Using SingleStore DB for Full-Text Index and Search
This post continues our exploration of the multi-model capabilities of SingleStore DB. Here, discuss SingleStore DB's support for Full-Text Index and Search.
Join the DZone community and get the full member experience.
Join For FreeAbstract
Continuing our exploration of the multi-model capabilities of SingleStore DB, we'll discuss SingleStore DB's support for Full-Text Index and Search in this article.
Using the example of medical journal articles from the SingleStore self-paced training course on Full-Text Index and Search, we'll store the text from journal articles and then perform a variety of queries using the full-text capabilities of SingleStore DB.
The SQL scripts used in this article are available on GitHub.
Introduction
There is a wide range of use cases where we may want to perform keyword searches on text. Examples include newspaper articles, journal articles, restaurant reviews, lodging reviews, etc. The requirements for these use cases would consist of the ability to:
- Store and search a large body of text
- Return query results based upon relevancy. Relevancy could be determined by frequency, for example
SingleStore DB can support these requirements by:
- CHAR, VARCHAR, TEXT, or LONGTEXT data types.
- Matched documents return a relevancy score between 0 and 1. Results can be ordered by relevancy.
To begin with, we need to create a free Cloud account on the SingleStore website. At the time of writing, the Cloud account from SingleStore comes with $500 of Credits. This is more than adequate for the case study described in this article.
Create Database Table
In our SingleStore Cloud account, let's use the SQL Editor to create a new database. Call this fulltext_db, as follows:
CREATE DATABASE IF NOT EXISTS fulltext_db;We'll also create the journals table, as follows:
USE fulltext_db;
CREATE TABLE journals (
volume VARCHAR(1000),
name VARCHAR(1000),
journal VARCHAR(1000),
body LONGTEXT,
KEY(volume),
FULLTEXT(body)
);Each row consists of 4 columns. The journal article contents are stored in the body column using LONGTEXT. We also create an inverted index on the body column using FULLTEXT. Stopwords are ignored as they occur very frequently. SingleStore DB's default list of stopwords is as follows:
a, an, and, are, as, at, be, but, by, for, if, in, into, is, it, no, not, of, on, or, such, that, the, their, then, there, these, they, this, to, was, will, withPopulate Database Table
We'll create a Pipeline to load journal data into our SingleStore DB table. In a previous article, we've used a Pipeline with Kafka to load data into SingleStore DB, and now we'll use this same technique with Amazon S3.
CREATE PIPELINE IF NOT EXISTS journal_pipeline AS
LOAD DATA S3 'zhou-fts/*json'
CONFIG '{
"region" : "us-west-1"}'
INTO TABLE journals
FORMAT JSON
( volume <- volume,
name <- name,
journal <- journal,
body <- body
);We'll now start the pipeline, as follows:
START PIPELINE journal_pipeline;After a few minutes, we can check the table using the following query:
SELECT COUNT(*) FROM journals;There should be 31000 rows, as shown in Figure 1.

Example Queries
Now that we have built our system, we can run some queries. SingleStore DB supports two main functions for use with full-text:
- MATCH: The result of using this function is a relevancy score between 0 and 1. A score closer to 0 indicates a lower-quality match, and a score closer to 1 indicates a higher-quality match. The documentation contains additional details and examples.
- HIGHLIGHT: This is similar to
MATCHbut returns a JSON document. The JSON document contains an offset, a unique term count, and a small quantity of text. The documentation contains additional details and examples.
Let's see some examples of these functions.
First, let's find all journal articles that contain the word optometry.
SELECT *
FROM journals
WHERE MATCH(body) AGAINST ('optometry');This query should return 40 rows. The partial results are shown in Figure 2.
Next, let's find articles that contain the words dentistry and cavities anywhere in the text, as follows:
SELECT *
FROM journals
WHERE MATCH(body) AGAINST ('dentistry AND cavities');Instead of using AND, we can also use &&. An alternative way to express this query is as follows:
-- Alternative query
SELECT *
FROM journals
WHERE MATCH(body) AGAINST ('+dentistry +cavities');By using the + operator, we specify that both words must be present anywhere in the text.
This query should return three rows, as shown in Figure 3.

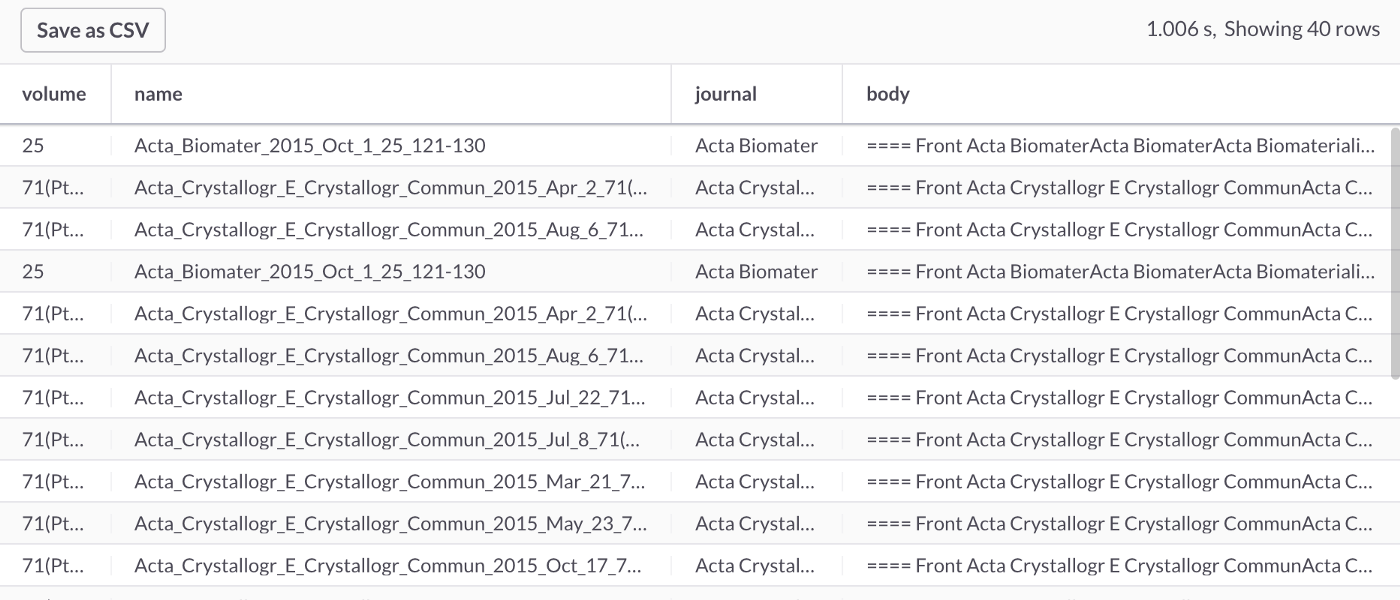
In the following query, we'll look for any articles that have the word optometry but not the word contacts, as follows:
SELECT *
FROM journals
WHERE MATCH(body) AGAINST ('optometry -contacts');This query should return 28 rows, partially shown in Figure 4.
The ~ character can also be used for fuzzy searches. The documentation contains a complete list of operators.
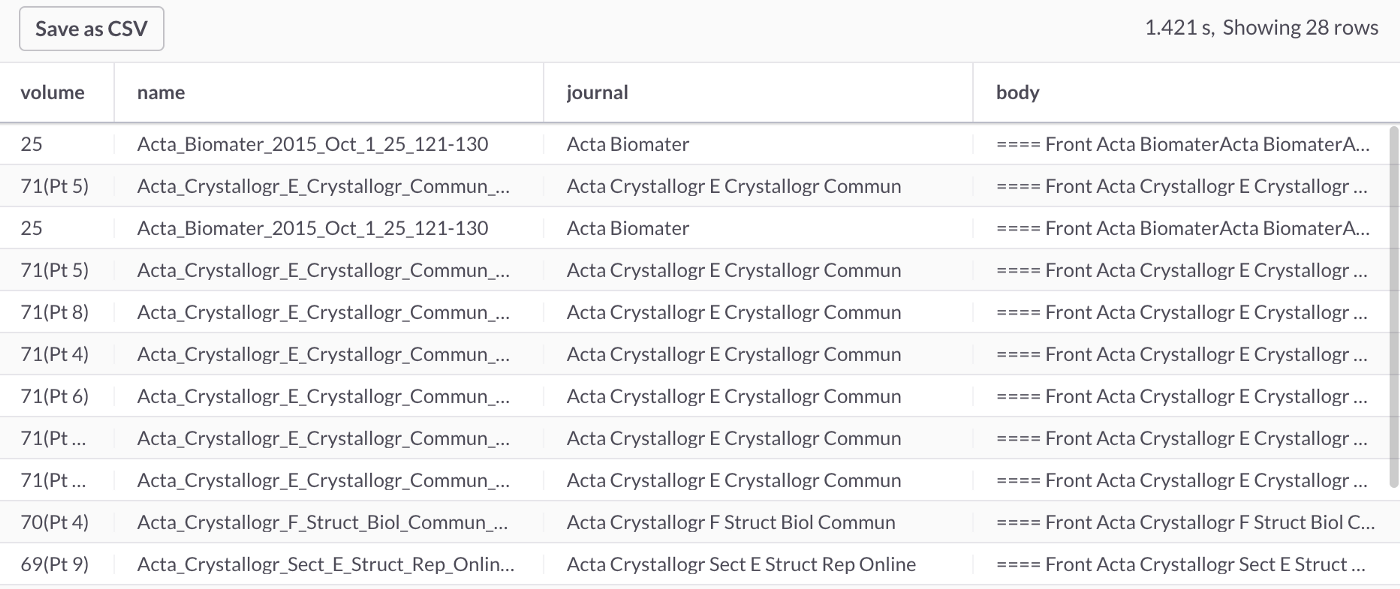
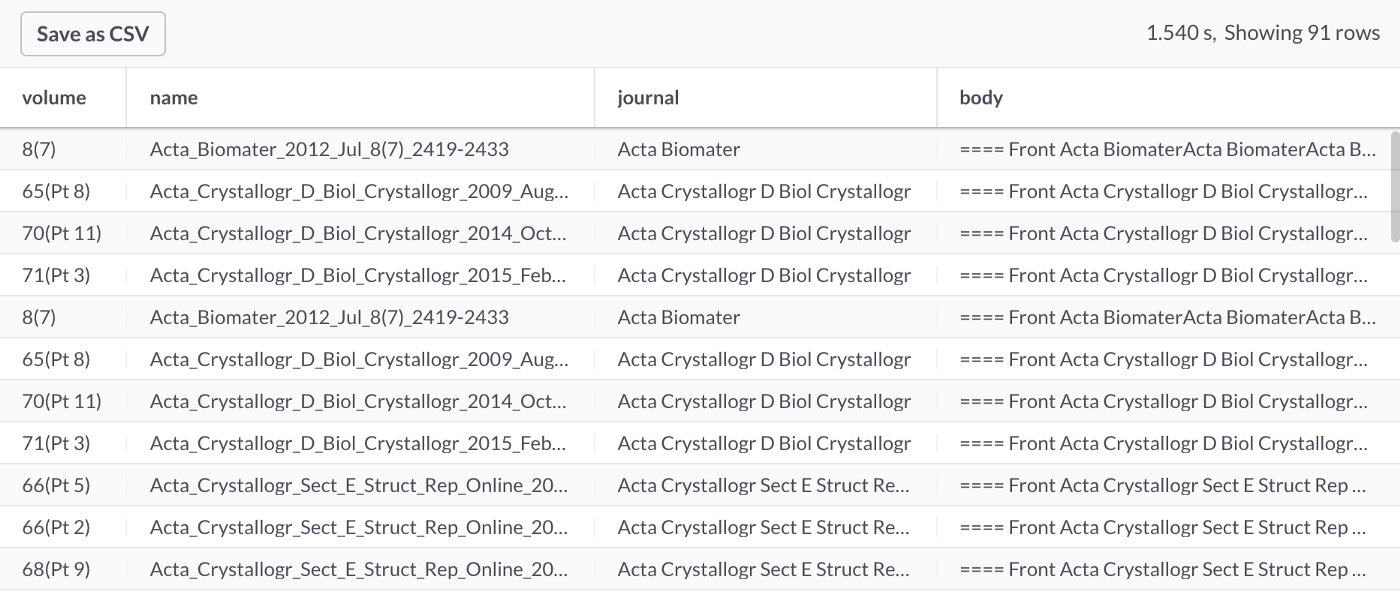
Wildcard support is also available for single and multiple characters using ? and *, respectively. In the following example, we'll use the * character to match dentists, dentistry, etc.
SELECT *
FROM journals
WHERE MATCH(body) AGAINST ('dentist*');This query should return 91 rows, partially shown in Figure 5.
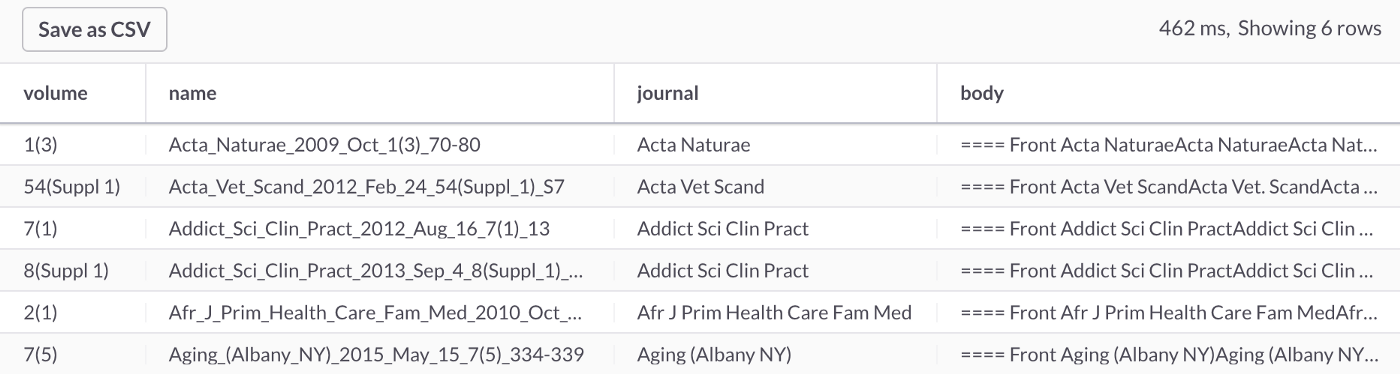
Let's write a slight variation of an earlier query. Let's search for the word pediatrician, as shown below:
SELECT *
FROM journals
WHERE MATCH(body) AGAINST ('pediatrician');This query should return six rows, as shown in Figure 6.
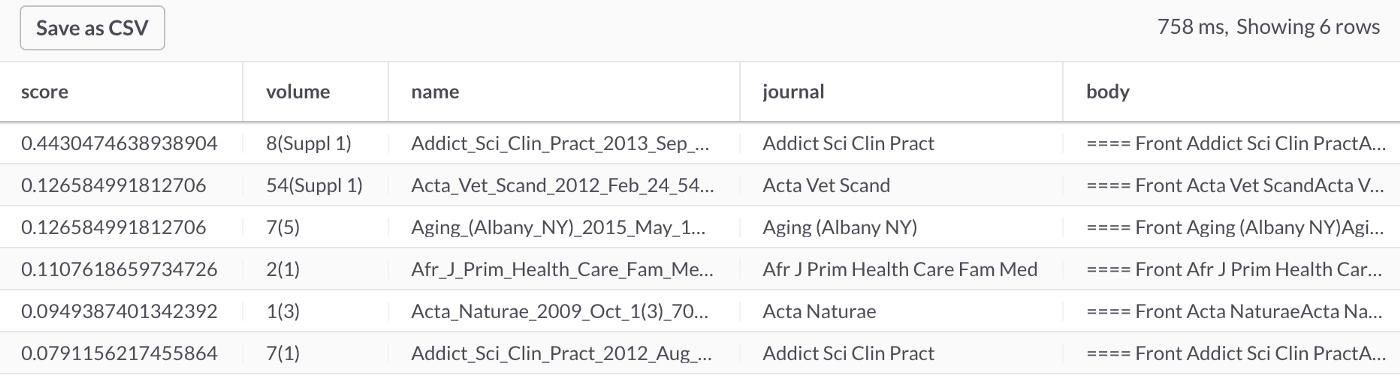
If we use the main query as part of the SELECT, as follows:
SELECT MATCH(body) AGAINST ('pediatrician') AS score, *
FROM journals
WHERE MATCH(body) AGAINST ('pediatrician')
ORDER BY score DESC;We can see the relevancy score, as shown in Figure 7.
Finally, we can also use HIGHLIGHT to return the offset, a unique term count, and a small quantity of text, as follows:
SELECT HIGHLIGHT(body) AGAINST ('pediatrician')
FROM journals
WHERE MATCH(body) AGAINST ('pediatrician');We can see the output in Figure 8 and, if we examine the result closely, we can see the <B>pediatrician</B> pattern in the fragments of text.

Summary
In this article, we have seen how we can use the built-in full-text index and search capabilities of SingleStore DB. SingleStore DB supports two main functions, MATCH and HIGHLIGHT, a series of operators, and both single and multiple character wildcard searches.
Published at DZone with permission of Akmal Chaudhri. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments