Using AWS DMS for Data Migration From On-Premises Oracle 19 to AWS DynamoDB: Insights From Practical Migration
This article provides insights on using AWS DMS for migrating on-premise Oracle tables to AWS DynamoDB, using learnings from real-world migrations.
Join the DZone community and get the full member experience.
Join For FreeThe first article on the insights from Data Migrations using AWS DMS focused on on-prem Oracle source to AWS RDS PostgreSQL target. In this article, we look at the AWS DynamoDB as the target for the on-prem Oracle 19 database. The examples presented in this article are modeled on practical migration challenges for clients where this migration path was followed.
The challenges in the migration to DynamoDB are closely related to the inherent DynamoDB design and how radically it differs from RDBMs like Oracle. The laser-sharp focus that AWS has on scaling DynamoDB at any volume to provide consistent throughput means certain restrictions in how the model works. And so, the schema-less-ness of DynamoDB makes migration from RDBMS a unique challenge.
Why would anyone want to move from RDBMS to DynamoDB, in a brownfield architecture, which then has a data migration to deal with? Having dealt with several such migrations, I can safely say that this migration path is not uncommon. Especially in the monolith to microservices journey, a single microservices that is decomposed from a larger model ends up with a few entities, most of which do not need a full-blown RDS database but a few tables for easier access, cost-saving, and elastic scaling. In other words, it simplifies the database ops. Handling large volumes of data for known (i.e., no ad hoc) access patterns is the forte of DynamoDB.
The challenges in this migration path are:
- Adapting the RDBMS entity-relationship model to DynamoDB via a PK, SK, LSI and GSI.
- Data Type conversions to limited DynamoDB-supported data types.
- Creating Composite keys for multiple entities in the same DynamoDB table.
- Migrating RDBMS native objects such as Sequences and Stored Procedures.
- Lack of DMS data validation post-migration.
The case of using DynamoDB in a microservices journey is a design challenge that does not lay only in DynamoDB itself but also in service design, user experience, and dealing with transactions. So, it is extremely rare that an Oracle Schema is simply migrated to a set of corresponding DynamoDB tables (for example, to “minimize the impact” on the DAO layer in the application), like how you would expect in an RDBMS-to-RDBMS migration. DynamoDB adoption is a fresh and unique data modeling based on the constrained environment of DynamoDB. Data Migration is a question that follows a stable DynamoDB data model. And the quirks adopted in this data model are the core challenges to data migration.
High-Level Design
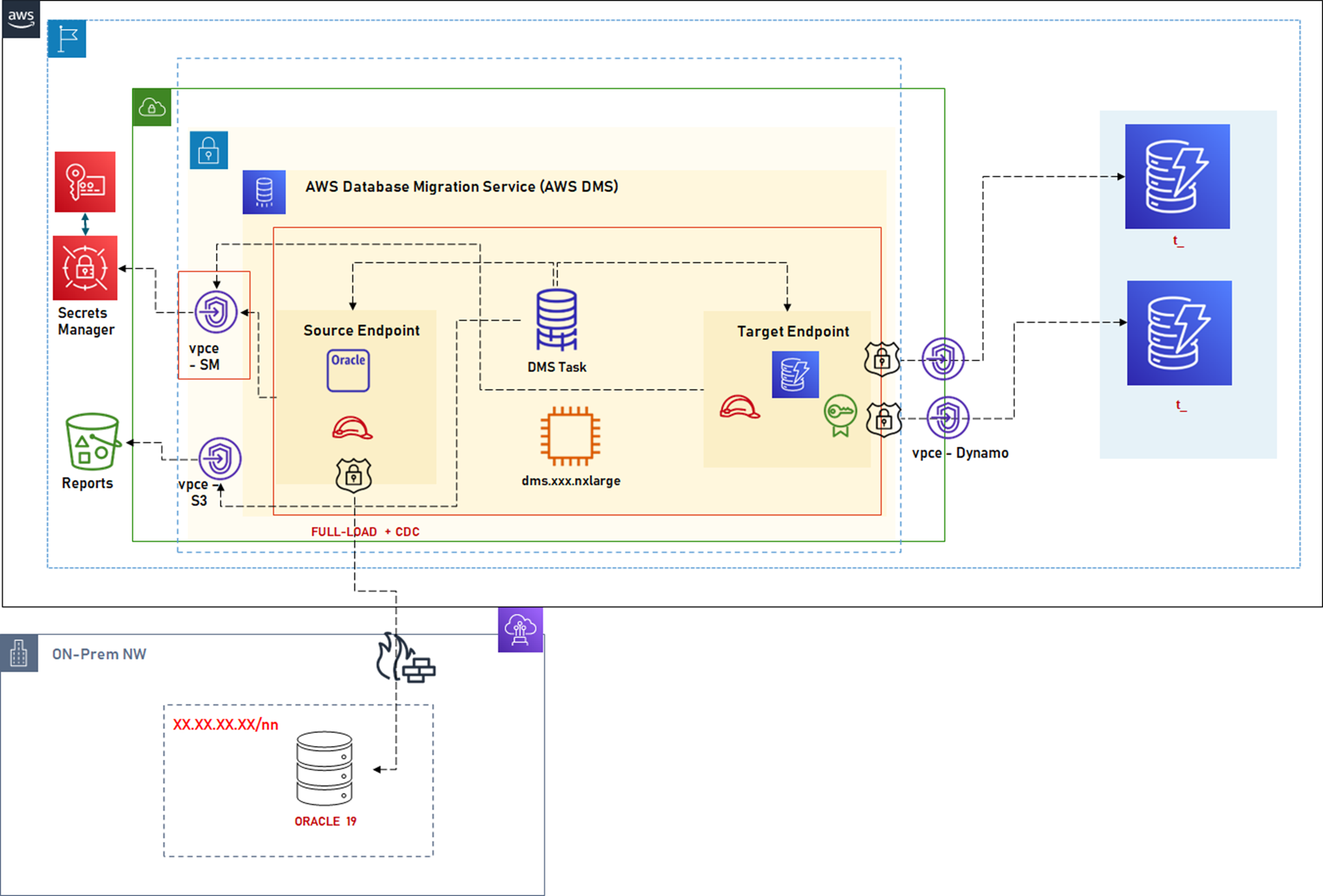
DMS Design
The design is simplified to represent a few essential components and concepts:
AWS Direct Connect: Explained in the first article.
Network Access: DynamoDB is not VPC-bound and is a regional resource. So, a DMS set up in a VPC can be accessed via a Gateway (or Interface) endpoint. This endpoint is critical since DynamoDB is a public resource, but it should be accessed on the internal AWS network for migration via VPC Endpoint.
DNS Resolution from VPC: Explained in the first article.
IAM Roles: In addition to the roles described in the first article, DynamoDB outbound task needs additional roles for Dynamo Access. DMS creates an exception table that also needs to be included in the access policy. For example:
"Resource": [
"arn:aws:dynamodb:eu-central-1:<account_number>:table/t_abc",
"arn:aws:dynamodb:eu-central-1:<account_number>:table/awsdms_apply_exceptions",
"arn:aws:dynamodb:eu-central-1:<account_number>:table/awsdms_full_load_exceptions"
]
Having set the background and some insights in the design, the sections to follow explain a series of decisions or practices followed during the migration to address specific issues and some insights on how key aspects of migration were handled pragmatically.
Dealing With Schema
There is a fundamental difference in the concept of modeling data between Non-SQL and RDBMS, and that trickles down to DynamoDB as well. It is critical that DynamoDB modeling is done before starting the migration to have a clear view of what transformations are needed from source tables.
The only attributes that are fixed for a Dynamo table are Partition-Key and Sort-Key. All other attributes are “values” to those keys and can be completely different. It is possible that one DynamoDB table models multiple entities and their relationships, and the data migration can be targeted from multiple source tables to a single table with a free format for PK and SK, i.e., without naming the PK and SK columns to a business field. During the migration, the columns would need to be transformed with DMS table-mapping rules by combining the columns through expressions. All the other attributes from the source table are transformed as-is with a supported data type conversion. Again, transformation rules can enable augmenting these attributes or simply dropping them.
AWS SCT supports DynamoDB as a target, but given the data manipulations needed during the migrations, it is preferable to use the DMS Task Rules.
Dealing With Primary Keys
During the migration of data from source Oracle tables, the DynamoDB entities can be constructed differently, depending on the DynamoDB entity model created.
Same PK as Designated as PK in the Source Table
1. This is the default option where DMS detects the PK attribute from the source table and creates a corresponding column in DynamoDB as a partition key, or if a DynamoDB table is already created, DMS looks for the same column name unless a rename transformation rule is applied in DMS task.
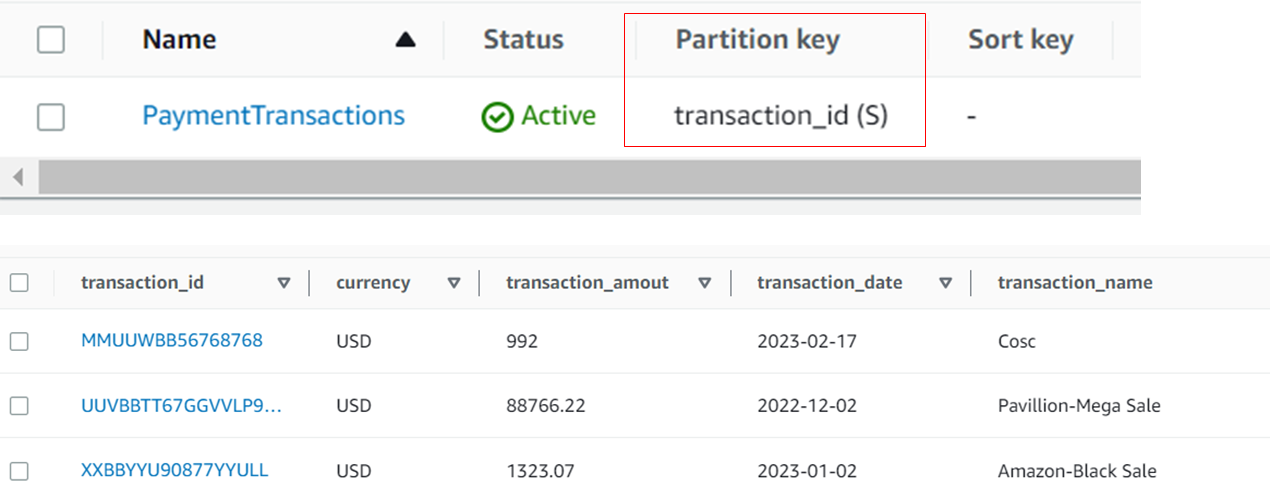
Consider this source table:

This table has a single Primary Key field – transaction_id. Migrating this table with the same structure would result in transaction_id as PK and no SK.
2. The DMS does not support the use of composite primary keys directly since there is no way to model that in DynamoDB.
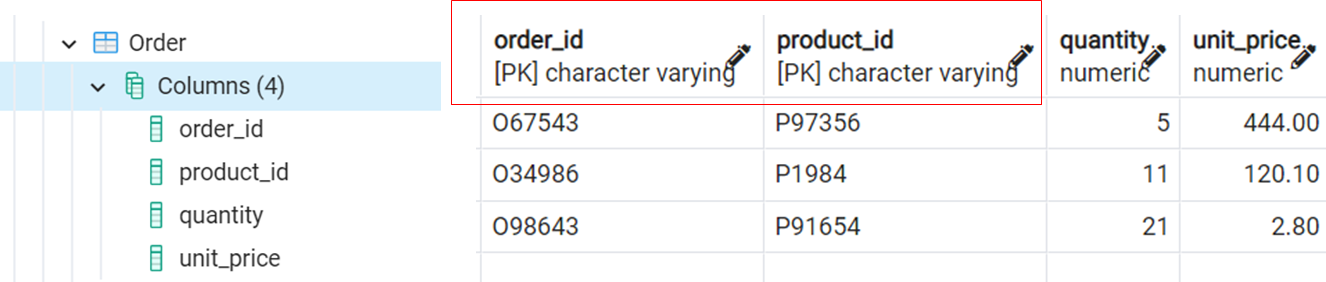
Consider this source table. The Order table has a composite key, i.e., order_id and product_id.
With this setup, DMS assessment and DMS task both result in errors:
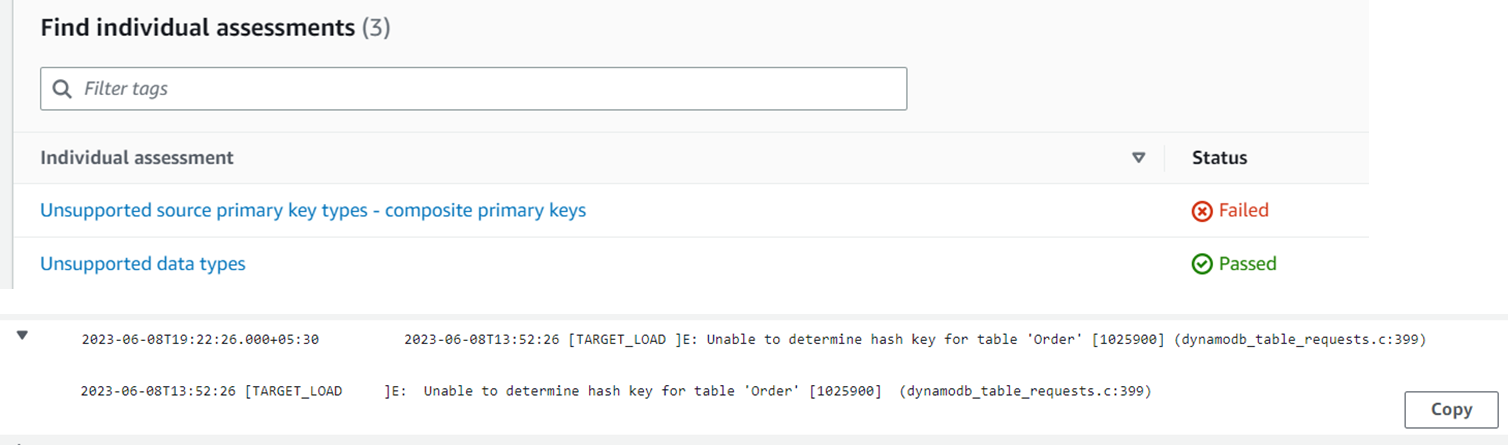
To migrate in this scenario, the PK constraint in the source table needs to be dropped and applied to a single column (DMS needs to ‘see’ one PK). The source table should not be operational during this migration.

Post which, there can be two options to model and migrate in the target DynamoDB table.
2.a To combine the composite key attribute in the source table into a common PK column with prefixes and separators. Using the DMS Task transformation rules, the composite key fields can be combined. Such as:

DMS Task Transformation Rule:
{
"rule-type": "transformation",
"rule-id": "230591587",
"rule-name": "230591587",
"rule-target": "column",
"object-locator": {
"schema-name": "corpdb",
"table-name": "Order"
},
"rule-action": "add-column",
"value": "PK",
"expression": "'O='||$order_id||'#P='||$product_id",
"old-value": null,
"data-type": {
"type": "string",
"length": "10000",
"scale": ""
}
}
2.b To choose a DynamoDB PK from one composite key attribute and use the remaining attribute as DynamoDB SK. Create a DynamoDB before migration with the two PK and SK columns. Then start the DMS task with no specific transformation rules in this case since the column names match.

3. Any other column from the source table can be used as a sort key if needed. Since the composite key is not supported, the DMS migration to DynamoDB can be used to update the model to use any other sort key if the DynamoDB model requires that. Keeping in mind that DMS drops null item attributes, another sort key attribute for the same table in DynamoDB would be a not-null. It would work in the same way as #2.
Changed PK From Source Table
Migrating the source table to fit into the target DynamoDB model, it is possible that a different PK must be used. This is needed for creating alternate data projections in the target from the same source table, especially for the transaction tables. It is possible in many cases that either LSI or GSI or both can be used to achieve the same result. But having a primary table redefined with a new PK is clean and cohesive.
Consider this table that contains promotion requests from various sales systems. The promotions can be requested for an active transaction or without one.
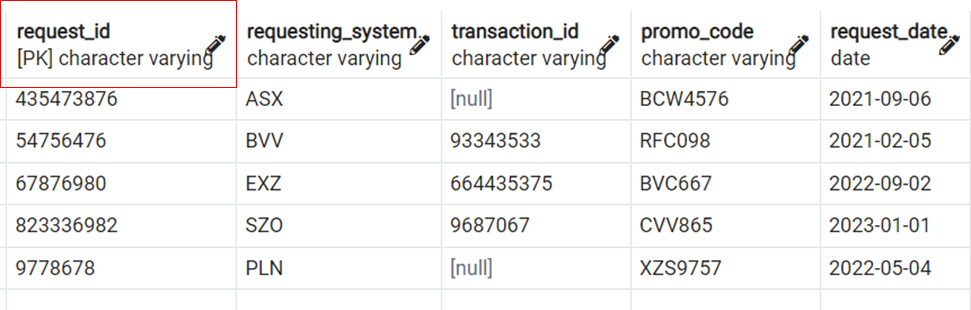
1. If another unique, not-null field exists in the table, then it can be used to redefine the primary key with a “define-primary-key” DMS Rule action. For example, redefine the promo_code as PK in the target table (assuming a new promo_code is generated for each request) since promo_code is unique and not null.
{
"rule-type": "transformation",
"rule-id": "287800152",
"rule-name": "287800152",
"rule-target": "table",
"object-locator": {
"schema-name": "corpdb",
"table-name": "Promotions"
},
"rule-action": "define-primary-key",
"value": null,
"old-value": null,
"primary-key-def": {
"name": "promo_code",
"columns": [
"promo_code"
]
}
}
With this rule, DMS looks for promo_code defined in the existing DynamoDB table as PK or created if the target table does not exist.

2. Now consider that during migration, a projection of all transactions where a promo was applied is needed. A DynamoDB table with transaction_id as PK is created.
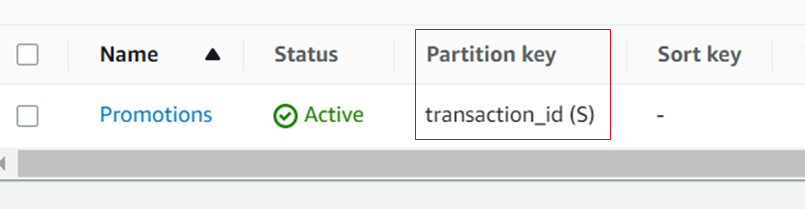
Once DMS encounters the first null record with transaction_id, it throws an error and stops migration.

2.a If the null transaction_id records can be filtered, then with the same DynamoDB table model, a DMS task filter rule can be used to filter null transaction_id records.
{
"rule-type": "selection",
"rule-id": "285090764",
"rule-name": "285090764",
"object-locator": {
"schema-name": "corpdb",
"table-name": "Promotions"
},
"rule-action": "include",
"filters": [
{
"filter-type": "source",
"column-name": "transaction_id",
"filter-conditions": [
{
"filter-operator": "notnull"
}
]
}
]
}
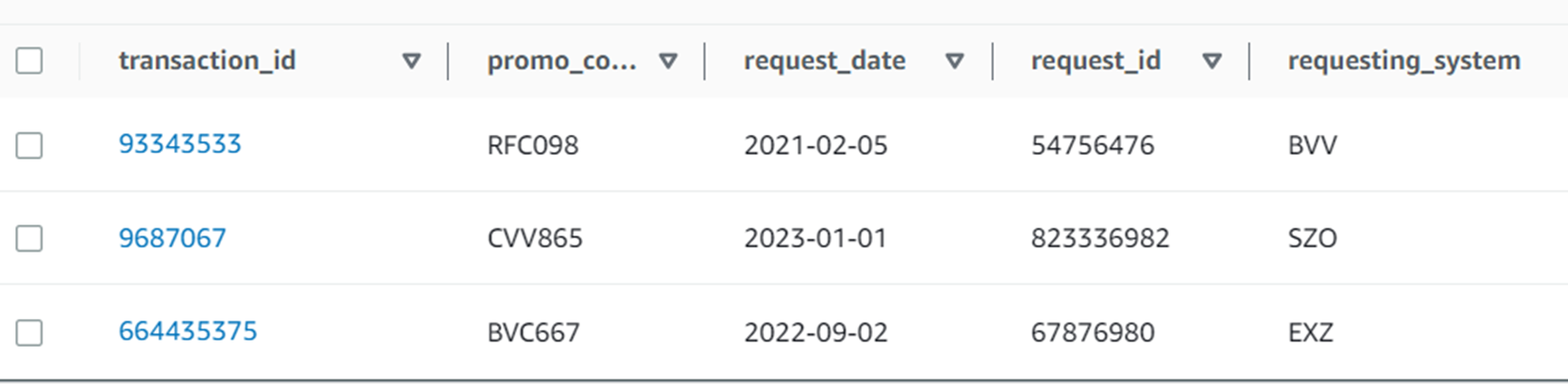
Filtering like this would result in a loss of data for promotions applied to cases where transaction_id was not used. This may be okay. But in cases where such data needs to be migrated, a different approach is needed.
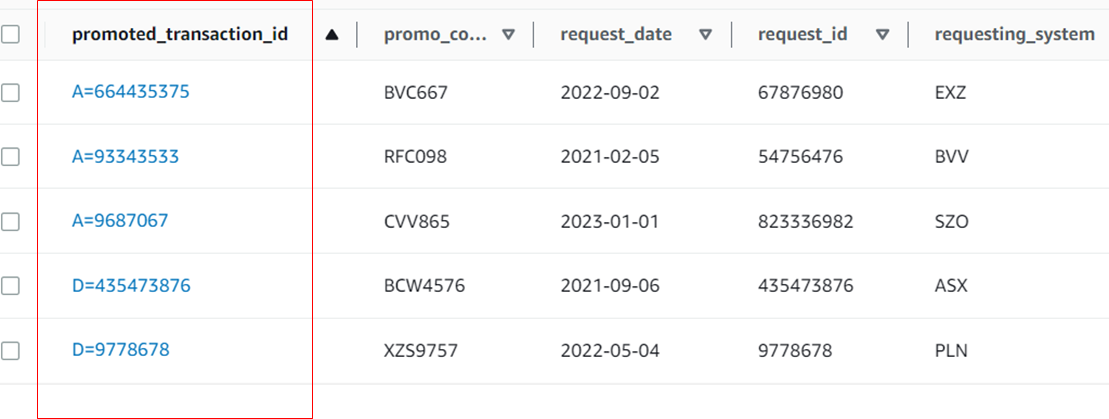
2.b Since transaction_id is nullable, a DMS Task rule needs to detect the null value and use a different notation to save such records and allow the rest of the non-null transaction ids to be saved normally. To support these semantics, a new column can be used to denote the PK.
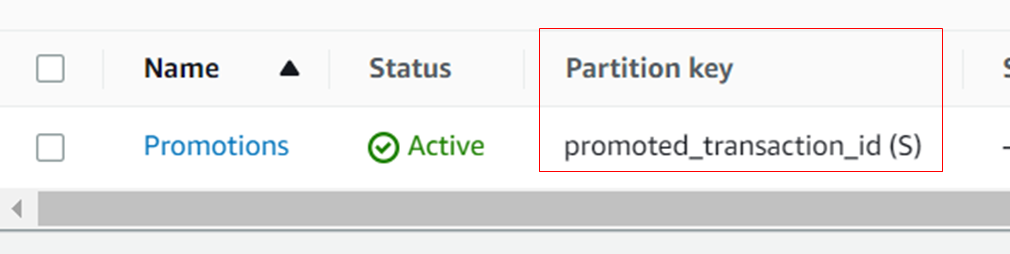
The DMS Task rule uses SQLLite coalesce function to create and add a new column promoted_transaction_id. For all notnull-transactionid rows, the function adds a prefix A (active), and for null transaction_ids, it adds a prefix D to some not-null columns (in this case, request_id). The client application used an appropriate prefix while retrieving the data. In this case, the original table data is not lost.
{
"rule-type": "transformation",
"rule-id": "291064633",
"rule-name": "291064633",
"rule-target": "table",
"object-locator": {
"schema-name": "corpdb",
"table-name": "Promotions"
},
"rule-action": "define-primary-key",
"value": null,
"old-value": null,
"primary-key-def": {
"name": "promoted_transaction_id",
"columns": [
"promoted_transaction_id"
]
}
},
{
"rule-type": "transformation",
"rule-id": "289759665",
"rule-name": "289759665",
"rule-target": "column",
"object-locator": {
"schema-name": "corpdb",
"table-name": "Promotions"
},
"rule-action": "add-column",
"value": "promoted_transaction_id",
"expression": "coalesce( 'A='||$transaction_id,'D='||$request_id)",
"old-value": null,
"data-type": {
"type": "string",
"length": "1000",
"scale": ""
}
}
WCUs in DynamoDB During Migration
The DynamoDB capacity provisioning is based on two modes “Provisioned” and “On-Demand.” During migration, depending on the nature of migration, using an On-Demand mode should be preferred since it allows controlling the migration concurrency and commit rate from the DMS task (explained in sections below). With a provisioned concurrency mode, the DMS task results in throttling errors and time-outs, and it is simply very convenient to allow the migration to go with on-demand provisioning and, if needed, update the table definition later to use the provisioned mode.
DMS does not support data validation for the DynamoDB target, so data is not read by the DMS task from the DynamoDB table. The RCUs are not a big factor during migration.
Account and Table Level Quotas
Even with an on-demand provisioning mode, AWS puts a quota limit on table-level read and write throughput limit. With a provisioned concurrency, the quotas are at an account level (so combined throughput for all DynamoDB tables).
In On-Demand provisioning mode, the default throughput quota per table is 40,000 RCUs and 40,000 WCUs.

These are soft limits and can be increased via a service request.
Now, depending on the amount of data for transfer and the design of the DMS task, it is important to calculate the peak WCU during migration and to make sure that sufficient capacity is provisioned.
Controlling Migration Parallelism and Throughput
Here it is assumed that there is a single table in the scope of migration to the target DynamoDB table. DMS also allows multiple tables reads via the flag: MaxFullLoadSubTasks. The maximum value for this setting is 49. This setting is more relevant where multiple tables in the same schema are transferred between two RDBM instances. The case of loading data to DynamoDB requires specific transformations, and we don’t expect RDBMs and DynamoDB to have 1:1 correspondence.
By default, the DMS task during Full Load uses a single thread to read the values from the source table and uses a commit rate of 10,000, i.e., 10,000 items are inserted in the DynamoDB table via a single thread if the write capacity and quotas on WCU allow it. A single thread will read 10,000 records, apply the transformations, and then commit in DynamoDB.
AWS DMS sets default WCUs for migration tasks. By default, the WCU is 200. This is a DMS-defined limit and does not depend on the target DynamoDB Table’s provisioning mode.
For large tables, the default settings are not enough and can be improved with the following task settings:
ParallelLoadThreads: By default, the value is 0, so there is no parallelism. The maximum value for a DynamoDB target is 200. This configuration enables the DMS task to spawn multiple threads to execute the source load and target commit operations concurrently. DMS sets WCU for migration tasks in proportion to the ParallelLoadThreads.
(WCU = 200 * ParallelLoadThreads)
ParallelLoadBufferSize: Should be used with ParallelLoadThreads, to configure the maximum number of records to store in the DMS buffer that parallel load threads use to load data to the target. ParallelLoadBufferSize is valid only when there is more than one thread.
CommitRate: configures a maximum number of records that can be transferred together at the target instance during full load.
To represent these logically:
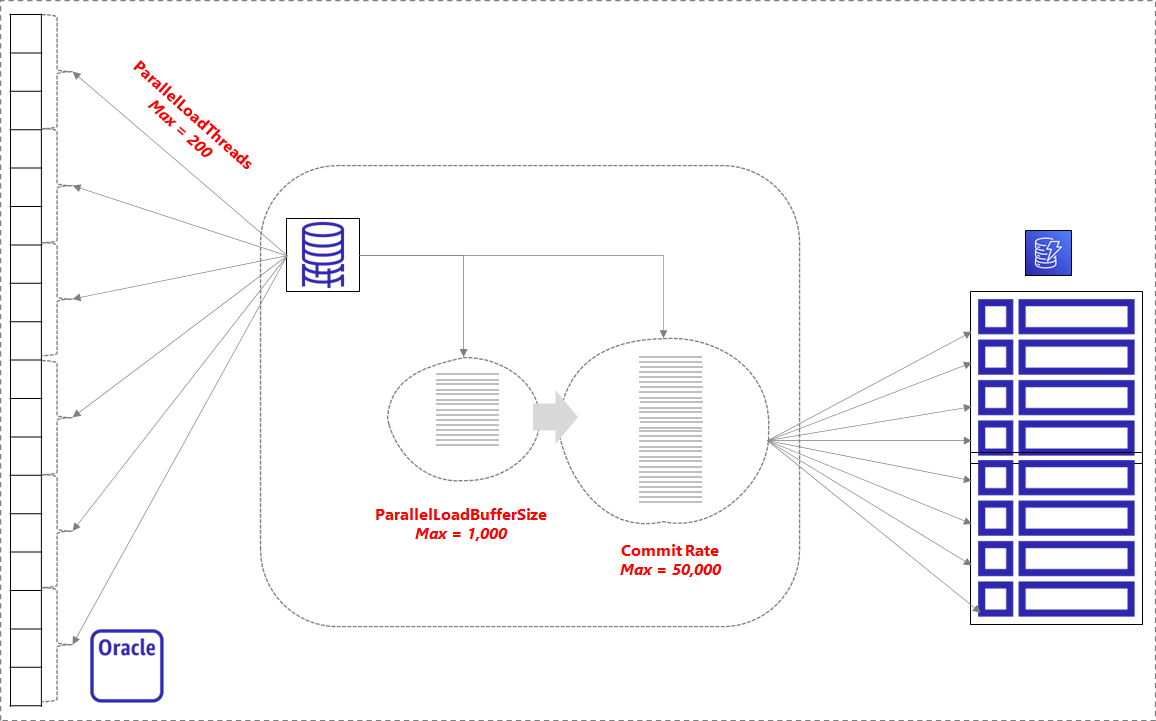
- The greater the value of ParallelLoadThreads, the greater is the chance to achieve throughput as per commit rate.
- A quota on table-level write throughput for on-demand provisioning is 40,000 WCU, which is also the DMS WCU for a maximum ParallelLoadThreads (200 * 200).
- Depending on the size of items after applying DMS task transformations, CommitRate should be selected to match the derived WCU (i.e., 200 * ParallelLoadThreads), i.e., the number of items to be written as part of CommitRate number should utilize the WCU that is within the derived WCU. (For items up to 1 KB in size, one WCU can perform one standard write request per second.).
- More parallel threads put demands on the CPU (to process transformations), memory (to store the records in various buffers), and IO (PutItems as per large commit rate). So DMS instance type needs to be selected accordingly.
- In effect, the total threads during Full Load is (MaxFullLoadSubTasks * ParallelLoadThreads)
Migrating Sequences
In RDBMS, Sequences provide a transactionally consistent way to generate unique sequences via a sequence definition. DynamoDB takes a different architectural approach and recommends using UUIDs to generate unique identifiers. But there are migration cases where dependencies on upstream and downstream services mandate that the sequences need to be generated in the same way as before.
DynamoDB does not support sequences. So, while it is a normal data migration to transfer the sequence numbers generated in the source tables, it is not an object that can be applied in DynamoDB like how it can be done, for example, for transfers between Oracle and PostgreSQL (Refer to #3 in previous post).
To support a sequence generation, it is left to the AWS DynamoDB SDK, using a technique of Optimistic Locking, which uses a previously saved version attribute and allows incrementing the sequence in the client code and saving it back using DynamoDB Transaction Writes. A “seed” generator record in the DynamoDB table is created with the last generated value in the source sequence.
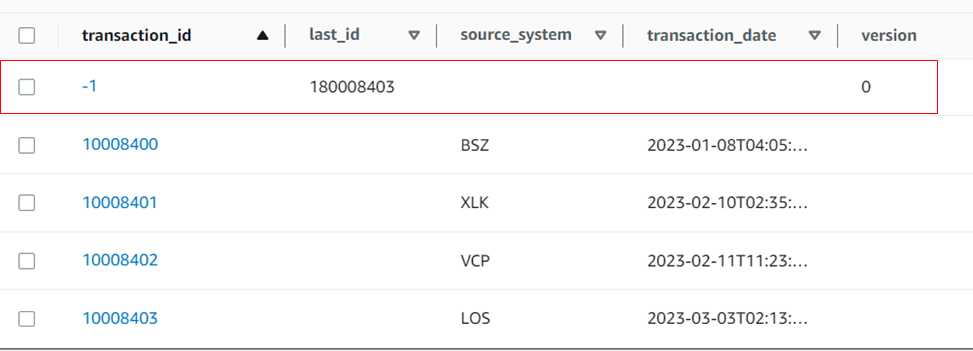
Consider this table which has a sequence number field to generate transaction_id:
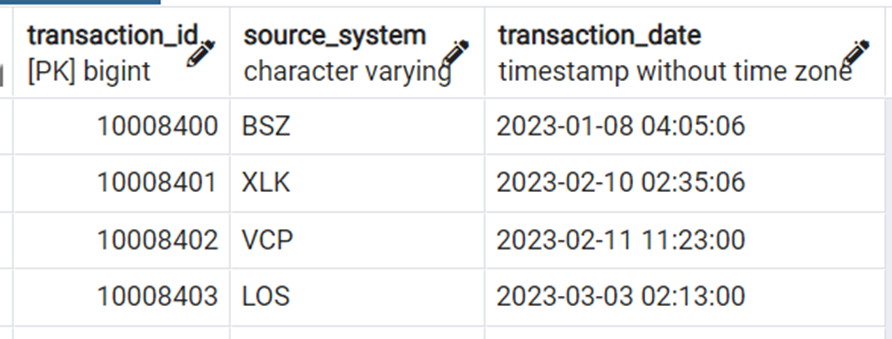
After the data is migrated, the sequence numbers are in the PK field of the corresponding DynamoDB table.
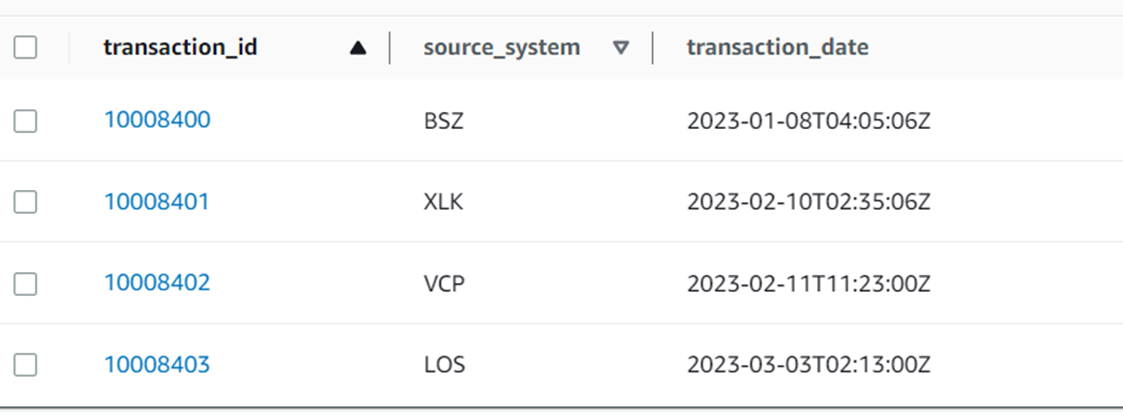
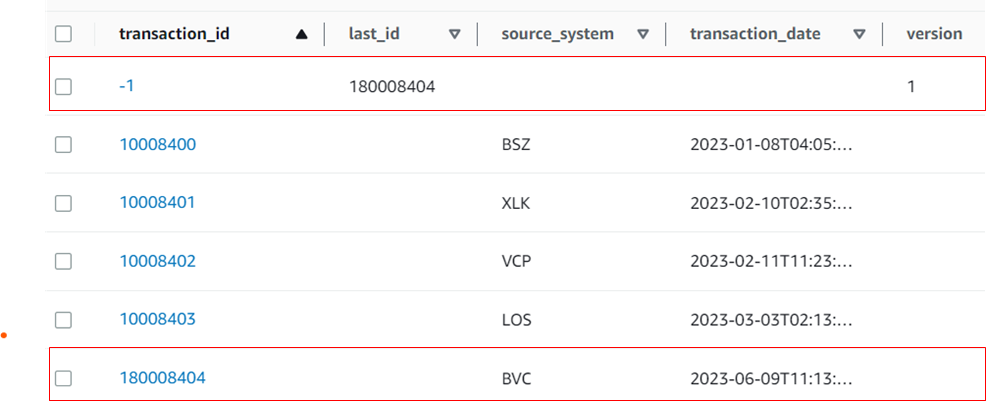
To generate sequences after 10008403, a sequence number meta-data record has to be added and then used in client code to read and increment the sequence.
{
"transaction_id": {
"N": "-1"
},
"last_id": {
"N": "180008403"
},
"version": {
"N": "0"
}
}
Transaction_id = -1 is used only for special cases for the next number generation.
Post generation:
An example of implementing this with AWS DynamoDB SDK for Java:
int retry_count = 0;
try {
while (retry_count < RETRY_COUNT) {
Instant now = Instant.now();
TranGen trangen = mapper.load(TranGen.class, -1L);
Long last_id = trangen.getLast_id();
last_id++;
trangen.setLast_id(last_id);
TranBean tranbean = new TranBean(last_id, system, now.toString());
TransactionWriteRequest transactionWriteRequest = new TransactionWriteRequest();
transactionWriteRequest.addPut(tranbean);// Transaction # 1 :PutItem
transactionWriteRequest.addUpdate(trangen);// Transaction # 2 :UpdateItem
retry_count++;
mapper.transactionWrite(transactionWriteRequest);
return new TranGenResponse(tranbean.getTransaction_id(), tranbean.getSource_system(), tranbean.getTransaction_date());
}
} catch (TransactionCanceledException ccfe) {
System.out.println(ccfe);
if (retry_count == RETRY_COUNT) {
System.out.println("Max retries reached. Permanent Error");
throw new IllegalStateException("Max retried reaches. Permanent Error");
} else {
System.out.println("Retrying.. ");
}
}
DMS Data Type Support for DynamoDB
AWS DMS supports 3 DynamoDB types: String, Number, and Boolean, and attempts to convert all source types into these three. This is an issue for Date/Timestamp fields which are converted into String types.
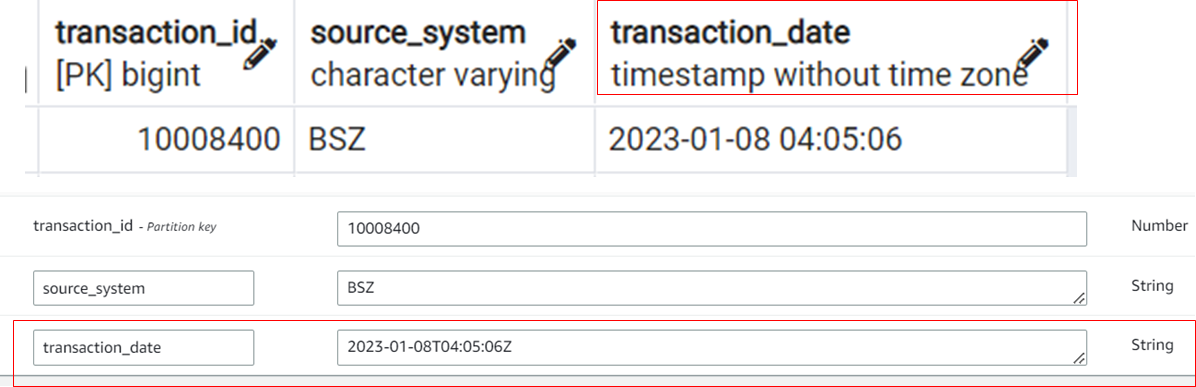
Depending on the usage of date attributes, this can be an issue, but as long as this attribute is not used as part of PK, it is usually up to the client to do any type of conversion for the date. To support any Date/Time operations, like querying for dates less than a passed date, the values need to be converted into milliseconds and stored as numbers in the table as additional columns. DMS transformation rules do not provide this automatic conversion to milliseconds from a source date as of now.
Disable PITR
During the migration, PITR can be disabled for better performance. Dynamo Allows turning on PITR, and if this is done post-full load, the PITR can be done for the data migrated from the source.
Opinions expressed by DZone contributors are their own.
Comments