Truth Behind Neo4j’s “Trillion” Relationship Graph
This article discusses why benchmarking is important, as well as compare and contrasts Neo4j’s 100TB demo with TigerGraph.
Join the DZone community and get the full member experience.
Join For FreeMy interest in graph database benchmarks started with my conversation with Peter Boncz (LDBC chair) at SIGMOD 2018. He introduced me to the “choked points” concepts that he used in analyzing the well-known TPC-H relational database benchmark. He also shared with me that he has employed that choked point methodology in designing the graph data management benchmark LDBC Social Network Benchmark (LDBC-SNB). At that point, for simplicity, I had just finished comparing six graph databases using topology-only (vertex/edge without attributes) data sets and relying on the k-hop query and well-known iterative algorithms such as PageRank and Connected Components to do the comparison (which was an industry first, and followed by other graph startups and academia benchmark reports). As I worked with the largest banking, healthcare, retail, and manufacturing enterprises at TigerGraph, I realized that those benchmarks did not meet the real-world requirements for evaluating an enterprise-grade graph database. I was looking for graph benchmarks that are closer to the complex graph query patterns of real-world customer queries. And LDBC-SNB fits the bill!
Ever since then, TigerGraph has adopted the LDBC-SNB as the benchmark suite to evaluate our release performance and we have continued to deliver the world records in scalability using the largest LDBC-SNB data sets (2019 1TB, 2020 5TB).
Recently, Neo4j touted running LDBC-SNB queries at the scale of 100TB (video here starting at 51:48; source code of the demo here). At first, I was excited about it, since our respected competitor seemed to start focusing on scalability and realized the importance of big datasets in real word for graph use cases. However, after reviewing the actual content of the demo, I’m truly disappointed. This so-called 100TB demo is not a fair use of the LDBC-SNB benchmark; it is a pure marketing ploy. That is, this is not a useful demo to the real-world practitioners who are solving real business problems.
This blog will discuss why benchmarking is important and show how Neo4j’s 100TB demo is fake.
A little bit about my background. I am on the ISO GQL standard committee and actively contribute to the GQL graph query language standard. I am writing this blog with my two decades of research (my database Ph.D. program training at the University of Florida) and industry development experience (Microsoft, Oracle, Turn Inc., and TigerGraph) in the database area. I have tried my best to make this technical blog consumable by general readers who are likely to be new to the world of databases.
Summary of Neo4’s recent 100 TB Demo
In a nutshell, Neo4j took the LDBC benchmark name and the graph/table schema in LDBC-SNB benchmark, generated its own simplified dummy dataset which is useless in real life (no real correlation between entities, no realistic edge or relationship degrees), cherry-picked 4 simple queries out of the 14 IC queries of LDBC-SNB (page 32) to claim and create the illusion that Neo4j can scale and answer global queries, neither of which is true.
A distributed and scalable database doesn’t need users to know or care about how many machines or shards the system needs. It should just work transparently.
Neo4j is boasting and excited about the number of shards in its system and how many shards should be for one part of the schema, and how many shards are for the other parts. This mere fact shows that the Neo4j fabric product isn’t a distributed or scalable database. As a database expert, sometimes I admire how Neo4j can turn its architecture's fatal flaw in scalability into a technical feat and be so adamant about it in its product marketing. To see what a truly distributed graph database should have and the comparison to Neo4j’s Fabrics product, see the high-level summary by this article.
In comparison, TigerGraph can do everything Neo4j demonstrated under 100 Machines (instead of 1000+ machines in Neo4j’s demo), transparently to the user in our product, out of box without sharding planning, and even on TigerGraph Cloud! Stay tuned for a separate blog on this.
More details about Neo4j’s demo:
Neo4j’s created its own data generator to generate 100TB data. Generating dummy data is simple. With cheap storage these days, it’s quite simple to generate 100s TBs of data. Neo4j generated data set has neither data skew (uneven data) nor realistic distribution. The official LDBC-SNB data generators are designed to produce connected data (which is what the graph is about) close to the real-world distribution described in a study of the Facebook Social Network. Data used for Neo4j demonstration is simplified for favorable results and does not represent the real-world complexity, the queries are cherry-picked from the benchmark, and the demo misuses the terminology “global query” to create a marketing illusion.
Neo4j’s live demonstration picked a specific query out of 14 LDBC-SNB IC queries. This query touches just a couple of thousands of graph elements (nodes/entities and edges/relationships) out of the trillion graph elements. It’s not deep link analytics at all, it doesn’t prove scalability in any meaningful way.
In contrast, since 2019, TigerGraph has adopted a rigorously benchmarking methodology to implement the LDBC-SNB benchmark at the TB scale. All of our benchmarks employed the following methodology:
Strictly used the LDBC-SNB schema and data generator to generate the raw data.
Implemented all queries in the LDBC-SNB benchmark: no cherry-picking.
Cross validated all the results with other commercial database systems at SF-1 and SF-100 (since no other product can complete all queries at SF-1K scale large data set). All queries and their results are ensured to be correct before we benchmark at the TB scale.
By doing so, we want to give our customers a 360-degree view of our product, and lead by example in the whole graph database industry to show the fair use of the authoritative LDBC graph database benchmark. We invite all graph database vendors to conduct fair use of the benchmark so that the adoption of graph databases will be nurtured in a healthy and objective environment.
Why Benchmark?
When IT professionals plan to purchase a technology product, they need to evaluate multiple competing products and answer the question: "Which product best meets my needs?"
A benchmark evaluates alternative products based on well-defined objective criteria spanning multiple dimensions. It allows one to quantitatively compare different technologies to make more objective choices for their software purchases.
A well-designed graph database benchmark provides a fair 360-degree quantitative comparison of different graph databases from the following perspectives:
Performance: The most fundamental KPI for any database management system is performance. How fast can you answer benchmark queries? What’s your throughput?
Scalability: Another key measurement is scalability. Technology decisions need to consider future growth. So users care about what’s the size limit of the database? Can it handle 1TB, 10TB, 100TB, 1PB and so on? At what scale does the database no longer perform well? This is an important question to ask since architecture limitations cannot be fixed in days or months. It takes years!
Storage Compression Ratio: This links to the TCO (total cost of ownership). One key technical barrier for graph database vendors is how they can compactly represent graphs on disk and memory. Given the same raw data, the smaller the graph storage, the more data it can fit in memory. Thus, the lower the storage access latency and also the lower the hardware cost.
Query Language Expressivity: A well-designed graph database benchmark can reveal the expressivity limitations of a graph database language. This is a unique dimension in evaluating graph databases since graph databases can answer highly complex queries that other database query languages cannot. Experienced database buyers will hesitate to buy a database that cannot implement a complete benchmark at scale.
Mutability: Mutability requires that the database can be updated and queried at the same time. A mutable database is highly desired in real-life scenarios as it allows for queries to run against real-time data.
Which Benchmark?
Five years ago, when I started to lead the benchmark effort at TigerGraph, I used the simple but rigorous method: pick a relationship-rich real data set, fix the hardware, choose the most commonly used graph queries (k-hop, page rank, etc.), perform cross validation, and then test the performance at different scale factors. This method gives the bare metal performance and many other graph database vendors followed our approach, which was the industry first to the best of our knowledge. However, it’s not comprehensive due to time and resource limitations at the time. It cannot systematically find and quantify the weakness of a graph database. The key reason that I aborted this simple method is that it is far from the usage patterns of real-world graph database users.
After Peter introduced me to the LDBC-SNB benchmark, I embraced it into my subsequent benchmarks. Why?
Realistic Data Characteristics: Unlike other data sets, this LDBC-SNB benchmark data set simulates a real-life social forum scenario. The schema contains 11 vertex types, and 15 edge types. It simulates data and edge distributions found in a real social network such as Facebook. And vertices and edges have properties (attributes), which use real data from DBpedia to ensure that attribute values are realistic and correlated.
Representative Graph Queries Covering Different Choke Points: Chokepoints are representative technological bottlenecks underlying a benchmark, whose resolution will significantly improve the performance of a product. LDBC-SNB has three query sets -- Interactive Complex (IC), Interactive Short (IS), and Business Intelligence (BI) -- covering OLTP and OLAP style query patterns. All three query sets include mutation queries.
Query Language Agnostic: Another aspect I like is that each query semantic is described in pure English and illustrated visually by drawings. Any data management vendor can use their DSL (domain-specific language), such as SQL, Cypher, or GSQL, to implement the benchmark queries, yielding the same results. Before the ISO standard GQL comes out in 2023 or beyond, this is golden.
Data generator: The data generator is crucial. It needs to be deterministic, it should generate data having close to real-life characteristics, and it needs to scale to generate large datasets. The LDBC-SNB data generator follows the style of the TPC benchmark, the industry's most reputable and well-known relational database benchmark. It can generate different scale factors (SF): SF-1 (1GB data), SF-10 (10GB data), SF-1k (1TB data) and so on deterministically. Also, for each deterministically generated data set, the data generator can generate the corresponding query parameters, which ensure the benchmark queries can yield non-empty results.
Reputable team with decades of effort behind it. The task force behind it is comprised of reputable database researchers studying and practicing graph data benchmark design for decades. See their list of publications.
Neo4j’s 100TB Demo on LDBC-SNB
With the above background, we are ready to take a look at Neo4’s 100TB demonstration using the LDBC-SNB schema. Note that I did not use the word “benchmark”, since Neo4j skillfully clarified in their demo guide that this demo is not a benchmark.
“The data itself has been generated according to the specifications of the LDBC Social Network Benchmark graph.
This demonstration is not a benchmark, but the benchmark data is perfect for evaluating the impact of the scaling strategies.”
Obviously, Neo4j chose the authoritative benchmark LDBC-SNB for its reputation. And they wanted to show the scalability and performance of their so-called fabric product. Unfortunately, this is not a fair use of the LDBC-SNB benchmark. Why?
The Data Generation Is Overly Simplified
At the time of the demonstration, LDBC-SNB’s official data generator is not able to generate 100TB raw data. Neo4j published their own way to generate the data, which did not follow the original benchmark philosophy. They partitioned the graph into one person shard and 1129 forum shards (the numbers are from their demo video) and then generated the data inside each forum shard independently using the same algorithm and parameters. Since the graph size scales linearly with the number of forum shards, they easily scaled up their data size to 100TB.
Below, I decompose their data generation method and show that the demo query has predictable results with the increases of data sizes.

As Figure 1 shows, the LDBC-SNB schema is partitioned into two main parts--the 1 Person shard and the 1000+ forum shards. The Person shard contains 3B persons with consecutive IDs. Each Forum shard contains all the Person ID references (no attributes) to the Person shard.
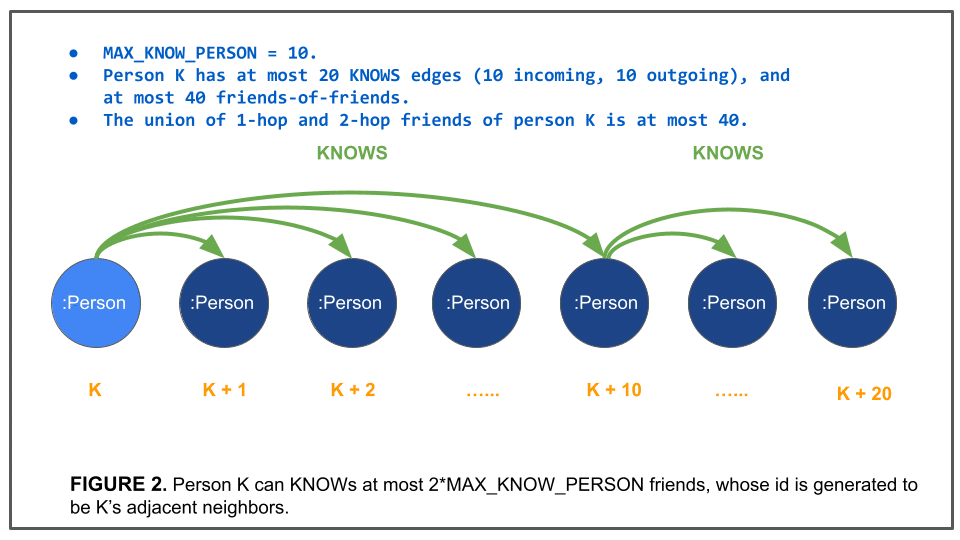
Figure 2 shows how the edge KNOWS connecting two persons are generated. Each person K directly knows at most 20 persons. And these 20 persons’ IDs are consecutive and adjacent to K. As a result, person K knows at most 40 persons (friends and friends-of-friends). This methodology produces a predictable data complexity: the number of friends-of-friends is upper bounded by 40. Person node’s friends are in contiguous ID ranges, leading to better locality. This resulted in better caching (thus better performance) in the demo. In comparison, the number of friends simulated by LDBC-SNB official data generator follows a power-law distribution described in a study of the Facebook Social Network, which will generate 36 friends and 2845 friends of friends on average at scale factor 1 (1GB data). I did an experiment to further verify using the LDBC-SNB official data generator on the BI data set and tallied the average KNOWS edge count per person. For SF-1, each person has an average of 24.45 KNOWS edges; SF-100, 60.91 KNOWS edges; and SF-10K, 137.40 KNOWS edges. So, the average KNOWS edges roughly increase by log10(m), where m is the scale factor. See table below.


Figure 3 depicts the data generation for one forum shard. Each forum shard contains exactly 10,000 forums. Each forum contains 100 ~ 800 posts, which is on average 450 posts per forum. The creator of a post is randomly selected from the person shard. Each post has 0~80 comments, which is equivalent to average 40 comments per post. The 40 comments’ creators are 40 consecutive persons randomly picked from the person shard. The timestamp for each post is current time minus a random 0~100 days, and the timestamp for each comment is current time minus a random 0~10 days. All the random numbers are generated from uniform distributions.
Neo4j’s data generator repeats the same algorithm to generate the 1000+ Forum shards. So, the Forum shards are almost identical and independent, which is not realistic. No data skew and no real correlation between entities are included in this artificial graph.
In contrast, LDBC-SNB’s official data generator produces data in one chunk and does not consider shards at all, which is more realistic.
The Terminology Is Misleading
Neo4j’s demo misuses the terminology of “global query”.
Neo4j CEO claimed “the demo query is a deep, complex graph global query, designed to torture the database”, which is FALSE.
“Global query” in database benchmark refers to the class of queries touching a large portion of the graph (see explanation in LDBC-SNB BI query here). Based on this commonly accepted meaning, let’s calculate the number of touched graph elements of the demoed query.
The demo query IC9 is described in English as:
“Given a start Person, find (the most recent) Messages created by that Person’s friends or friends of friends (excluding start Person). Only consider Messages created before the given maxDate (excluding that day).”
Let’s see how Neo4j ran the IC9 demo.
The demo used the following fixed parameters (excerpt from here) for the IC9 query:
description: "LDBC Read Interactive / complex / 9",
params: {
Date0: new neo4j.types.Date(2022, 1, 14),
Person: neo4j.int(1346680336),
}No update query is incorporated, and the same query is repeatedly executed. The original IC query workload was designed to be transactional, which contains update (insert) queries. Without incorporating updates in the demo and fixing the input parameters enables Neo4j to use cached results, lowering the average runtime with repeated execution. Also, they use a consecutive edge generation method, such that a given person’s friends and friends-of-friends are consecutive, which is cache-friendly. Careful observation of the demo reveals that the query speeds up after the first few executions.
With a fixed person, the query will find at most 40 friends and friends-of-friends of the person (line 2 -7 of the query). Then, the fabric driver will send the 40 persons and a cutoff date “2022/1/14” to all the Forum shards (line 10 -15 of the query). Note that the cutoff date is useless since all posts and comments will be qualified due to the way Neo4j generates the timestamp. Now, let’s calculate how many messages can this query touch in one Forum shard.
What’s the probability that given a person, they will be any creator of a post’s comments? The person will have 40/3B chances. This is based on how the creators of comments are generated. From Figure 3, comments’ creators are generated by randomly picking 40 consecutive persons. Since a person K is included in 40 size-40 consecutive person segments starting from K-40, K-39, etc. respectively. Any randomly selected segment will make person K a creator of the comment group of a post.
Since there are 4,500,000 posts in a Forum shard, on average, given a person, they will be the creator of 4,500,000*(40/3B) = 0.06 comment of a Forum shard. Given 40 consecutive persons (friends, and friends-of-friends), they can be the creator of at least 40*0.06=2.4 comments in a Forum shard.
Since the demo has 1129 Forum shards, so, the IC 9 query with a fixed input person will touch on average 2.4*1129=2709.6 messages. The touched graph elements will be O(2.4*count_of_shards), which is far less than the total graph elements (vertices and edges). Neo4j claimed the demo query is a global query simply because the query touches all the Forum shards. However, their query touches less than 10 graph elements per shard. So, it cannot be called “the query designed to torture the database”.
In fact, the query above is from the Interactive Complex (IC) workload in the LDBC SNB benchmark. The queries in this category only access the neighborhood of a given node. Thus, these queries are local and roughly characterized by runtime O(log n), where n is the number of graph elements. For example, in the audited results of TuGraph, the throughput only decreases by ~10% (from 5436 ops/sec to 4855 ops/sec) when the data generator scale factor increases from 30 to 300. If it were a global query, one would expect with a 10x increase of the data size, he/she will see a 10x decrease of the throughput.
Also, with the LDBC-SNB benchmark data generator, the number of Persons and Messages selected by the IC 9 may cluster at certain forums due to the correlation inside the social network. Neo4j data generator uniformly distributed the touched messages across the forum shards, and the resulting runtime query pattern is unrealistic.
The Demo Query Is Cherry-Picked From LDBC-SNB IC Workload
The demo only used 2 queries (IC9, and recent posts). The original IC suite has 14 queries (see page 33 here). The demo cannot be interpreted as a holistic view of Neo4j's performance. Benchmark queries are designed as a whole suite, covering different choked points. Cherry-picking queries induces an illusion that defeats the purpose of benchmark design.
For example, the BI 11 query below is taken from the LDBC-SNB latest version, which counts all the distinct Person-triangle in a given Country. If this query is implemented on the Neo4j fabric database, the query will only use the person shard CPUs and memory, and the resources on the 1000+ forum shards will be idle.

In fact, this query is expensive and the size of the result is O(n^1.5) complexity, where n is the person count in this case. If one distributes the Person nodes to different shards and runs join algorithms with all the available computing power on the cluster, the performance would be much faster (due to more computing resources) than putting all persons on a single machine (shard). Cherry-picking benchmark queries will shield the audience from seeing this problem on Neo4j’s demo setup. Recent advances in database theory can optimally solve this problem in terms of worst-case data complexity by “Worst-case Optimal Join Algorithms”.
Conclusion
Neo4j’s recent 100TB demo is not a fair use of the LDBC-SNB benchmark. The data is highly artificial and not realistic, the queries are cherry-picked from the benchmark, and the demo misuses the terminology “global query” to create a marketing illusion.
In contrast, since 2019, TigerGraph has adopted a rigorously benchmarking methodology to implement the LDBC-SNB benchmark at TB scales. All of our benchmarks employed the following principles:
Strictly used the LDBC-SNB schema and data generator to generate the raw data.
Implemented all queries in the LDBC-SNB benchmark: No cherry-picking.
Cross validated all the results with other commercial database systems at SF-1 and SF-100. All queries and their results are ensured to be correct before we benchmark at the TB scale.
By doing so, we want to give our customers a 360-degree view of our product, and lead by example in the whole graph database industry to show the fair use of the authoritative graph database benchmark. We invite all graph database vendors to conduct fair use of the benchmark so that the adoption of graph databases will be nurtured in a healthy and objective environment.
Vigorous debate is the foundation of honest communication. I invite all database practitioners to engage with team TigerGraph in a conversation about the merits of an objective benchmark. I also invite all readers to read the buyer’s guide for graph databases for an evaluation of leading graph databases including Neo4j, Amazon Neptune, DataStax, and TigerGraph.
Published at DZone with permission of Mingxi Wu, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments