Unveiling the Evolution and Future of Fine-Tuning Large Language Models
This article explores the evolution of Large Language Models (LLMs) like GPT-3 and GPT-4, emphasizing fine-tuning for task-specific customization.
Join the DZone community and get the full member experience.
Join For FreeAs the landscape of artificial intelligence continues to evolve, the development and refinement of Large Language Models (LLMs) such as GPT-3. GPT-4 has marked significant advancements in how these models are applied across various industries. This whitepaper delves into the evolution of LLMs, explores the strategic application of fine-tuning, discusses the use cases for different fine-tuning approaches, and examines the capabilities of new technologies like LoRAX which is reshaping the future of fine-tuning at scale.
Evolution of Large Language Models
Originally simple text prediction tools, LLMs have transformed into robust, context-aware systems capable of generating human-like text. This evolution was largely propelled by innovations such as the transformer architecture, which revolutionized data processing within neural networks. Recent developments have seen these models expand in size and capability, integrating vast amounts of data (hence called pre-trained models) to improve their predictive accuracies and contextual sensitivities.
What Is Fine-Tuning
Customization of LLMs is fine-tuning, There are two approaches to customization of LLMs:
- Add data to the prompt (either through a few shot examples or through your corpus data)
- Add data to the model that teaches the model a new skill, and changes its behavior.
Motivations for Fine-Tuning
While pre-trained LLMs offer impressive performance out of the box, fine-tuning allows practitioners to adapt these models to specific tasks or domains, thereby improving their effectiveness and relevance. Fine-tuning becomes necessary when the task at hand requires specialized knowledge or when the available pre-trained model needs to be customized for a particular use case. By fine-tuning, practitioners can leverage the general language understanding capabilities of pre-trained LLMs while tailoring them to specific requirements, leading to better performance and efficiency.
Practical Considerations and When To Fine-Tune
Fine-tuning is particularly valuable when:
- A model needs to learn a specific skill or change its behavior significantly.
- There is a need to reduce latency or operational costs by substituting a large, general-purpose model with a more tailored, efficient one.
- The complexity of prompts exceeds practical limits, making embedded fine-tuning a necessity to handle complex instructions or numerous edge cases within the model itself.
Fine-tuning should be considered a complementary strategy alongside prompt engineering, and retrieval techniques (Retrieval Augmented Generation/RAG) often requiring both to achieve optimal performance. Starting with prompt engineering is advisable to gauge how far the base model can go before investing in fine-tuning.
Use Cases for Fine-Tuning Approaches
- Prompt-based fine-tuning: This technique is particularly effective in scenarios where quick adaptation is needed with minimal data. It is ideal for tasks that require immediate model deployment without extensive retraining, utilizing zero-shot or few-shot learning methods to adapt the model to new domains swiftly.
- RAG-based fine-tuning: Retrieval-augmented generation integrates external knowledge bases with LLMs to enhance their output, making them more accurate and contextually relevant. This approach is valuable for applications that benefit from up-to-date external data, such as real-time customer service applications.
- Supervised fine-tuning(SFT): This is the most common form of fine-tuning, where a model is further trained (fine-tuned) on a smaller, domain-specific dataset. It helps the model to perform better on tasks related to that dataset. Azure OpenAI supports SFT using LORA, enabling users to tailor models to their specific needs with their datasets.
- Reinforcement Learning from Human Feedback (RLHF): In this approach, human feedback is used to reward or penalize the model based on its outputs, guiding it toward desired behaviors. This method is more complex and resource-intensive because it requires setting up a reinforcement learning loop with human reviewers in the loop. OpenAI has experimented with RLHF in research settings, particularly for aligning GPT-3 and other models with human values.
- Parameter-efficient fine-tuning (PEFT): This refers to methods that fine-tune a large language model with the goal of making minimal changes to the model's parameters. The idea is to achieve performance improvements on specific tasks without having to retrain the entire model, which can be computationally expensive and time-consuming.
- Fine-tuning at scale: The need to apply model adjustments broadly across various tasks necessitates scaling the fine-tuning process. This approach optimizes multiple models or various aspects of a single model to efficiently handle diverse and extensive tasks.
The LoRAX Open Source Framework: A Paradigm Shift in LLM Efficiency
A groundbreaking development in the field of LLMs is the LoRAX framework, which enables the deployment of hundreds of fine-tuned models on a single GPU. This system significantly reduces the costs and logistical complexities associated with running multiple LLMs in parallel. LoRAX employs a novel approach called "parameter-efficient fine-tuning," which adds a minimal number of trainable parameters to a large pre-trained model. This technique, often utilizing methods such as low-rank adaptation (LoRA), maintains the integrity of the original model's weights while making precise adjustments to tailor the model for specific tasks.
The difference between Full Fine Tuning and Parameter Efficient Fine Tuning is illustrated below:
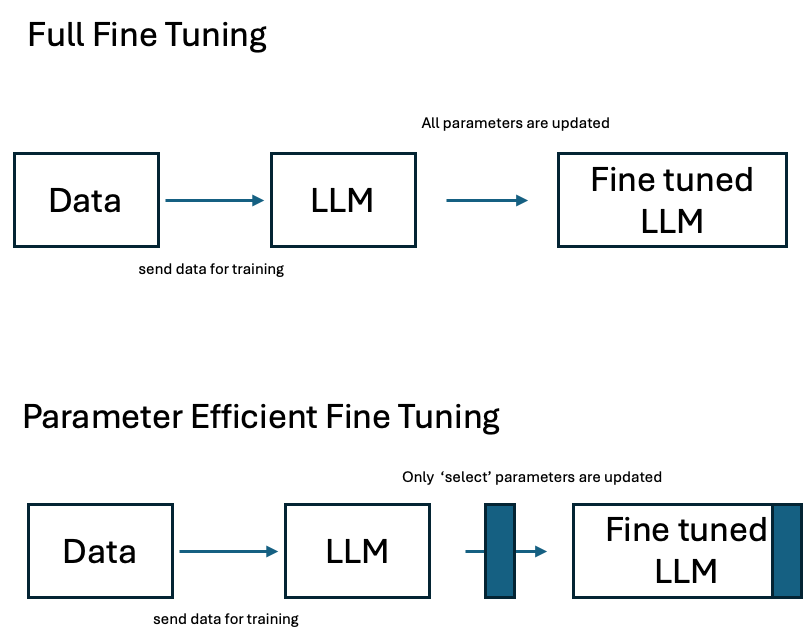
As per the above illustration, Full Fine Tuning is expensive and not always required unless there is research and development for building a new model grounds up needed. To optimize the cost at the same time you own the model and the IP, Parameter Efficient Fine Tuning is the recommended fine-tuning approach.
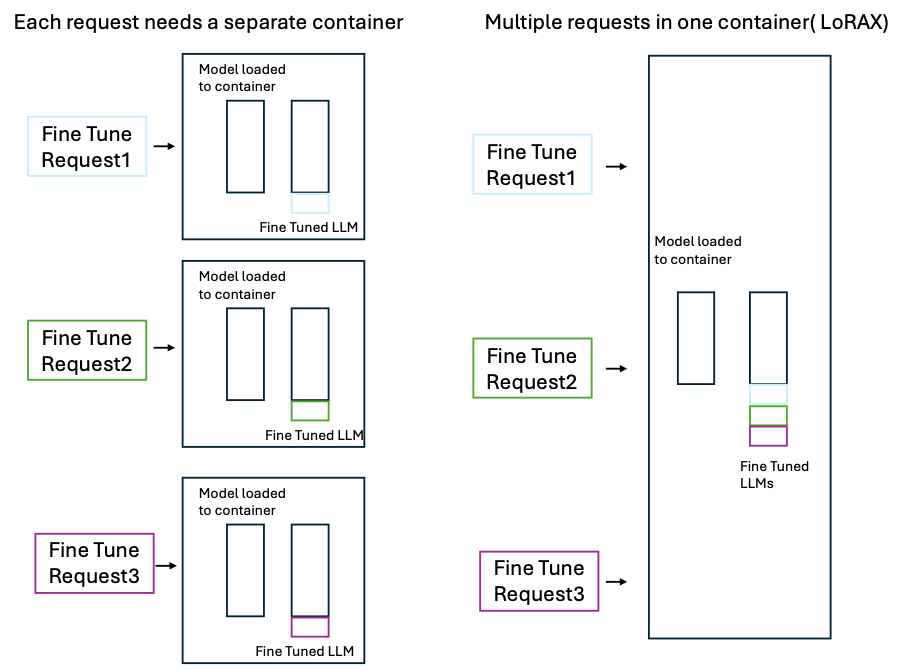
With respect to the model deployment for fine-tuning, there needs to be a conscious decision on how many models need to be fine-tuned for your business use case will drive the necessity of leveraging LoRAX.
Two deployment approaches for model fine-tuning at scale are illustrated. The first one is without LoRAX and the second approach is with LoRAX which allows fine-tuning models at scale.
Capabilities and Innovations of Lorax
LoRAX's capabilities extend beyond simple cost reduction. It introduces several innovative features that enhance its performance:
- Dynamic adapter loading: This feature allows the system to load fine-tuning adapters on demand when new requests come in, optimizing memory usage and reducing latency.
- Multi-tier weight cache: LoRAX uses a sophisticated caching system that utilizes GPU, CPU, and disk storage to manage model weights dynamically. This system ensures that active models are readily available while less frequently used models are efficiently stored until needed.
- Continuous multi-adapter batching: This technique allows multiple requests to be processed in batches through the LLM, significantly increasing throughput. It adapts continuous batching techniques to manage multiple adapters simultaneously, maintaining high utilization and reducing computational waste.
The Future of Fine-Tuning
The future of fine-tuning at scale promises more automated, intelligent systems that reduce the reliance on large computational resources. Innovations like LoRAX are paving the way toward more sustainable AI practices by enabling more precise model customization without the extensive overhead typically associated with large-scale LLM deployments. As AI technology continues to advance, we can expect to see an increase in solutions that not only enhance performance but also promote greater personalization, efficiency, and lower environmental impact.
In conclusion, the development of LLMs and the advent of technologies like LoRAX (LoRA Exchange) highlight a significant shift towards more specialized, efficient, and scalable AI solutions. These advancements are set to revolutionize how businesses deploy AI, making it a more integral and tailored part of their operational toolkit, thereby driving further adoption across various sectors.
Opinions expressed by DZone contributors are their own.
Comments