Using Databases With High-Performance Event Streaming: Critical Considerations
Event streaming is major ongoing data architectural shift. What criteria should you use to consider databases for use with event streaming?
Join the DZone community and get the full member experience.
Join For FreeIn an earlier article I talked about comparing distributed databases in general. All of those considerations remain salient for choosing a database right for your use case. Yet for today, let’s focus in on a particular aspect of capability: whether a database is a strong fit for an event streaming architecture.
The transition from batch-oriented processing to event streaming architectures is at the heart of what’s fundamentally shifting in this next tech cycle. Kafka was initially released in 2011, around the same era as the early NoSQL databases. Pulsar was slightly later, being invented at Yahoo in 2013. Many database architectures long predate the event streaming revolution, and their fundamental design decisions may be an anti-pattern for use with event streaming. 
Databases are [or should be] designed for specific kinds of data, specific kinds of workloads, and specific kinds of queries. How aligned or far away from your specific use case a database may be in its design and implementation from your desired utility of it determines the resistance of the system. So, sure you can use various databases for tasks they were never designed for — but should you?

For a database to be appropriate for event streaming, it needs to support managing changes to data over time in “real time” — measured in single-digit milliseconds or less.

And where changes to data can be produced at a rate of hundreds of thousands or millions of events per second. (And even greater rates in future.)
There are four major axes that organizations consider when looking at whether a database is suitable for their event streaming use cases:
- Cloud native
- Intrinsic qualities
- Event-driven design
- Best fit
Let’s go through each of these in more detail.
Cloud Native
Earlier this year, a study by Foundry (formerly IDG Communications) found that half of organizations still have the bulk of their workloads mostly on-premises. Another third are “mostly cloud” but still with some on-premises services. Only 7% of organizations are “all cloud.”
This shift to cloud is rapidly underway. “the all-cloud number is expected to increase by some 250% over the next 18 months, to 17% who plan to shift everything they have to the cloud.”
Even if users are not planning to go “all-cloud,” they know their systems need to at least integrate with their cloud services. They need to future proof their technology choices. Thus, “seventy-two percent of IT leaders say that their organization is defaulting to cloud-based services when upgrading or purchasing new technical capabilities.”
Critical to this integration of on-premises services and cloud services is the ability to integrate with event streaming. Indeed, event streaming services are seen as the key component to hold multi-cloud and hybrid cloud deployments together between disparate systems.
What does this mean for a distributed database choice?
For many, this means asking the vendor if they have a Database-as-a-Service (DBaaS) offering. If they do, an organization can run lean. They can focus on developing their applications, and not have to staff specialists in database administration. If they don’t, there’s organizational friction to adoption.
Organizations also want to know if a solution is locked in to a single cloud vendor, or if it is cloud neutral — deployable anywhere. Because while a few organizations are still willing to commit themselves exclusively to a single cloud vendor strategy, about 90% of respondents to a 2022 Flexera survey said their team already has a multicloud strategy. Thus a single cloud vendor database presents another barrier to adoption — it becomes a lock-in that directly contradicts their goal of strategic flexibility.
The next question is whether or how a distributed database can be deployed — only in a single region cluster, or across multiple datacenters and regions.
There’s a huge difference between having a true multi-datacenter architecture versus keeping systems in sync across regions through some sort of cobbled-together cross-datacenter update mechanism. The former is designed to be reliable, secure, and bidirectional (multi-directional); the latter may only be unidirectional, with one primary datacenter flowing updates to other replicas. And, of course, there’s some assembly required which can add to operational complexity and security concerns.

“Some assembly required.”
Being cloud-native means a great many things to different people. It may also infer capabilities like elasticity (dynamic provisioning and the ability to scale up or down throughput and/or storage capacity as needed), to run serverless (without having to worry about specific underlying hardware), or cloud orchestration (Kubernetes). There’s tons more considerations based on various roles and perspectives, ranging from DevSecOps and SREs, to performance and platform engineering.
While many vendors will claim to be “cloud-native,” what they may mean is that they have lifted and shifted their open source or enterprise databases to run in the cloud with a thin veneer of “cloud” painted on top. This is not the same thing as a from-the-ground-up implementation, or putting in all the hard elbow grease to make sure that everything from API and microservices integrations, ecosystem connections, SRE and DevOps tools, to account management, billing and governance was designed to make the system easy to implement and consume.
Intrinsic Qualities
The next considerations are intrinsic qualities of the database in question. These are all the critical “-ilities” that used to be summed up as RAS or RASP — Reliability, Availability, Serviceability, and Performance. While this acronym harkens back to the era of pre-cloud hardware, it, and many other qualities, can be redefined for this cloud-native tech cycle.
Reliability is the critical quality that appeals most to a Site Reliability Engineer. That a database will meet its Service Level Agreements (SLAs) and Service Level Objectives (SLOs). What good is a database you cannot rely upon? You can even drill down upon what “reliability” means, in that it can also stand for “durability” — the resilience of a system to outages. Or the anti-entropy mechanisms that it might include, such as the ability to gracefully handle or recover from outages, repair data, or even catch up a node down for a transient outage using hinted handoffs.
If you are shoving data down a big, fast pipe, and your destination is offline, what do you do? This can be why event sourcing is important — so you can go back step-by-step through all stages of an event stream and find out what your results should be. But it’s vital that your production database doesn’t make you question its viability as a source of truth in the first place.
Availability (high availability) is at the heart of databases like ScyllaDB and all classes of “AP”-mode databases as defined by the CAP theorem. While there is definitely still a place for strongly consistent (“CP”-mode) databases in an event streaming world — SQL RDBMS are not going away any time soon — high availability systems are often a better match for event-driven architectures, being highly asynchronous and optimized for real-time responsiveness.
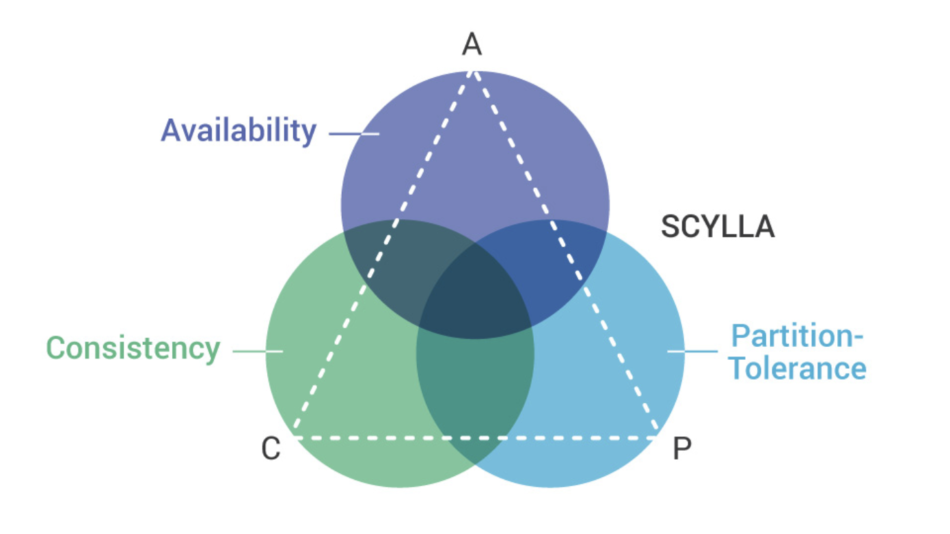
“AP”-mode databases like ScyllaDB are often a better match for event-driven architectures
Serviceability, if adopted to the modern cloud-native milieu, encompasses other elemental qualities such as observability, manageability, usability, facility, and more. Was your database designed so you can tell what it’s doing? Conversely, can you tell it what to do if it’s not behaving properly? Usability is a key factor in adoption. Modern distributed databases are not “easy.” They require expertise in data and query modeling, operations and administration. But is your system needlessly opaque and obtuse? If so, then you might find your team balks at having to learn something utterly orthogonal to current knowledge or behaviors, if not outright actively hostile to adoption.
“Facility,” to me, goes beyond just being “usable.” It asks, “is it easy to use and administer?” Does it feel bulletproof to run? Or is it a cantankerous beast? Does running it feel like a joy, or does it saddle organizations like constantly suffering from the miasma of a low-grade fever?
This can be exemplified by the annual Stack Overflow survey, which asks tens of thousands of developers what their most loved and most dreaded databases are. Developers who feel their current choice is a dreaded chore will be looking for something, anything, to ameliorate their pain over time. Those that enjoy their work are less likely to churn to a new technology, or abandon an organization that they believe is woefully behind the times. Users who love the technology they’ve deployed on don’t have to think too heavily about it. The database becomes “invisible,” allowing them to focus instead on the technical problems they are trying to solve.
Performance is also a key part of this critical factor. Let’s look more at this in specific respect to an impedance match for your event-driven architecture.
Event-Driven
Let’s now focus on whether the database is truly designed for an event-driven architecture. Does its features and capabilities actually help you evolve from a batch-oriented world to a real-time streaming reality?
There are two sides to this: sink (consumer) and source (producer).
Acting as a consumer (sink) seems pretty straightforward — it’s just data ingestion, right? — but there are many subtleties involved. How does the system handle time series data? How does it partition such data and distribute it within the system? Do all of the writes go to a single hot shard that melts with the throughput? Do the other shards hold “stale” data that is essentially “write once, read hardly ever?” (This can be especially problematic on primary-replica systems that only allow one node to be the leader that can be written to; all the others are read-only copies.)
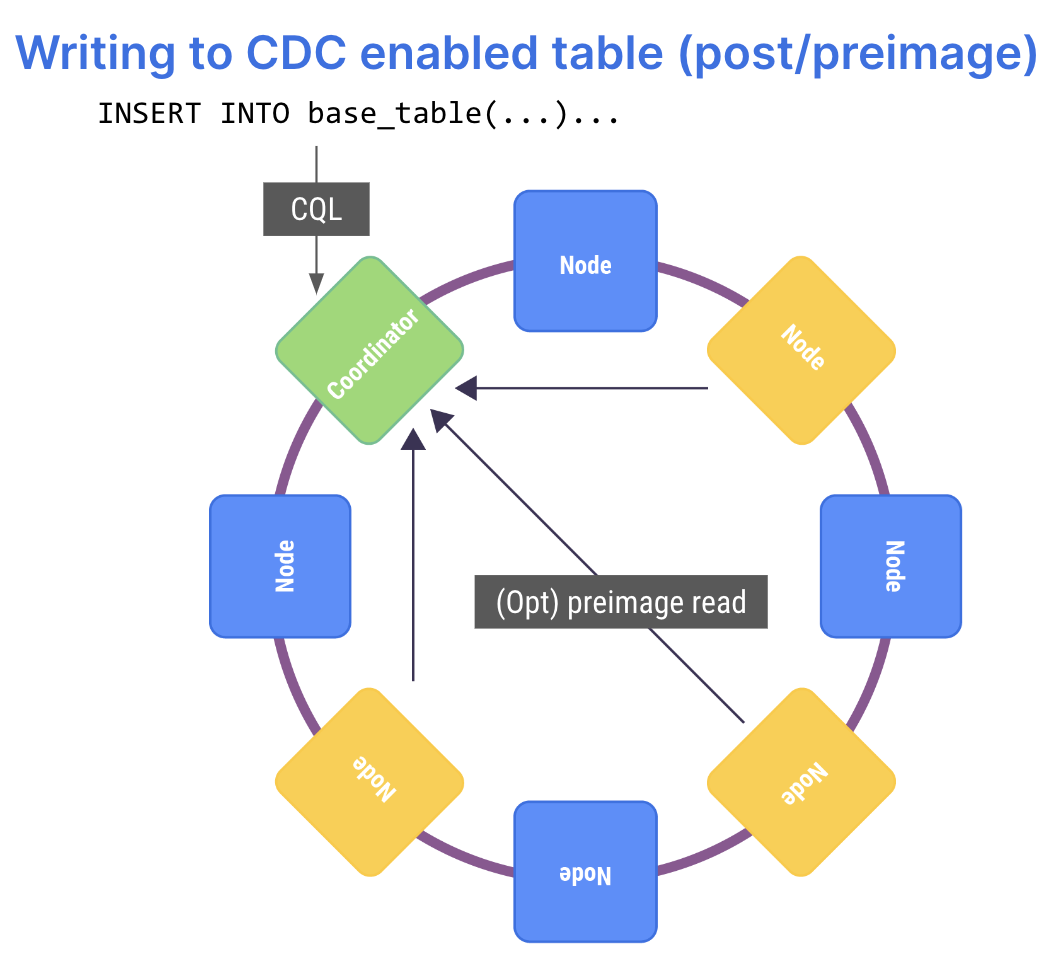
As a producer (source), there’s more requisite infrastructure work, such as support for Change Data Capture (CDC) so that an alteration to the database can be published to a topic. CDC implementations can vary widely, with some being well-designed and engineered; efficient and comprehensive. Yet others can be afterthoughts or bolt-ons, with significant performance impacts and kludge-y in implementation. You really want to double-click on the word “CDC” when you see it in a list of supported features, because no two database vendor implementations will be the same.
Also, while it is subtle, it is important to note that to truly be an “event sourcing” solution, a database needs to keep a record of all data states, event-after-event. So you may need to keep pre-values as well as post-values of data records; not just the diffs. Plus your use case will determine how long those records need to be kept around.
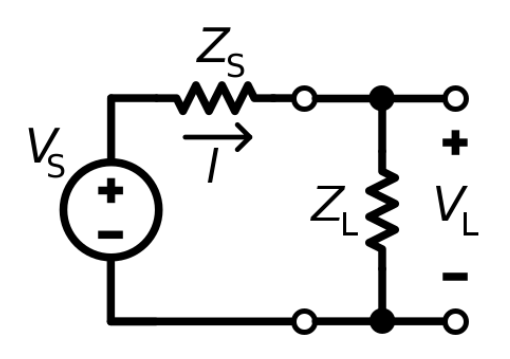
Impedance matching in event streaming is important to keep the “current” of your organization’s data flowing without resistance or signal loss
To truly pair with your event streaming system, both the database you are using and the event streaming architecture you are implementing need to have an “impedance match.” If the database is too lightweight or too sluggish to keep up with the volumes of your event streaming, it will quickly become overwhelmed and unusable. Conversely, if your event streaming cannot keep up with the pace of updates to your operational transactional database, you may find that you can’t keep the rest of your enterprise in sync with the latest changes occurring in your source of truth.
Best Fit for Use Case
Just because you are familiar with a particular database doesn’t mean it’s the best fit for the job. Maybe you are familiar with SQL. But does the data structures and high availability and throughput of this use case require you to consider a NoSQL database instead? Are you familiar with NoSQL, but really, for this highly consistent use case you will need tables and joins and third normalized forms? Then that sounds like a job for SQL.
Here, users should think about what sorts of applications they are designing. What sort of throughput and latency requirements they have. Data set scaling (gigabytes? terabytes? petabytes?), both in total, and growth-over-time.
They should then look at the data model and data query languages required to most efficiently and easily obtain the data results they are looking for. Is this a read- or write-heavy workload, or is it mixed read-write? Is it transactional updates, or is it analytical range or full table scans? How fast does the data processing have to happen? Are results needed in the sub-millisecond, millisecond, second or even minute+ range?
Speed can also be measured in terms of throughput. Do you have hundreds of queries per second, or thousands or a million or more? And throughput itself can either be seen as operations or transactions per second, or it can be looked at based on total volume or payload. Because the result set for a full table scan is going to be vastly different than a single object or row result query.
Finally, and of primary concern to all, what is the price/cost that the organization is willing to bear for this solution? What sort of TCO or ROI goals does it have? Because what may sound lovely for performance purposes might make you blanch at your monthly bill when it comes due.
For example, a DBaaS option may seem more expensive than open source (“it’s free, right?”), but the commercial service might have features that can actually save your organization more in the long run, either in terms of operational or administrative overhead.
With all of these considerations in mind, you now have a general rubric against which you can grade your short list of options for your use case.
Event Streaming Journey of a NoSQL Database: ScyllaDB
So let’s see how this rubric “grades” ScyllaDB, an open-source NoSQL database. If you are using a different database, just consider for yourself how your own technology choice stacks up.
First, let’s look at where ScyllaDB began its journey toward event streaming. Work on ScyllaDB began in earnest in 2015 — well into the event streaming era. Its founders were cognizant of Kafka and Pulsar, and blogs early in the history of ScyllaDB (and Confluent) spoke about the virtues of connecting Kafka and ScyllaDB (see here, here, here, and here).
The reason was straightforward: Kafka was a highly-scalable, performant event streaming architecture, and ScyllaDB was a highly-scalable, performant NoSQL database.
ScyllaDB was designed to get single-digit P99 latencies at millions of operations per second. It could scale out not just across any number of servers, but, given its foundations on the Seastar framework, also scale up to any core count per server.
Its peer-to-peer active-active topology meant there was no single point of failure or throughput bottleneck of a leader-replica design. (You can read more here if you want to be more familiar with ScyllaDB’s architecture.)
Also, it was compatible with Cassandra CQL — and later, Amazon DynamoDB — so it was already comfortable to those who were familiar with its query languages and data models.
Because it was compatible with Apache Cassandra, it immediately inherited the ecosystem connectors that were already available for it.
Users, such as Numberly, developed their own systems to integrate ScyllaDB and Kafka. Fortunately, ScyllaDB and Kafka already played well together.
We Can Do Better
While that was sufficient to get users up and running connecting ScyllaDB with Apache Kafka, we knew there were features that users would truly benefit from unique to our own designs and implementation. For example, building our own custom Sink and Source connectors.
The sink is the easier of the two, and can seem pretty straightforward. But even then, you have subtleties. For example, ScyllaDB’s Kafka Sink Connector is far from “vanilla.” It takes advantage of ScyllaDB’s shard-per-core design by being shard-aware, directing writes not only to the right node, but to the exact right vCPU associated with a data partition in a cluster. This minimizes cross-CPU traffic for fastest write efficiency, lowering latencies and maximizing throughput.
To be an event source, though, required some pretty radical work on ScyllaDB that took quite a bit of time. First was the implementation of Change Data Capture. We spoke repeatedly about the design and implementation in 2020, later again in 2020, then more on CDC best practices in 2021 when it went GA, and later again in 2021 when we had the Kafka Source Connector built on Debezium. All in all, it took more than two full years of engineering to really have the CDC implementation we knew customers would be happy with.
ScyllaDB’s Journey to Event Streaming — Starting with Kafka
- Shard-Aware Kafka Sink Connector[January 2020]
- Change Data Capture[January 2020 – October 2021]
- January 2020: ScyllaDB Open Source 3.2 — Experimental
- Course of 2020 – 3.3, 3.4, 4.0, 4.1, 4.2 — Experimental iterations
- January 2021: 4.3: Production-ready, new API
- March 2021: 4.4: new API
- October 2021: 4.5: performance & stability
- CDC Kafka Source Connector[April 2021]
By late 2021, with both Sink and Source connectors, and with the CDC interface fully stable and performant, the integration was bidirectional between the systems and complete.
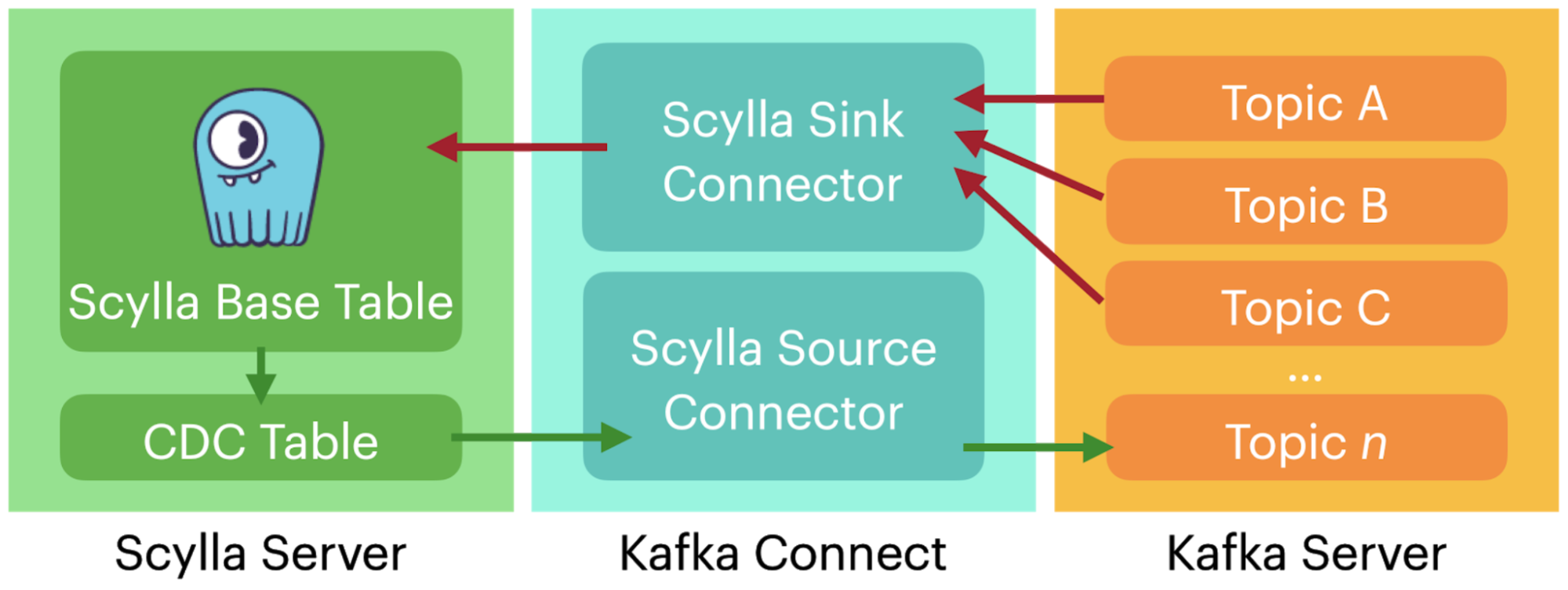
That solved for open source Apache Kafka and enterprise Confluent Kafka, yet those are not the only options in the event streaming world. Fortunately, Redpanda is Kafka-compatible, so it immediately inherits compatibility to our existing connectors.
ScyllaDB’s Journey to Event Streaming — with Pulsar
How about Apache Pulsar? Or a commercialized Pulsar, such as the StreamNative Platform? Fortunately, out of the box Pulsar ships with a Cassandra Sink Connector. Though this isn’t a shard-aware sink connector, like we have for Kafka. Using the Pulsar Producer, you can wrap or adapt it to ingest data from Kafka topics. However, the Pulsar wrapper is admittedly a “some assembly required” solution.
So future potential developments include a native Pulsar shard-aware Consumer, and a native CDC Pulsar Producer.
- Pulsar Consumer: Cassandra Sink Connector
- Comes by default with Pulsar
- ScyllaDB is Cassandra CQL compatible
- Docs: https://pulsar.apache.org/docs/io-cassandra-sink/
- Github: https://github.com/apache/pulsar/blob/master/site2/docs/io-cassandra-sink.md
- Pulsar Producer: Can use ScyllaDB CDC Source Connector using Kafka Compatibility
- Pulsar makes it easy to bring Kafka topics into Pulsar
- Docs: https://pulsar.apache.org/docs/adaptors-kafka/
- Potential Developments
- Native Pulsar Shard-Aware ScyllaDB Consumer Connector — even faster ingestion
- Native CDC Pulsar Producer — unwrap your topics
Summary
Readers can use the ideas presented herein to compare the suitability of existing or proposed databases for their own event streaming architectures.
Event streaming is a trend that is unmistakable and growing, and presently many users deploy event streaming side-by-side with large enterprise-grade databases.
Published at DZone with permission of Peter Corless. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments