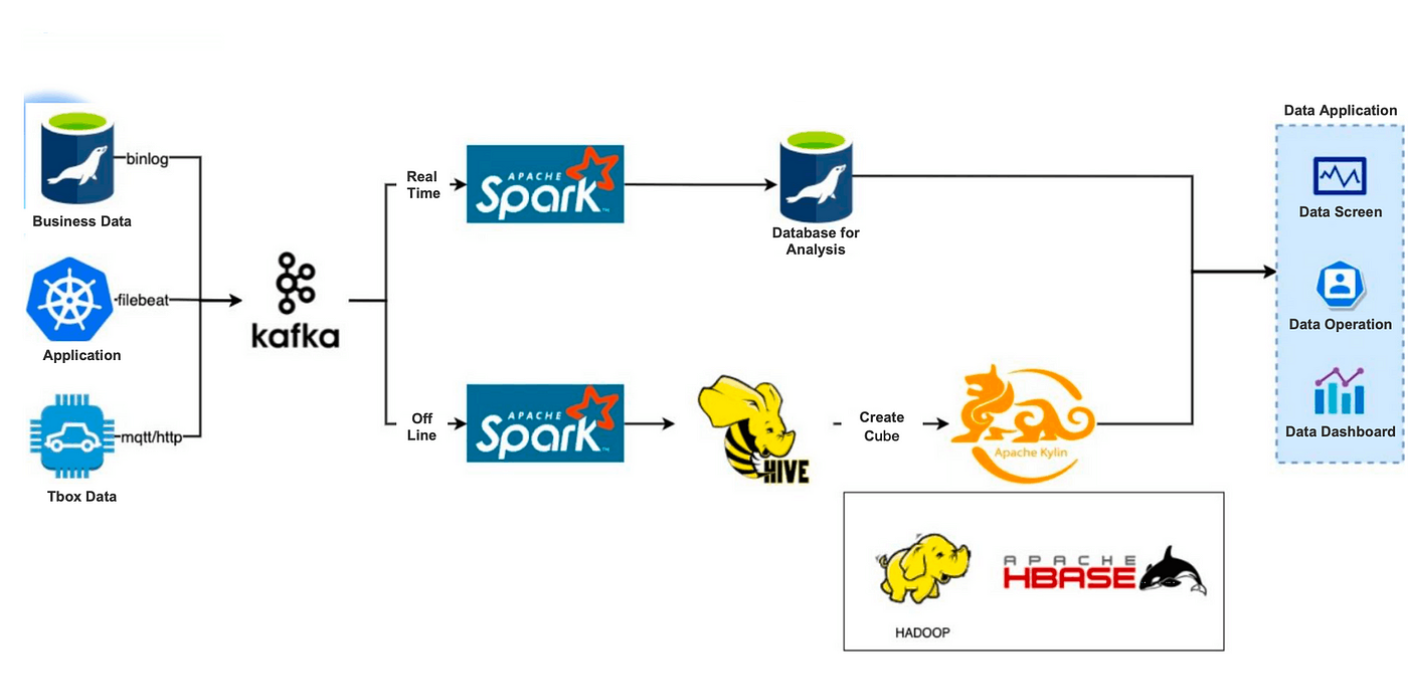
Roughly, we have three data sources:
- Business databases such as MySQL
- Application systems such as K8s container logs
- Automotive T-Box logs
We write such data into Kafka via MQTT/HTTP protocol, business database Binlog, and Filebeat log collection. Then, the data will be diverted to two links: real-time and offline.
Real-time data link: Data cached by Kafka will be computed by Spark and put into MySQL for further analysis.
Offline data link: Data cleaned by Kafka will be put into Hive. Then, we used Apache Kylin to create Cubes, but before that we needed to pre-construct a data model, which contains association tables, dimension tables, index fields, and relevant aggregation functions. Cube creation is triggered by a scheduling system on a regular basis. The created Cubes will be stored in HBase.
This architecture is a seamless integration with Hadoop technologies, and Apache Kylin delivered excellent performance in pre-computing, aggregation, exact deduplication, and high-concurrency scenarios. But as the days go by, some unpleasant issues reveal themselves:
- Too many dependencies: Kylin 2.x and 3.x relies heavily on Hadoop and HBase. Too many components bring longer development links, higher instability, and more maintenance costs.
- Complicated Cube creation in Kylin: This is a tedious process with all the flat table creation, column deduplication, and Cube creation. Every day, we ran 1000~2000 tasks, but at least 10 of them failed so we had to spend a big chunk of time writing auto O&M scripts.
- Dimension/dictionary expansion: Dimension expansion means the prolonged creation time of Cubes when a data analysis model involves too many fields without data pruning; dictionary expansion happens when global exact deduplication takes too long and results in larger dictionaries and longer creation time. Both can drag down the overall data analytic performance.
- Low flexibility of data analysis model: Any changes in the computation fields or business scenarios could entail backtracking of data.
- No support for breakdown queries: We were unable to query data breakdown with this architecture. A possible solution was to push these queries down to Presto, but the introduction of Presto would mean more O&M troubles.
So, we started to find a new OLAP engine that could best serve our needs. Later, we narrowed down our choices to ClickHouse and Apache Doris. Due to the high O&M complexity, numerous table types, and lack of support for associated queries of ClickHouse, we opted for Apache Doris in the end.
In 2019, we built an Apache Doris-based data processing architecture, where both real-time and offline data will be poured into Apache Doris for analysis:
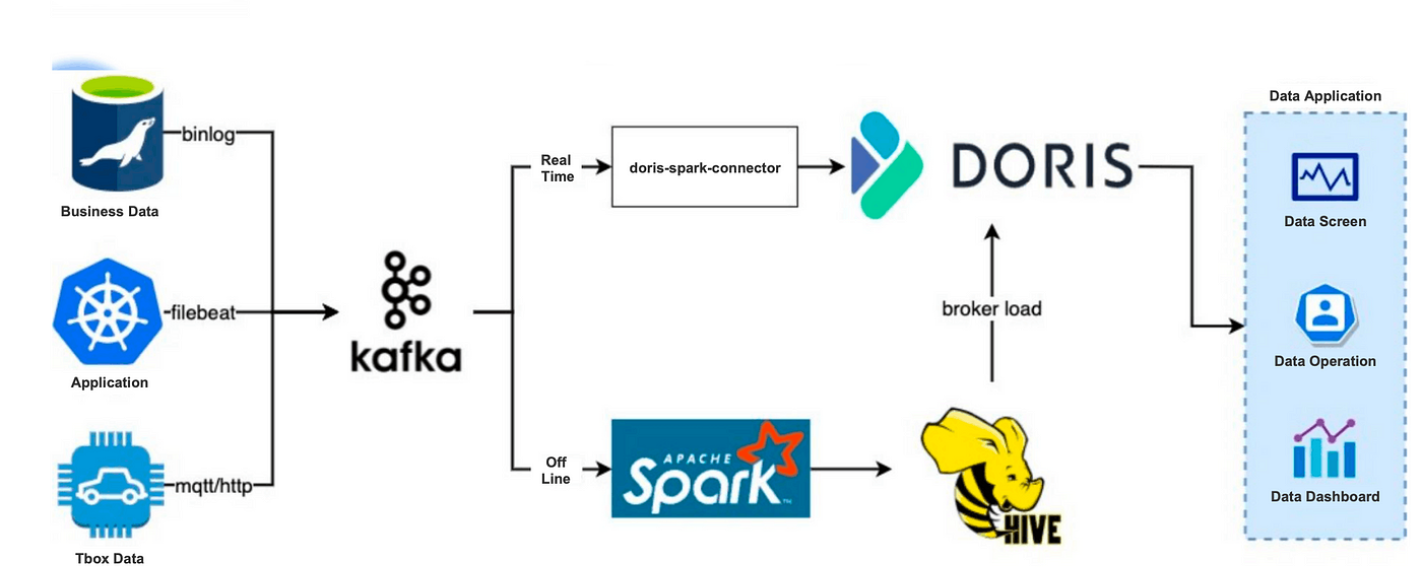
We could have created an offline data warehouse in Apache Doris directly, but due to legacy reasons, it would be difficult to migrate all our data there, so we decided to preserve the upper half of our previous offline data link.
What's different was that the offline data in Hive would then be written to Apache Doris instead of Apache Kylin. The Broker Load method of Doris was fast. Every day, it took 10~20 minutes to ingest 100~200G data into Doris.
As for the real-time data link, we used Doris-Spark-Connector to ingest data from Kafka to Doris.
What's Good About the New Architecture?
- Simple O&M with no dependencies on Hadoop components. Deploying Apache Doris is easy since it only has Frontend and Backend processes. Both types of processes can be scaled out, so we can create only one cluster to handle hundreds of machines and dozens of PBs of data. We have been using Apache Doris for three years but only spent very little time on maintenance.
- Easy troubleshooting. Having a one-stop data warehouse that is capable of real-time data services, interactive data analysis, and offline data processing makes the development link short and simple. If anything goes wrong, we only need to check a few spots to find the root cause.
- Support for JOIN queries in Runtime format. This is similar to table association in MySQL. It is helpful in scenarios that require frequent changes in data analysis models.
- Support for JOIN, aggregate, and breakdown queries.
- Support for multiple query acceleration methods. These include rollup index and materialized view. The Rollup index allows us to implement a secondary index to speed up queries.
- Support for federated queries across data lakes such as Hive, Iceberg, Hudi and databases like MySQL and Elasticsearch.
How Apache Doris Empowers AI
In AISPEECH, we use Apache Doris in real-time data queries and user-defined conversational data analytics.
Real-Time Data Query
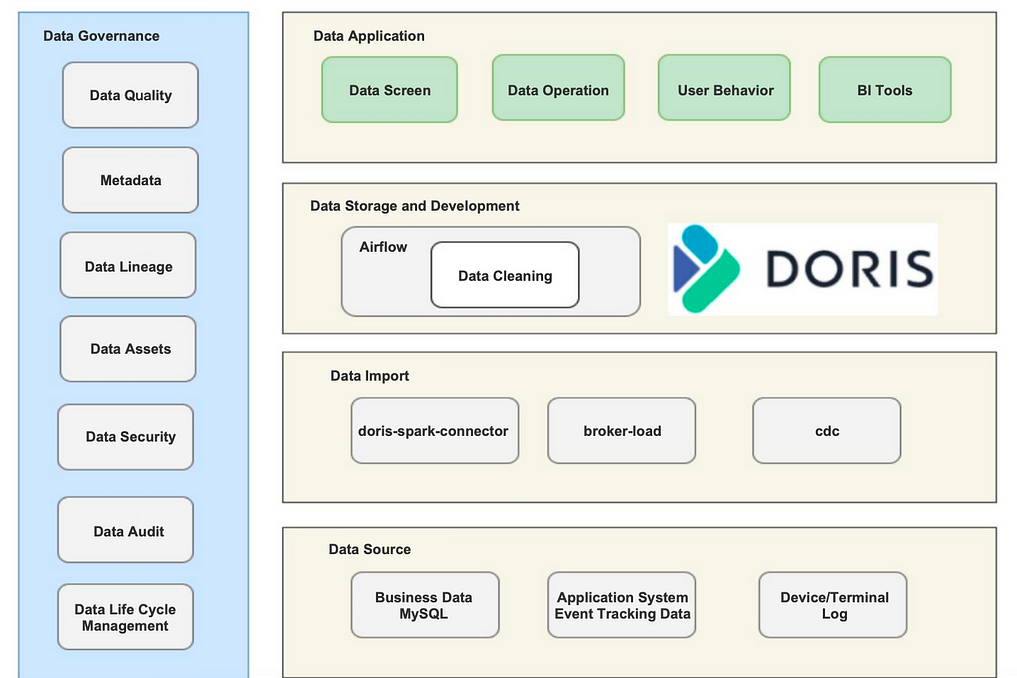
The real-time data processing pipeline works as above. We ingest offline data via Broker Load and real-time data via Doris-Spark-Connector. We put almost all our real-time data in Apache Doris and part of our offline data in Airflow for DAG batch tasks.
Our real-time data is in huge volume, so we really need a solution that ensures high query efficiency. Meanwhile, we have a 20-member team for data operation, and we need to provide data dashboarding services for all of them. That can be challenging for real-time data writing and demanding query concurrency. Luckily, Apache Doris makes all this happen.
User-Defined Conversational Data Analysis
This is my favorite part because we have proudly leveraged our natural language processing (NLP) capability in data queries.
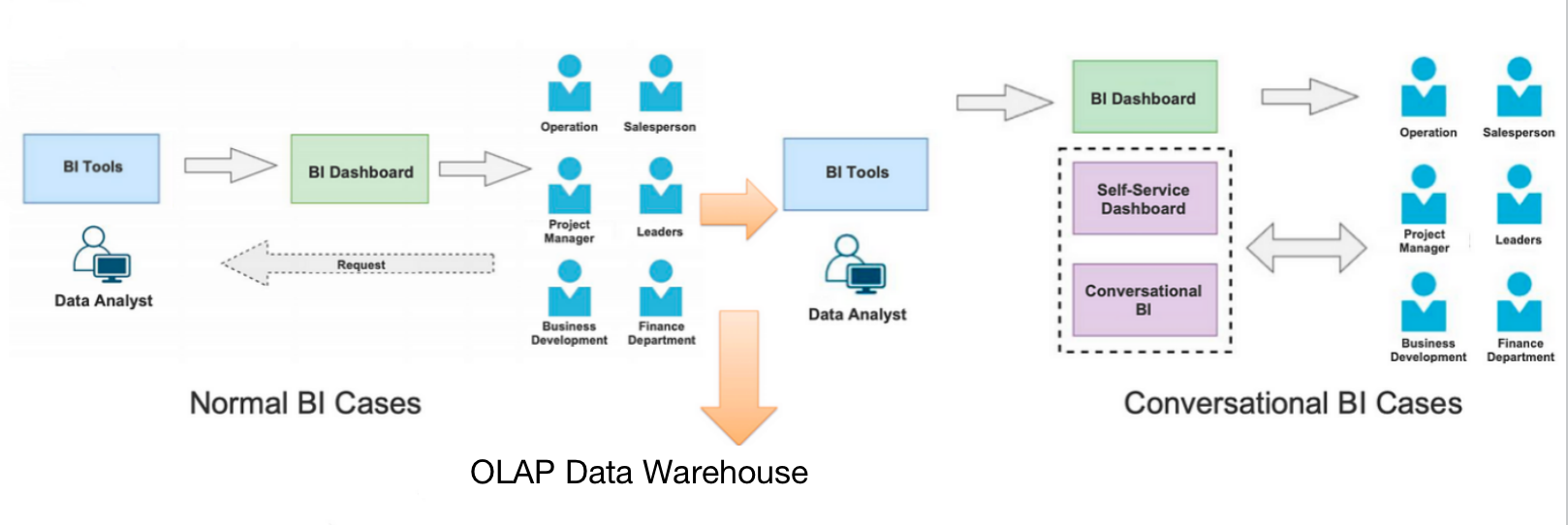
A normal BI scenario works this way: Data analysts customize the dashboards on a BI platform based on the needs of data users (e.g., financial department and product managers). But we wanted more. We wanted to serve more unique needs of data users, such as roll-up and drill-down at any designated dimension. That's why we enable user-defined conversational data analysis.
Unlike normal BI cases, it is the data users but not the data analysts, who are talking to BI tools. They only need to describe their requirements in natural language, and we, utilizing our NLP capabilities, will turn them into SQL. Sounds familiar? Yep, this is like a domain-specific GPT-4. Except that, we've been optimizing it for a long time and fine-tuned it for better integration with Apache Doris so our data users can expect higher hit rates and more accurate parsing results. Then, the generated SQL will be sent to Apache Doris for execution. In this way, data users can view any breakdown details and roll up or drill down any fields.
How Apache Doris makes this work well?
Apache Doris has the following strengths compared to pre-computed OLAP engines such as Apache Kylin and Apache Druid:
- Flexible query models that support user-defined scenarios
- Support for table association, aggregate computing, and breakdown queries
- Quick response time
Our internal users have been giving positive feedback regarding this conversational data analysis.
Suggestions
We accumulate some practical experience regarding the usage of Apache Doris that we believe can save you some detours.
Table Design
- Use a Duplicate table for small data volumes (e.g., less than 10 million rows). Duplicate tables support both aggregate queries and breakdown queries, so you don't need to produce an extra table with all the detailed data.
- Use the Aggregate table for large data volumes. Then you can do roll-up indexing, speed up queries via materialized view, and optimize aggregation fields on top of the Aggregate tables. A downside is that since Aggregate tables are pre-computed tables, you will need an extra breakdown table for detail queries.
- When handling huge amounts of data with many associated tables, generate a flat table via ETL and then ingest it to Apache Doris, where you can do further optimizations based on the Aggregate table type. Or you can follow the Join optimizations recommended by the Doris community.
Storage
We isolate hot and warm data in storage. Data of the past year is stored in SSD, and data older than that is stored in HDD. Apache Doris allows us to set a cool-off period for partitions, but the relevant configuration can only be made upon partition creation. Our current solution is automatic synchronization, in which we migrate a certain portion of the historical data from SSD to HDD to make sure that the data of the past year is all placed on SSD.
Upgrade
Make sure to back up the metadata before upgrading. An alternative method is to start a new cluster, back up the data files to a remote storage system such as S3 or HDFS via Broker, and then import data from the old cluster data into the new cluster by way of backup recovery.
Performance After Version Upgrade
Starting with Apache Doris 0.12, we've been catching up with the releases of Apache Doris. In our usage scenarios, the latest version can deliver several times higher performance than the early ones, especially in queries with complex functions and statements involving multiple fields. We really appreciate the efforts by the Apache Doris community and strongly advise you to upgrade to the latest version.
Summary
To wrap up what we've gained from Apache Doris:
- Apache Doris can be a real-time + offline data warehouse, so we only need one ETL script. It saves us a lot of development work and storage costs and also avoids inconsistency between real-time and offline metrics.
- Apache Doris 1.1.x supports vectorization and thus can deliver 2~3 times higher performance than older versions. Test results show that Apache Doris 1.1.x is on par with ClickHouse in flat table query performance.
- Apache Doris is powerful itself with no dependency on other components. Unlike Apache Kylin, Apache Druid, and ClickHouse, Apache Doris requires no other component to fill any technical gap. It supports aggregation, breakdown queries, and associated queries. We have migrated over 90% of our analysis to Apache Doris, and that has made our O&M much lighter and easier.
- Apache Doris is easy to use as it supports MySQL protocol and standard SQL.
Published at DZone with permission of Wei Zhao. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments