Understanding Kafka-on-Pulsar (KoP): Yesterday, Today, and Tomorrow
Diving into KoP concepts, answering frequently asked questions, and the latest and future improvements the KoP community has made and will make to the project.
Join the DZone community and get the full member experience.
Join For FreeApache Pulsar and Apache Kafka share a similar data model around logs. This makes it possible to implement a Kafka-compatible protocol handler so that Kafka users can migrate existing Kafka applications and services to Pulsar without modifying the code. It also allows these applications to leverage various Pulsar features such as multi-tenancy, infinite event stream retention, and serverless event processing. This is where the open-source project Kafka-on-Pulsar (KoP) comes in.
Why Did the Community Develop KoP?
To begin, I think it is important to answer a key question: “Why did you develop it?” As a maintainer of the KoP project, I notice that this is usually the first thing that comes to mind for a new community member. To answer this question, let’s have a quick look at the basics of Pulsar and Kafka.
Pulsar and Kafka have some common concepts. For example, they both have producers and consumers with brokers hosting different topics to serve them. Additionally, both of them support topic partitions to achieve better parallelism.
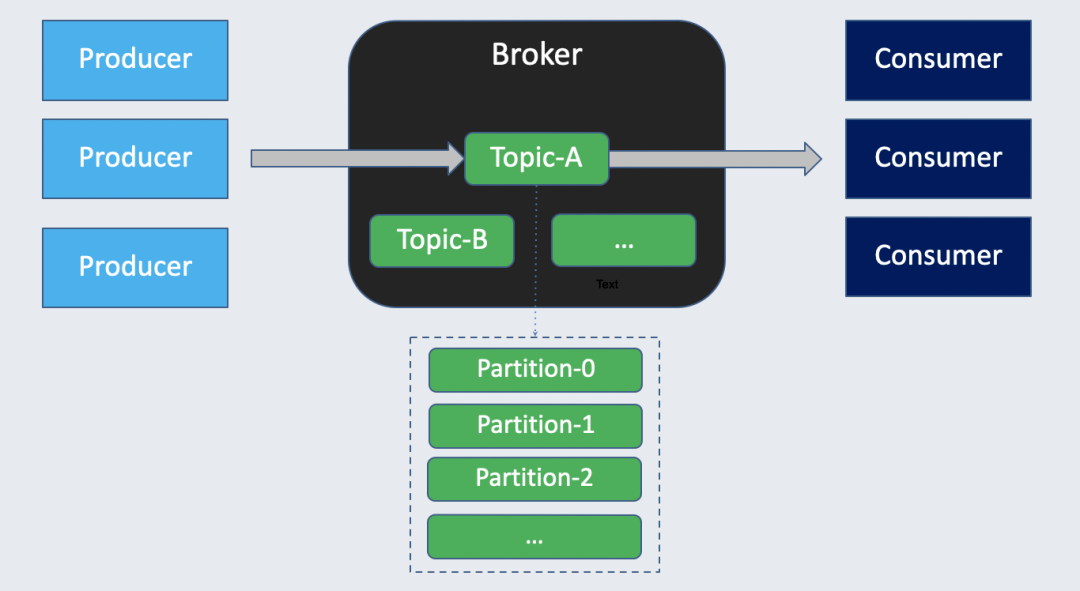
In Kafka, the client sends messages to the leader broker through the PRODUCE request. These messages are persisted to the node locally. Each follower reads the data from the leader through the FETCH request to store a copy of the messages. In this leader-follower architecture, each broker needs to handle both data processing and storage.
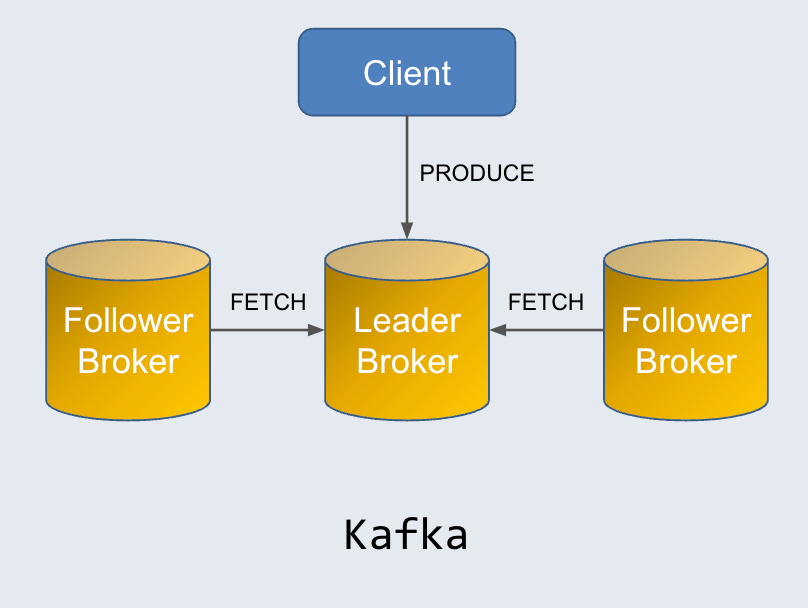
One disadvantage of the design is that it guarantees the most recent and relevant data replica is only stored on the leader broker, which serves both producers and consumers. This means a Kafka cluster can be overwhelmed during traffic bursts as the load may not be spread across followers.
By contrast, Pulsar separates serving (brokers) and storage (bookies) into different layers. At the computing layer, all Pulsar brokers are stateless and equivalent to each other. As shown in the figure below, the client sends messages to the broker through the SEND request. After processing the messages, the broker delivers them to different bookies through the ADD_ENTRY request. Specifically, data are written to bookies based on the configured writing strategy (that is, the values of ensemble size, write quorum, and ack quorum). This helps achieve data high availability across storage nodes. Most importantly, both brokers and bookies can be easily scaled at their own layer, not impacting the other.
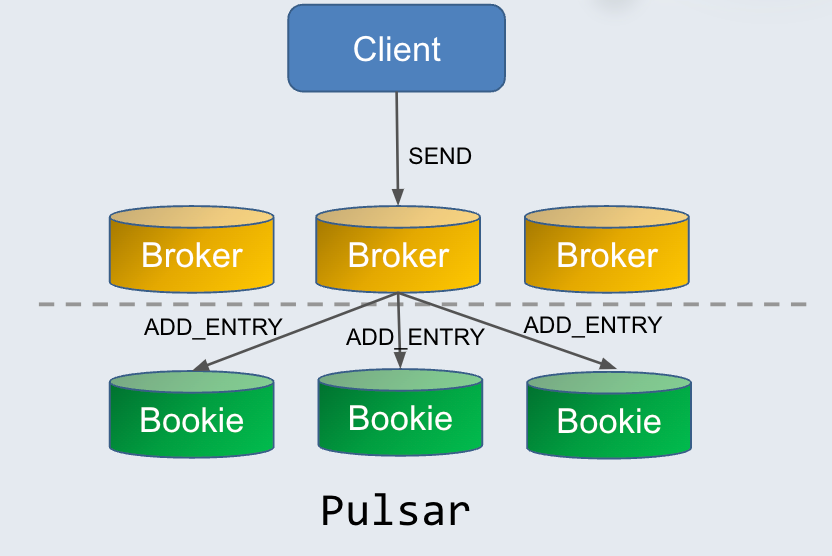
This cloud-native architecture of Pulsar features great scalability, availability, and resiliency, providing users with solutions to some key pain points in Kafka. Therefore, many users are looking for a graceful plan to migrate from Kafka to Pulsar.
Migration Plans
Before KoP was developed, migrating from Kafka to Pulsar was no easy task. I have noticed that some community members used and perhaps are still using the following ways:
Update Clients
Users need to rewrite their code and optimize some client-side configurations. Admittedly, this is not an ideal solution as it may incur additional costs. Apart from that, Pulsar’s ecosystem still has a long way to go compared with Kafka’s. The latter enjoys a more mature ecosystem in many ways, such as multi-language client support and third-party integrations. This means rewriting the code can cause many problems when you try to use tools in Kafka’s ecosystem.
Pulsar Adaptor for Apache Kafka
Initially, the Pulsar community tried to solve the migration issue by developing a tool called Pulsar Adaptor for Apache Kafka. It allows users to replace the Kafka client dependency with the Pulsar Kafka wrapper. It does not require any changes to the existing code. Nevertheless, its disadvantages are obvious:
- Only applicable to Java-based clients
- Problems in handling Kafka offsets
- Users still need to learn some Pulsar client configurations
Kafka-on-Pulsar (KoP)
To provide a smoother migration experience for users, the KoP community came up with a new solution. They decided to bring the native Kafka protocol support to Pulsar by introducing a Kafka protocol handler on Pulsar brokers. Protocol handlers were a new feature introduced in Pulsar 2.5.0. They allow Pulsar brokers to support other messaging protocols, including Kafka, AMQP, and MQTT.
Compared with the above-mentioned migration plans, KoP features the following key benefits:
- No Code Change: Users do not need to modify any code in their Kafka applications, including clients written in different languages, the applications themselves, and third-party components
- Great Compatibility: KoP is compatible with the majority of tools in the Kafka ecosystem. It currently supports Kafka 0.9+
- Direct Interaction With Pulsar Brokers: Before KoP was designed, some users tried to make the Pulsar client serve the request sent by the Kafka client by creating a proxy layer in the middle. This might impact performance as it entailed additional routing requests. By comparison, KoP allows clients to directly communicate with Pulsar brokers without compromising performance
To learn more about the reasons for developing KoP, refer to the KoP white paper.
How KoP Works
KoP is implemented as a protocol handler plugin with the protocol name "Kafka." It is loaded when the Pulsar broker restarts. By default, Kafka and Pulsar clients can work at the same time.
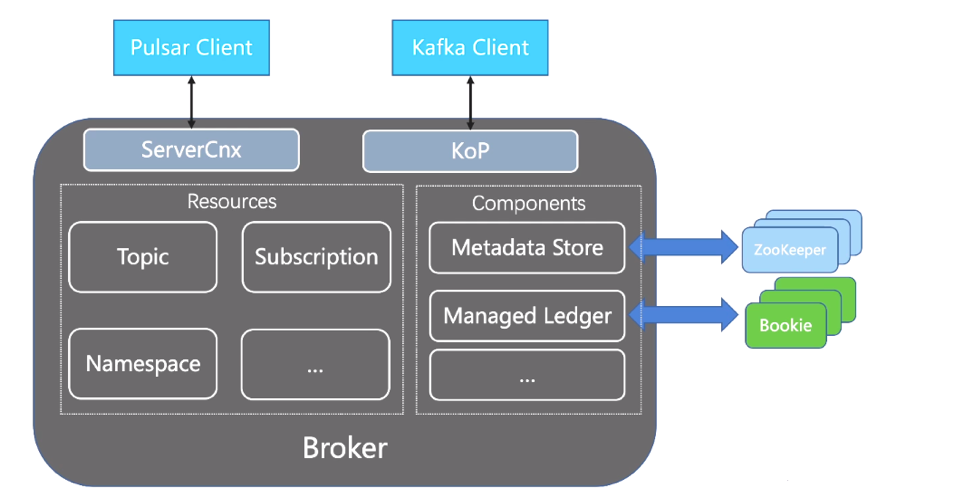
If you check the source code of Pulsar, you can find a class called ServerCnx, which exposes port 6650. After the Pulsar client sends requests to the port, ServerCnx then parses these requests so the broker can take action accordingly, such as reading and writing data from and to BookKeeper.

After you enable KoP for your cluster, it exposes port 9092 so the Kafka client can send requests to it. Similar to ServerCnx, KoP processes these requests and then asks the broker to respond. Both ServerCnx and KoP have access to all broker resources, such as topics and subscriptions.
Implementation and Design
Let’s examine some key concepts, especially how they are implemented in KoP.
Topics and Partitions
In Kafka, all the topics are stored in one flat namespace. In Pulsar’s multi-tenant architecture, messages are organized in a three-level hierarchy of tenants, namespaces, and topics. A Pulsar topic can be either persistent or non-persistent. As Kafka persists, all messages and all topics in KoP are persistent. The following is the Pulsar topic naming convention (the partition is part of the topic name as the suffix):
{persistent | non-persistent}://tenant/namespace/topic-partition-0
To enable Kafka users to leverage the multi-tenancy feature of Pulsar, KoP allows them to use a short topic name directly as it provides a default tenant and namespace. At the same time, users can also specify the Pulsar tenant and namespace so that clients can access other topics. See the following table for details:
Kafka topic name |
Tenant |
Namespace |
Short topic name |
my-topic |
<kafkaTenant> |
<kafkaNamespace> |
my-topic |
my-tenant/my-ns/my-topic |
my-tenant |
my-ns |
my-topic |
persistent://my-tenant/my-ns/my-topic |
my-tenant |
my-ns |
my-topic |
In this table, kafkaTenant and kafkaNamespace define the default names that KoP uses for a short topic name, which default to public and default respectively.
Authentication
In production, you may have different namespaces for Pulsar clients and Kafka clients. To improve security, you can enable authentication for KoP. It uses Kafka SASL mechanisms and the token-based Authentication Provider in Pulsar for authentication. Therefore, you need to enable authentication for the following components:
- Pulsar Brokers
- KoP (You need to specify the mechanism by configuring
saslAllowedMechanisms, which currently only supports PLAIN and OAUTHBEARER) - Kafka Clients
See the figure below for how the authentication works:
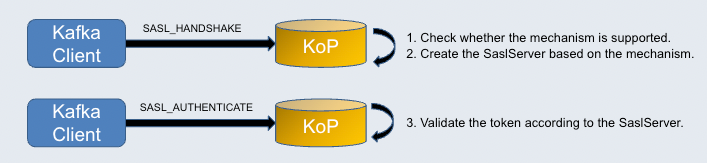
A Kafka client sends the SASL_HANDSHAKE request with the mechanism configured for the Kafka client. KoP then verifies whether the mechanism is supported. If it is, KoP creates the SaslServer based on the mechanism.
After KoP responds to the Kafka client, it sends the SASL_AUTHENTICATE request with a token back to KoP. KoP validates the token according to the SaslServer created before.
For detailed information about how to configure authentication, see Security in Kafka on Pulsar.
Authorization
You can also configure authorization in KoP to define the permissions that different clients have. For example, some clients can only produce messages while others may be able to consume messages. Kafka uses ACLs (Access Control Lists) and resource types to control operations available for different resources. KoP supports the Topic resource type. See the figure below to understand how it maps different ACL operations:
Request |
ACL |
Resource Type |
Pulsar permissions |
FETCH, OFFSET_COMMIT |
READ |
TOPIC |
canConsume |
PRODUCE |
WRITE |
TOPIC |
canProduce |
METADATA, LIST_OFFSET, OFFSET_FETCH |
DESCRIBE |
TOPIC |
canLookup |
CREATE_TOPICS, DELETE_TOPICS, CREATE_PARTITIONS |
CREATE, DELETE, ALTER |
TOPIC |
allowNamespaceOperation |
After authentication is finished, KoP obtains an authorization ID (or a Pulsar role) and sends it to AuthorizationService on the broker.
Note: A Pulsar role is a string, which can represent a single or multiple clients. Roles are used to manage client permissions, such as producing or consuming messages on certain topics. Pulsar uses authentication providers to establish the identity of a client and then assign a role token to that client. This role token is then used for authorization and ACLs to determine what the client is authorized to do.
Group Coordinator
Implementing the Kafka group coordinator for KoP is very challenging. This is because Pulsar does not have a centralized group coordinator for assigning partitions to consumers or managing offsets. The group coordinator has two key responsibilities:
- Rebalance: Assign different partitions to consumers in the same group (subscription)
- Commit offsets: Persist on the latest offset information on a special offset topic
In KoP, the group coordinator logic is rewritten in Java, while it is slightly different from the original implementation in Kafka. KoP introduces a new component called Namespace Bundle Listener. In Kafka, follower nodes notify the leader of ISR change. This is different from Pulsar since Pulsar brokers cannot communicate with each other. Pulsar uses bundles as a sharding mechanism. Topics are assigned to a particular bundle through the hash of the topic name.
Note: This post does not explain bundles in detail. Here, you only need to know that the component monitors the change of bundles so the group coordinator can then assign partitions.
Reads and Writes
For the offset topic, the Pulsar producer and consumer perform the reads and writes directly. For ordinary messages, KoP uses the managed ledger and the managed cursor on the broker for reads and writes.
Managed ledgers provide an additional storage abstraction on top of BookKeeper. A managed ledger manages several Pulsar segments (also known as ledgers in BookKeeper, which are used to store messages on bookies). It contains their size and state information. A managed cursor is a persisted cursor inside a managed ledger. It reads from the managed ledger and signals when the consumer finishes consuming messages.
Keep in mind: KoP uses broker resources to directly read and write messages from and to BookKeeper instead of creating a client. This also reduces an additional network hop.
Offset Implementation
Kafka maintains a numerical offset for records in a partition, which indicates the position of the consumer in the partition. In Pulsar, there is no equivalent concept to the Kafka offset (Pulsar uses cursors to track the consumption and acknowledgment information of subscriptions. Note that cursors work in a more sophisticated way than Kafka offsets).
Early KoP versions handled offsets with a simple conversion method, while it did not allow continuous offsets and could easily lead to problems. To solve this issue, the KoP community introduced a new concept “broker entry metadata” in KoP 2.8.0 to enable continuous offsets. As this is a very complicated topic, I refer you to one of my previous blogs Offset Implementation in Kafka-on-Pulsar to have a comprehensive understanding of offset implementation in KoP.
Get Started With KoP
If you have an Apache Pulsar cluster, you can enable KoP on your existing Pulsar cluster by downloading and installing the KoP protocol handler on Pulsar brokers directly. To get started, perform the following steps:
- Download the nar file on the Releases page, and move it to the
protocolsfolder (create it manually) in the directory that stores your Pulsar package. Alternatively, clone the KoP GitHub repository and build the project locally - In
broker.conforstandalone.conf, configure the following fields:
messagingProtocols=kafka
allowAutoTopicCreationType=partitioned
listeners=PLAINTEXT://127.0.0.1:9092
brokerEntryMetadataInterceptors=\
org.apache.pulsar.common.intercept.AppendlndexMetadatalnterceporStart your Pulsar brokers.
When choosing different versions of KoP, keep in mind that:
- A KoP version has four minor numbers, namely x.y.z.m. The first three numbers refer to the Pulsar version that this KoP version is compatible with (for example, KoP 2.9.1.2 is compatible with Pulsar 2.9.1)
- When a minor Pulsar version is upgraded, the corresponding old version of KoP will not be maintained. For example, after Pulsar 2.9.2 was released, the KoP community did not maintain KoP 2.9.1.m
- Pulsar versions earlier than 2.8 are not recommended
- When you build the KoP project from the source code, do not use the
masterbranch. Use a branch that is specific to the Pulsar version you are using
FAQs About KoP
I have collected some questions from the KoP community and listed my solutions and suggestions here.
How Do I Specify entryFormat?
entryFormat defines the format of KoP entries. Allowed values are pulsar, kafka, and mixed_kafka. It defaults to pulsar, which means Kafka clients can consume messages produced by Pulsar clients and that Pulsar clients can also consume messages produced by Kafka clients. However, the message decoding and encoding process can be time-consuming.
- Kafka-formatted messages need to be decompressed to recreate Pulsar-formatted messages
- Pulsar-formatted messages need to be decompressed to recreate Kafka-formatted messages
For most applications in production, I suggest you configure entryFormat=kafka. In this way, KoP adds a key value to the metadata of a message to indicate that it comes from Kafka clients and then writes it into BookKeeper without unnecessary encoding and decoding. The downside of this method is that Pulsar clients cannot consume messages produced by Kafka clients. As these messages are written to bookies in the original format of Kafka, Pulsar clients cannot recognize them. To address this issue, the community designed a message payload processor for the Pulsar client in KoP 2.9.0. It allows Pulsar consumers to consume messages produced by Kafka producers even if you set entryFormat to kafka. You can configure the processor in your consumer application using messagePayloadProcessor as follows:
final Consumer<byte[]> consumer = client.newConsumer()
.topic("my-topic")
.subscriptionName("my-sub")
.messagePayloadProcessor(new KafkaPayloadProcessor())
.subscribe();To import KafkaPayloadProcessor, you need to add the following dependency. Note that pulsar.version should be the same as the version of your pulsar-client dependency.
<dependency>
<groupId>io.streamnative.pulsar.handlers</groupId>
<artifactId>kafka-payload-processor</artifactId>
<version>${pulsar.version}</version>
</dependency>For more information, see the KoP documentation.
Consumers Couldn’t Keep Up With the Rate of Message Production
A simple solution to this problem is increasing the value of maxreadEntriesNum:
maxreadEntriesNum=5
This property represents the maximum number of entries that are read when KoP processes a FETCH request each time. Increasing this value reduces the number of requests required over the network. However, if it gets too large, it may put additional pressure on the memory. Note that the ManagedCursor currently does not check the byte-based read limit.
Why Couldn’t I See Consumption Statistics When Using Pulsar-Admin?
The community removed topic consumption statistics in KoP 2.8.0 and later versions. If you use pulsar-admin to check the information about a topic, you can’t see any available consumption details. The reasons for the removal are:
- Originally, when KoP committed an offset, it needed to find the message ID of the offset so the message could be acknowledged. This process is too time-consuming
- Kafka manages offset through the group coordinator. However, The coordinator broker may not be the leader broker. In Pulsar, only the topic owner broker can acknowledge messages
KoP now provides a variety of Prometheus-based metrics to display consumption information, which is accessible through Grafana. For more information, see KoP metrics.
Error Message
NOT_LEADER_OR_FOLLOWER
(org.apache.kafka.clients.producer.internals.Sender)
When Pulsar automatically deletes partitioned topics (by default, inactive topics are deleted automatically in Pulsar), it does not delete the partition number metadata, which is stored in ZooKeeper. As a result, when KoP receives a request about the metadata from a client, it can still find the topic. KoP then sends the leader broker information to the client, which leads to the following error.
Error: NOT_LEADER_OR_FOLLOWER (org.apache.kafka.clients.producer.internals.Sender)
To solve this problem, use either of the following ways:
- Disable automatic deletion of inactive topics in
broker.conf:brokerDeleteInactiveTopicsEnabled=false - Enable automatic deletion of the metadata of inactive partitioned topics in
broker.conf. This is the preferred solution if you don’t want to disable topic automatic deletion in production:brokerDeleteInactivePartitionedTopicMetadataEnabled=true
What’s New in KoP?
Support for KoP in the OpenMessaging Benchmark Framework
First, let me briefly explain what the OpenMessaging Benchmark Framework is and the scripts and configurations you need if you want to use it.
The OpenMessaging Benchmark Framework is a suite of tools that make it easy to benchmark distributed messaging systems in the cloud. OpenMessaging benchmarking suites are currently available for systems such as Apache Pulsar, Apache Kafka, Apache RocketMQ, Redis, and Pravega. It provides the following for each supported message system:
- A Terraform script that automatically applies for and creates resources on cloud providers (for example, AWS)
- An Ansible script that automatically installs all necessary components (MQ, monitoring, and benchmark services) on remote machines
- A Java-based driver that allows you to easily run the MQ client. You can customize necessary client configurations in a YAML file
Previously, when you tested the performance of KoP using the OpenMessaging Benchmark Framework, you had to manually change the Pulsar Ansible script by adding KoP-related logic. This is because the script does not deploy the Kafka protocol handler by default. In addition, you must use the Kafka driver and configurations to start Kafka producers and consumers in the test.
To simplify the performance test of KoP using the benchmark, the KoP community created a driver specifically for KoP. It supports Kafka and Pulsar clients. In other words, you can have a mixed combination of Kafka and Pulsar producers and consumers working at the same time. It contains the logic of the payload processor, which allows Pulsar clients to consume Kafka-formatted messages if you set entryFormat to kafka.
This is an example of using the KoP driver:
./bin/benchmark -d driver-kop/kafka_to_pulsar.yaml -o kop.json workloads/1-topic-1-partition-100b.yaml
./bin/benchmark -d driver-kop/kafka_to_kafka.yaml -o kop.json workloads/1-topic-1-partition-100b.yaml
./bin/benchmark -d driver-kop/pulsar_to_kafka.yaml -o kop.json workloads/1-topic-1-partition-100b.yamlFor more information, see the driver-kop directory on the OpenMessaging Benchmark Framework GitHub repository.
Note: The configuration of protocol handlers has also been simplified. Users can easily customize the protocol_handlers variable by specifying the protocol type, configuration file, and download URL. See this pull request and Apache Pulsar benchmarks to know more details.
Automatic Deletion of Inactive Group Information on Znodes
KoP leverages ZooKeeper to store the group information of consumers when it handles the FETCH request from them. The group information stored on znodes can then be used to update consumer metrics. The reason why KoP uses ZooKeeper for this purpose is that you cannot obtain the group information directly in the FETCH request. As shown in the figure below, a consumer sends different requests to the leader broker and the coordinator broker, while these two brokers may not be the same.
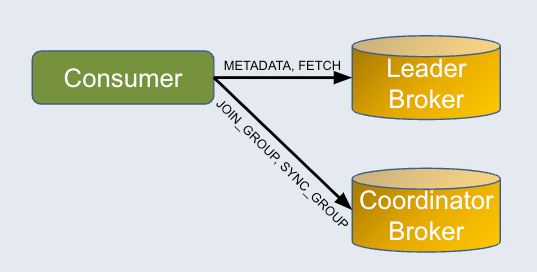
Previously, the group information was never deleted on znodes, which could become extremely large and cause other problems to the KoP cluster. To solve this problem, the community found a way to automatically delete the group information when the group is not active anymore.
In addition to the above improvements, the KoP community has also made some progress in fixing existing bugs and adding some minor features. Take a look at some of them if you are interested.
Bug fixes: PR 1038, PR 973, PR 1125, PR 1230, and PR 1276.
New features: PR 1006 and PR 1125.
What’s Next?
The KoP community looks to improve the project in the following ways.
- Add the Schema Support:
- Confluent Schema Registry API compatibility
- Add the compatible serializer and deserializer so that Kafka clients can interact with the Pulsar schema
- Improve the transactions feature
- Do some research on the OAuth2 plugin for other languages, such as C, C++, Go, and Python
- Finish the performance test report of KoP
If you take a step back and reflect on how far KoP has come, it is not surprising to find that there are an increasing number of users joining the KoP community and making contributions in different ways. Like other tools in the Apache Pulsar ecosystem, KoP could not have come this far without the efforts of every community member involved. If you are interested in KoP, feel free to submit a pull request or open an issue on its GitHub repository.
Opinions expressed by DZone contributors are their own.
Comments