Tracking the Worst Sci-Fi Movies With Angular and Slash GraphQL
A Slash GraphQL service instance contains everything needed to provide data to an Angular app. Let’s make a fun demonstration using some of the worst movies of all time!
Join the DZone community and get the full member experience.
Join For FreeI originally discovered Mystery Science Theater 3000 (MST3K) by mistake.
In order to avoid missing a movie premiere on the HBO network, I set my VCR to record the program. However, when I started to watch the recording, I quickly realized I had recorded "Mystery Science Theater 3000: The Movie" instead of the HBO premiere production. After recognizing the images of Mike Nelson and the two robots from years of scanning channels, I decided to give my mistaken recording a try.
After five minutes of watching the critiqued version of "This Island Earth," I knew I was hooked. I was already in tears from gut-busting laughter. These guys were comic geniuses.
For those who have no idea what I am talking about, MST3K was an American television comedy series that ultimately ran for 12 seasons. At the heart of the series is a lead character who gets captured by an evil villain and shot into space, then forced to watch really bad movies. Along the way, the main character builds a couple robots to keep him company while watching these bad films. Their silhouettes can be seen in the corner of the screen as the subpar movies unfold. Their quite-comical observations poke fun of the production and make the series a lot of fun to watch.
Since I was still interested in doing more with Slash GraphQL, I thought it would be really cool for us to create a modern-day MST3K wish list. You know, in case the series were to be picked up again.
Selecting Dgraph's Slash GraphQL
A graph database is an ideal solution when the source data handles recommendation and personalization needs. Such functional requirements often place the value of data relationships on the same level as the attributes which are being persisted. In this example, the use of ratings for a given movie title is just as important as the title attributes which will be analyzed and presented, making a graph database the preferred approach.
Since September, Dgraph has offered a fully managed backend service, called Slash GraphQL. Along with a hosted graph database instance, there is also a RESTful interface. This functionality, combined with 10,000 free credits for API use, allows us to rely fully on the Dgraph services. That way, we don’t have to introduce another layer of services between the graph database and web-based client.
Our technology stack will be quite simple, but effective:
- Dgraph Slash GraphQL to house the data
- Dgraph Slash GraphQL to provide a GraphQL API for accessing the data
- Angular CLI to create an application for presenting the data
With service/storage choice set on using Slash GraphQL, our next step is to figure out how to get data for the project.
Getting Data From IMDb
Internet Movie Database (IMDb) has been my primary source of film data for the better part of twenty years. In addition to the details of any movie, there is a crowd-sourced five-star rating system available for each title. At a glance, the consumer can see both the average rating and the number of votes used to reach the current score. These data points will be perfect for our new application.
For the modern-day MST3K wish list, we’ll use the following criteria to build our list of bad sci-fi movies for consideration:
genre must include "Sci-Fi"
limited to movie types (exclude shorts, made-for-TV movies, series, etc.)
excludes titles with fewer than 500 ratings
We will focus on the bottom 125 of movies ranked by imdb.com.
IMDb Datasets
IMDb Datasets make subsets of IMDb data available to customers for personal and non-commercial use. On a periodic basis, a series of TSV files are available for download. Upon reviewing the list of files, two of those seem to fit our needs:
title.basics.tsv.gz— contains basic information for IMDb titlestitle.ratings.tsv.gz— contains the ratings and votes for IMDB titles
As one might imagine, these files are quite large — especially when extracted. We need a mechanism to filter these data source files.
Filtering the TSV Files Using Java
Using IntelliJ IDEA, I created a simple class which would accomplish the following steps:
- read each line of the
title.basics.tsvfile - determine if the line contains the "Sci-Fi" genre
- if so, capture the title ID attribute as the key to a
Map<String, String>and place the entire line as the value of the map - if any match is found, process the
title.ratings.tsvfile: - read each line of the ratings file and capture the title ID
- if the title ID attribute exists in the
Map<String, String>, add the rating and votes data to the value of the map entry - create a new TSV file which contains the Sci-Fi title information, plus the average user rating and number of votes
Below is the very simple entry point into the Java program:
public class Application {
private static final String DEFAULT_GENRE = "Sci-Fi";
private static final String USER_HOME = "user.home";
private static final String DELIMITER = "\t";
private static final String TITLE_BASICS_TSV_FILE_LOCATION = "/downloads/title.basics.tsv";
private static final String TITLE_RATINGS_FILE_LOCATION = "/downloads/title.ratings.tsv";
private static final String DESTINATION_FILE = "/downloads/filtered.tsv";
public static void main(String[] args) throws IOException {
String genre = DEFAULT_GENRE;
if (args != null && args.length > 0) {
genre = args[0];
}
Collection<String> data = filterData(TITLE_BASICS_TSV_FILE_LOCATION, genre);
if (CollectionUtils.isNotEmpty(data)) {
writeFile(data, DESTINATION_FILE);
}
}
...
}
The main filtering code is shown below:
xxxxxxxxxx
private static Collection<String> filterData(String fileName, String genre) throws IOException {
Map<String, String> data = new HashMap<>();
try (BufferedReader br = new BufferedReader(new FileReader(System.getProperty(USER_HOME) + fileName))) {
String string;
long lineNumber = 0;
while ((string = br.readLine()) != null) {
if (lineNumber > 0 && StringUtils.contains(string, genre)) {
String firstItem = StringUtils.substringBefore(string, DELIMITER);
data.put(firstItem, string);
}
logResults(lineNumber, fileName);
lineNumber++;
}
if (MapUtils.isNotEmpty(data)) {
appendUserRatings(data, TITLE_RATINGS_FILE_LOCATION);
}
}
return data.values();
}
The code to process the average rating and total votes TSV file is shown below:
xxxxxxxxxx
private static void appendUserRatings(Map<String, String> data, String fileName) throws IOException {
try (BufferedReader br = new BufferedReader(new FileReader(System.getProperty(USER_HOME) + fileName))) {
String string;
long lineNumber = 0;
while ((string = br.readLine()) != null) {
if (lineNumber > 0) {
String firstItem = StringUtils.substringBefore(string, DELIMITER);
if (data.containsKey(firstItem)) {
data.put(firstItem, data.get(firstItem) + DELIMITER + StringUtils.substringAfter(string, DELIMITER));
}
}
logResults(lineNumber, fileName);
lineNumber++;
}
}
}
Finally, the following helper methods were added:
xxxxxxxxxx
private static void writeFile(Collection<String> data, String fileName) throws IOException {
try (BufferedWriter bw = new BufferedWriter(new FileWriter(System.getProperty(USER_HOME) + fileName))) {
for (String str : data) {
bw.write(str);
bw.newLine();
}
}
}
private static void logResults(long lineNumber, String fileName) {
if (lineNumber % 10000 == 0) {
System.out.println("Completed " + lineNumber + " " + fileName + " records");
}
}
Locating the Bottom 125
With a filtered.tsv file now ready, we can use Microsoft Excel to narrow the data down to a manageable size of the 125 worst-rated Sci-Fi movies. Based on the Java program’s results, here are our columns:
- id
- titleType
- primaryTitle
- originalTitle
- isAdult
- startYear
- endYear
- runtimeMinutes
- genres
- averageRating
- numVotes
The following actions were taken in Microsoft Excel:
- only "movie" value for the titleType column
- remove any values where isAdult is greater than zero
- only items which have a value greater than or equal to 500 in the numVotes column
We can now sort the list by the averageRating column, where the lowest rating is at the top of the list.
Next, copy the top 125 records and drop this data into another sheet. Let’s also remove all but the following columns:
- id
- primaryTitle (which will become title)
- startYear (which will become releaseYear)
- runtimeMinutes
- genres (which will become genre)
- averageRating
- numVotes (which will become votes)
To prepare for use by Dgraph Slash GraphQL, use the CONCAT function in Microsoft Excel to create a new column for each row of data which presents the data in the following JSON format:
xxxxxxxxxx
{id:"tt5311054", title:"Browncoats: Independence War", releaseYear:2015,runtimeMinutes:98,genre:"Action,Sci-Fi,War",averageRating:1.1,votes:717},
At this point, the source data is ready for use by Dgraph Slash GraphQL.
Using Slash GraphQL
In the "Building an Amazon-Like Recommendation Engine Using Slash GraphQL" article, I walk through the necessary steps to create a free Dgraph Slash GraphQL account, which provides 10,000 free credits. Getting started is as simple as navigating to the following URL:
Since I still have a significant number of credits available for my account, I decided to create a new backend service called bad-scifi-movies to house the data extracted from IMDb. This action provided me with a GraphQL Endpoint value in the Overview section of the Dgraph user interface, which will be referenced in the Angular client setup.
Next, the schema for the new backend service needs to be created. We’ll keep things simple— the Slash GraphQL schema is noted below:
xxxxxxxxxx
type Movie {
id: String! @id @search(by: [hash])
title: String! @search(by: [fulltext])
releaseYear: Int! @search
runtimeMinutes: Int!
genre: String! @search(by: [fulltext])
averageRating: Float! @search
votes: Int! @search
seen: User
}
type User {
username: String! @id @search(by: [hash])
movies: [Movie] @hasInverse(field: seen)
}
The Movie object will house all of the data filtered from IMDb. For the sample application, the User object will contain a unique username and a list of really bad sci-fi movies seen by that user.
With the schema created, it is time to insert data into Dgraph Slash GraphQL. To insert the Movie data, that JSON-based column in Microsoft Excel needs to be copied.
Below, is an abbreviated example of the insert command:
xxxxxxxxxx
mutation AddMovies {
addMovie(input: [
{id:"tt5311054", title:"Browncoats: Independence War", releaseYear:2015,runtimeMinutes:98,genre:"Action,Sci-Fi,War",averageRating:1.1,votes:717},
{id:"tt2205589", title:"Rise of the Black Bat", releaseYear:2012,runtimeMinutes:80,genre:"Action,Sci-Fi",averageRating:1.2,votes:690},
{id:"tt1854506", title:"Aliens vs. Avatars", releaseYear:2011,runtimeMinutes:80,genre:"Horror,Sci-Fi",averageRating:1.5,votes:1584},
more JSON data here
{id:"tt0068313", title:"Brain of Blood", releaseYear:1971,runtimeMinutes:87,genre:"Horror,Sci-Fi",averageRating:2.9,votes:727},
{id:"tt1754438", title:"Robotropolis", releaseYear:2011,runtimeMinutes:85,genre:"Action,Adventure,Sci-Fi",averageRating:2.9,votes:1180}
])
}
Please note: at the end of this article, there will be a link to the GitLab repository, which includes the full list of 125 movies.
For the purposes of this example, we’ll utilize a single User object:
xxxxxxxxxx
mutation AddUser {
addUser(input:
[
{
username: "johnjvester",
movies: [
{id: "tt0052286"},
{id: "tt0077834"},
{id: "tt0145529"},
{id: "tt0053464"},
{id: "tt0060074"},
{id: "tt0075343"},
{id: "tt0089280"},
{id: "tt0059464"},
{id: "tt0055562"}
]
}
]) {
numUids
}
}
Once all of the Movie objects have been inserted, the johnjvester User has watched a total of 9 of the 125 really bad sci-fi movies.
At this point, the new backend service is available for use at the GraphQL Endpoint noted in the Overview section of the Dgraph interface.
Adding the Movie Poster
Showing only the raw data for these movies would be okay, but when the application’s user switches from the list-view to the detail-view, we want them to see the movie poster for the title. However, the IMDb extractions do not provide this information.
Using Google, I was able to locate the open-movie database (OMDb) API, which just happens to contain a link to the movie poster. Additionally, the OMDb API allows for items to be queried using the same unique key which is used by IMDB. However, an API key would be required.
In order to show the movie poster in the Angular application, a free OMDb API key is required:
- Visit http://www.omdbapi.com/apikey.aspx to request an API key.
- Select the FREE option and provide an email address.
- Single-click the Submit button and follow any required follow-up steps.
- Note the “Here is your key” value provided via email from The OMDb API.
Now, when combined with the source data from IMDb, adding the movie poster image is a small API request, which Angular can certainly perform without much effort. In reviewing the Slash GraphQL documentation, I later learned the API call to retrieve the movie poster could have been added to the Slash GraphQL schema using the @custom directive - making it included in the GraphQL query.
Creating the Angular Application
The Angular CLI is very easy to use. Our sample application will use the base component to serve as the view into the Slash GraphQL data. As one might imagine, this data would be presented in a table format. When the user clicks on a row in the table, a basic modal will be displayed, showing the full details for the title (including the movie poster) via the integration with the OMDb API.
Interacting directly with Dgraph Slash GraphQL is handled by a service called graph-ql.service.ts:
xxxxxxxxxx
@Injectable({
providedIn: 'root'
})
export class GraphQLService {
allMovies:string = '{queryMovie(filter: {}) {votes, title, runtimeMinutes, releaseYear, id, genre, averageRating}}';
singleUserPrefix:string = '{getUser(username:"';
singleUserSuffix:string = '"){username,movies{title,id}}}';
constructor(private http: HttpClient) { }
baseUrl: string = environment.api;
getMovies() {
return this.http.get<QueryMovieResponse>(this.baseUrl + '?query=' + this.allMovies).pipe(
tap(),
catchError(err => { return ErrorUtils.errorHandler(err)
}));
}
getUser(username:string) {
return this.http.get<GetUserResponse>(this.baseUrl + '?query=' + this.singleUserPrefix + username + this.singleUserSuffix).pipe(
tap(),
catchError(err => { return ErrorUtils.errorHandler(err)
}));
}
}
The communication to the OMDb API utilizes the omdb.service.ts:
xxxxxxxxxx
@Injectable({
providedIn: 'root'
})
export class OmdbService {
constructor(private http: HttpClient) {
baseUrl: string = environment.omdbApi + environment.omdbKey;
getMoviePoster(id:string) {
return this.http.get<any>(this.baseUrl + '&i=' + id).pipe(
tap(),
catchError(err => { return ErrorUtils.errorHandler(err)
}));
}
}
The Angular environment.ts file includes a few custom attributes as shown below:
xxxxxxxxxx
export const environment = {
production: false,
api: 'https://some-host-instance.us-west-2.aws.cloud.dgraph.io/graphql',
omdbApi: 'http://www.omdbapi.com/?apikey=',
omdbKey: 'omdbApiKeyGoesHere'
};
The API value should be replaced with the GraphQL Endpoint value for the backend service with Dgraph Slash GraphQL. The omdbKey is the unique value received via email from "The OMDb API."
When launching the Angular application, the following OnInit method is executed:
xxxxxxxxxx
ngOnInit() {
this.graphQlService.getMovies()
.subscribe(data => {
if (data) {
let queryMovieResponse: QueryMovieResponse = data;
this.movies = queryMovieResponse.data.queryMovie;
this.movies.sort((a, b) => (a.title > b.title) ? 1 : -1)
}
}, (error) => {
console.error('error', error);
}).add(() => {
});
}
The GraphQlService is used to make a GraphQL API call to Slash GraphQL. That call, which eliminates the need to massage data in the Angular application, retrieves the list of 125 really bad sci-fi movies. The list is then sorted by title, by default.
When users click a movie, a modal opens and the following OnInit is executed:
xxxxxxxxxx
ngOnInit() {
if (this.movie && this.movie.id) {
this.omdbService.getMoviePoster(this.movie.id)
.subscribe(data => {
if (data && data.Poster) {
this.posterUrl = data.Poster;
this.graphQlService.getUser(this.username)
.subscribe(getUserResponse => {
if (getUserResponse && getUserResponse.data && getUserResponse.data.getUser) {
this.user = getUserResponse.data.getUser;
this.hasSeenThisMovie();
}
}, (error) => {
console.error('error', error);
}).add(() => {
});
}
}, (error) => {
console.error('error', error);
}).add(() => {
});
}
}
The OmdbService is used to retrieve the URL for the movie poster and the GraphQLService retrieves the list of movies for the user. The user data determines the value of the hasSeenThisMovie boolean attribute. The simple boolean will determine if the Mark as Watched button in the template will be active or inactive.
To make things appear a little nicer, try including the following packages in the Angular project:
@ng-bootstrap/ng-bootstrap: ^5.3.1angular-star-rating: ^4.0.0-beta.3bootstrap: ^4.5.2css-star-rating: ^1.2.4
Running npm ci (or npm install) made sure all the Node modules were installed. Now we can start the Angular application, using the ng serve command.
Using the Angular Application
With the Angular application running and the Slash GraphQL running, the following screen should be displayed:
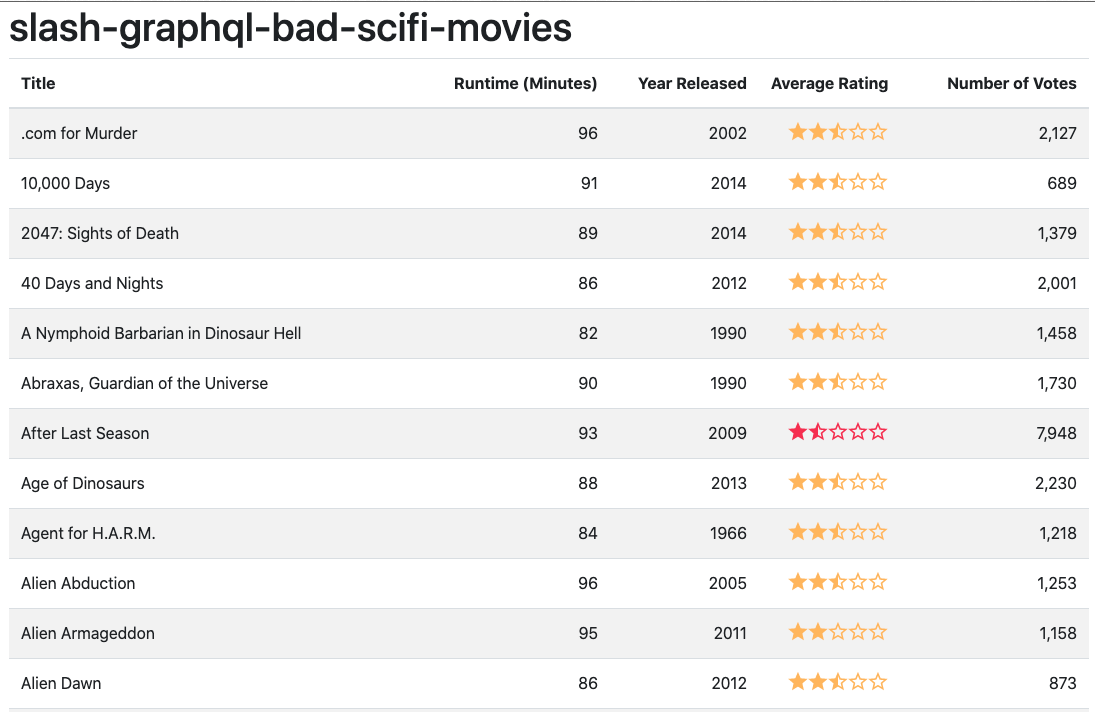
Single-clicking an item on the list for a movie not seen by the johnjvester user appears as shown below:
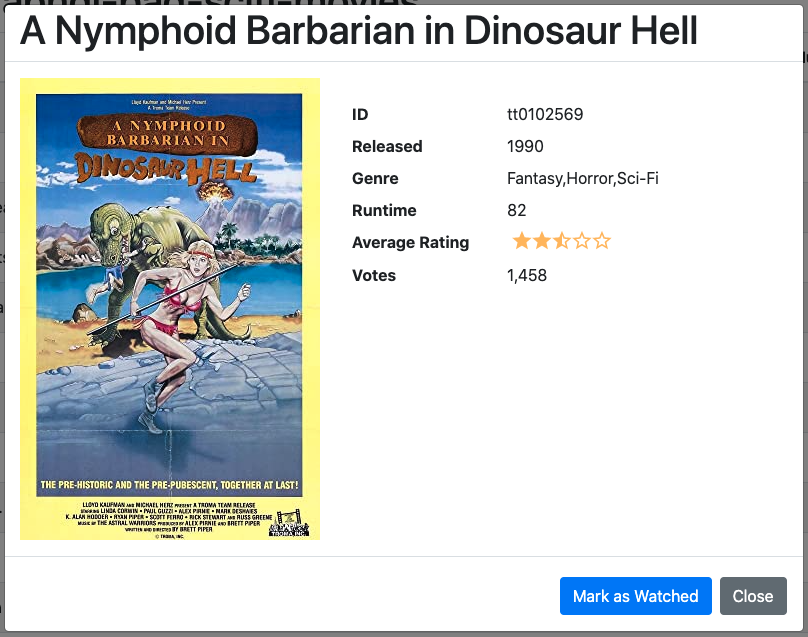
Notice the Mark as Watched button is active.
Single-clicking an item on the list for a movie in which johnjvester has watched appears as shown below:
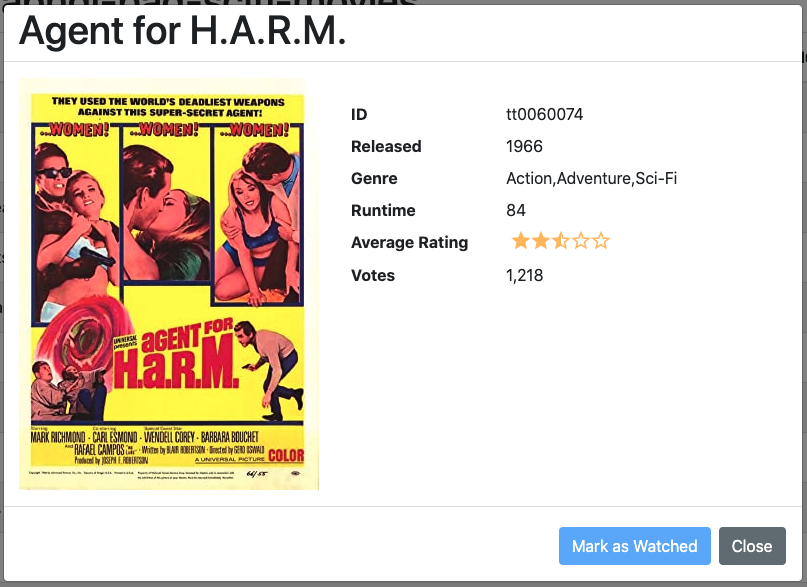
Notice the Mark as Watched button is inactive, since this movie has already been seen.
Conclusion
In the example above, we created a fully functional application using an instance of Dgraph Slash GraphQL and the Angular CLI. While the example provided here was on the simple side, the GraphQL features made available by Slash GraphQL allow for diverse and complex graph-database operations. This approach abstracted the design to not require use of any GraphQL libraries, resulting in a really nice GraphQL database backend from the Slash service that can be treated just like any other API. However, if additional needs are required which fall into the graph database realm (as found in my “Connecting Angular to the Spring Boot and Slash GraphQL Recommendations Engine” article), Slash GraphQL is ready to assist with meeting any functional needs.
This article has demonstrated that it is possible to leverage Slash GraphQL as both a data source and a service layer with your application. This could translate to impressive cost savings over the life of an application. When including the @custom directive, the Angular client no longer has to make a second call for the movie poster, which is handled and included in the payload provided by Slash GraphQL. In fact, the design of the application becomes simplified with the API key moving from Angular into the Slash GraphQL instance - which is a lot easier to secure from anyone with source control access.
If you are interested in the full source code for the Angular application, including the Java code referenced above, please visit the following repository on GitLab:
https://gitlab.com/johnjvester/slash-graphql-bad-scifi-movies
Current pricing for Slash GraphQL makes use of the service very attractive, at $9.99/month for 5GB of data transfer. No hidden costs. No costs for data storage. No cost per query.
Have a really great day!
Published at DZone with permission of John Vester, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments