Top Performance Metrics to Monitor on MySQL (Connections and Buffer Pool Usage)
Learn what performance metric to focus on when monitoring database connections and buffer pool metrics in your MySQL databases.
Join the DZone community and get the full member experience.
Join For FreeAs a DBA, your top priority is to keep your databases and dependent applications running smoothly at all times. To this end, your best weapon is judicious monitoring of key performance metrics. In a perfect world, you’d want to be up-to-date regarding every aspect of your database’s activity – i.e. how many events occurred, how big they were, precisely when they happened and how long they took.
There certainly is no shortage of tools that can monitor resource consumption, provide instantaneous status snapshots, and generate wait analysis and graphs. The challenge is that some metrics can be expensive to measure, and, perhaps even more importantly, they can require a lot of work to analyze.
The purpose of Part-2 of the blog series is to narrow down the field to those performance metrics that provide the most value for the effort as well as present some tangible ways to capture and study them. It is by tracking the most useful metrics and reviewing them in the most informative way(s) that you will strike a balance between paranoid over-monitoring and firefighting unforeseen crises.
This topic is divided into 2 parts. In part 1, we:
- Examined the benefits of performance monitoring,
- Outlined the main performance metric categories,
- Listed the monitoring tools provided by MySQL, i.e.:
- server variables
- The Performance Schema
- The sys Schema
- Learned how to monitor:
- Transaction throughput
- Query execution performance
This blog will focus on monitoring Database Connections and Buffer Pool metrics.
Connections
Connection manager threads handle client connection requests on the network interfaces that the server listens to. On all platforms, one manager thread handles TCP/IP connection requests. Connection manager threads associate each client connection with a thread dedicated to it that handles authentication and request processing for that connection. Manager threads create a new thread when necessary but try to avoid doing so by consulting the thread cache first to see whether it contains a thread that can be used for the connection. When a connection ends, its thread is returned to the thread cache if the cache is not full. In this connection thread model, there are as many threads as there are clients currently connected.
It’s important to monitor your client connections because, once the database server runs out of available connections, new client connections are refused!
The MySQL connection limit defaults to 151, but it can be changed using the SET statement, so it’s best to not assume anything. The connection limit is stored in the @@max_connections variable:
SELECT @@max_connections;
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 151 |
+-----------------+-------+
The connection limit can be set at any time, like so:
SET GLOBAL max_connections = 200;
To permanently set the connection limit, so that it persists once the server is restarted, add a line like this to your my.cnf configuration file:
max_connections = 200
Don’t be afraid to increase the number of max_connections significantly. According to the MySQL docs, production servers should be able to handle connections in the high hundreds or thousands! Just bear in mind that there are some caveats when the server must handle a large number of connections. For instance, thread creation and disposal become expensive when there are a lot of them. In addition, each thread requires server and kernel resources, such as stack space. Therefore, in order to accommodate many simultaneous connections, the stack size per thread must be kept small. This can lead to a situation where the stack size is either too small or the server consumes large amounts of memory.
The takeaway here is that your database server should have adequate amounts of processing power and memory to accommodate a large user base.
MySQL provides a few good metrics for monitoring your connections:
| Variable | What it represents | Why you should monitor it |
| Threads_connected | This variable indicates the total number of clients that have currently open connections to the server. | It provides real-time information on how many clients are currently connected to the server. This can help in traffic analysis or in deciding the best time for a server re-start. |
| Threads_running | The number of threads that are not sleeping. | It’s good for isolating which connected threads are actively processing queries at any given time, as opposed to connections that are open but are currently idle. |
| Connections | The number of connection attempts (successful or not) to the MySQL server. | It can give you a good idea of how many people and applications are accessing the database. Over time, these numbers reveal busiest times and average usage numbers. |
| Connection_errors_internal | The number of connections refused due to internal server errors, such as failure to start a new thread or an out-of-memory condition. | Although MySQL exposes several metrics on connection errors, Connection_errors_internal is probably the most useful, because it is incremented only when the error comes from the server itself. Internal errors can indicate an out-of-memory condition or an inability to start a new thread. |
We can use the MySQL show status command to show MySQL variables and status information. Here are a few examples:
SHOW GLOBAL STATUS LIKE '%Threads_connected%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_connected | 2 |
+-------------------+-------+
SHOW GLOBAL STATUS LIKE '%Threads_running%';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| Threads_running | 1 |
+-----------------+-------+
SHOW GLOBAL STATUS LIKE 'Connections';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Connections | 20 |
+---------------+-------+
Aborted Client and Connections
Every time a client is unable to connect, the server increments the Aborted_connects status variable. Unsuccessful connection attempts can occur for the following reasons:
- A client attempts to access a database but has no privileges for it.
- A client uses an incorrect password.
- A connection packet does not contain the right information.
- It takes more than connect_timeout seconds to obtain a connect packet.
If these kinds of things happen, it might indicate that someone is trying to break into your server! If the general query log is enabled, messages for these types of problems are logged to it.
If a client successfully connects but later disconnects improperly or is terminated, the server increments the Aborted_clients status variable, and logs an Aborted connection message to the error log.
Here’s how to view the number of aborted clients and connections:
mysql> SHOW GLOBAL STATUS LIKE 'Aborted_c%';
+-----------------------------------+------------+
| Variable_name | Value |
+-----------------------------------+------------+
| Aborted_clients | 3 |
| Aborted_connects | 8 |
+-----------------------------------+------------+
Connections Errors
MySQL does an outstanding job of breaking down metrics on connection errors into different status variables:
SHOW GLOBAL STATUS LIKE 'Connection_errors%';
+-----------------------------------+-------+
| Variable_name | Value |
+-----------------------------------+-------+
| Connection_errors_accept | 0 |
+-----------------------------------+-------+
| Connection_errors_internal | 0 |
+-----------------------------------+-------+
| Connection_errors_max_connection | 0 |
+-----------------------------------+-------+
| Connection_errors_peer_address | 0 |
+-----------------------------------+-------+
| Connection_errors_select | 0 |
+-----------------------------------+-------+
| Connection_errors_tcpwrap | 0 |
+-----------------------------------+-------+
Once all available connections are in use, attempting to connect to MySQL will cause it to return a “Too many connections” error and increment the Connection_errors_max_connectionsvariable. Your best bet in preventing this scenario is to monitor the number of open connections and make sure that it remains safely below the configured max_connections limit.
Fine-grained connection metrics such as Connection_errors_max_connections and Connection_errors_internal can be instrumental in pinpointing the source of the problem. The following statement fetches the value of Connection_errors_internal:
SHOW GLOBAL STATUS LIKE 'Connection_errors_internal';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Connection_errors_internal | 2 |
+----------------------------+-------+
Here are a couple of Monyog screens that monitor Current Connections and the Connection History, respectively:
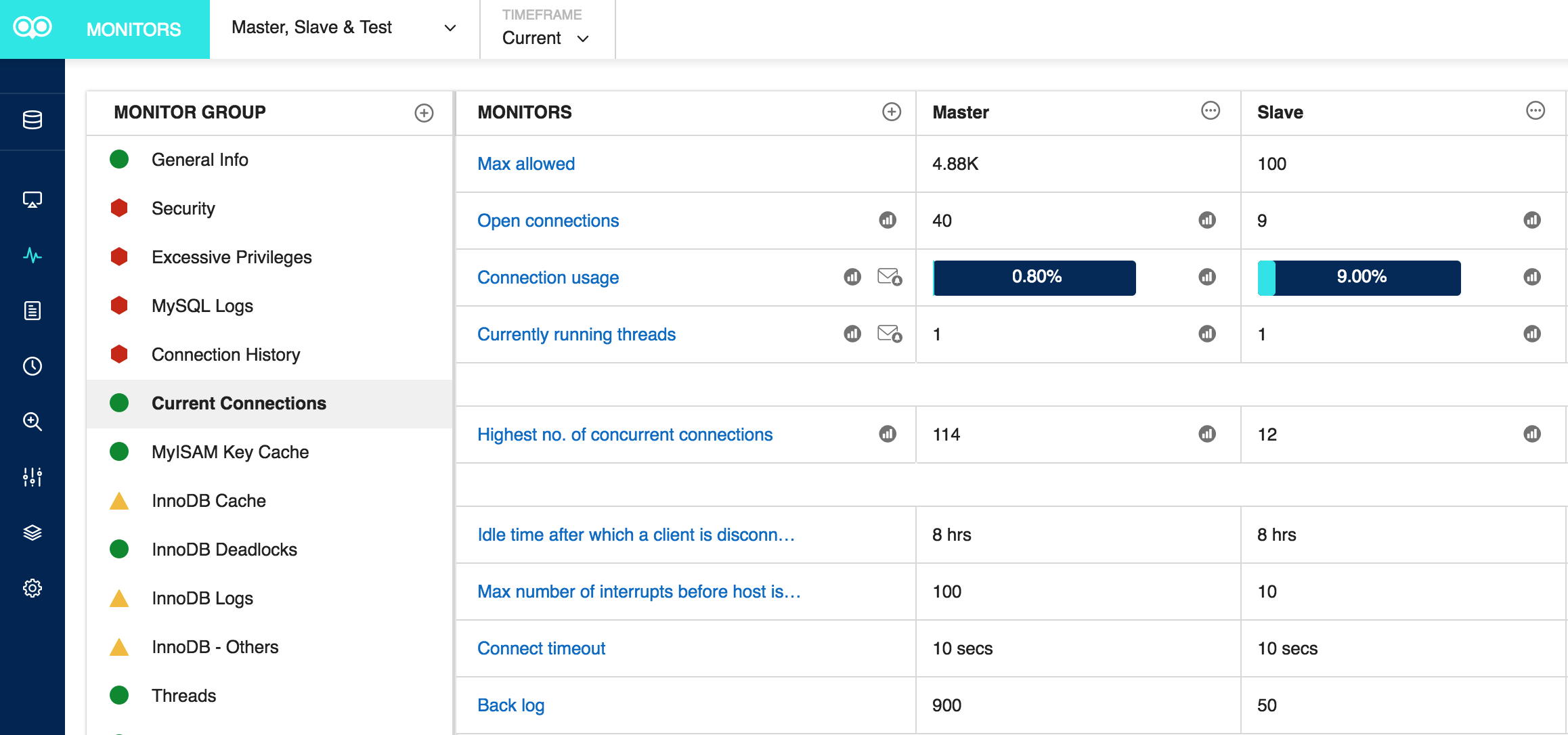
Monyog monitor – current connection
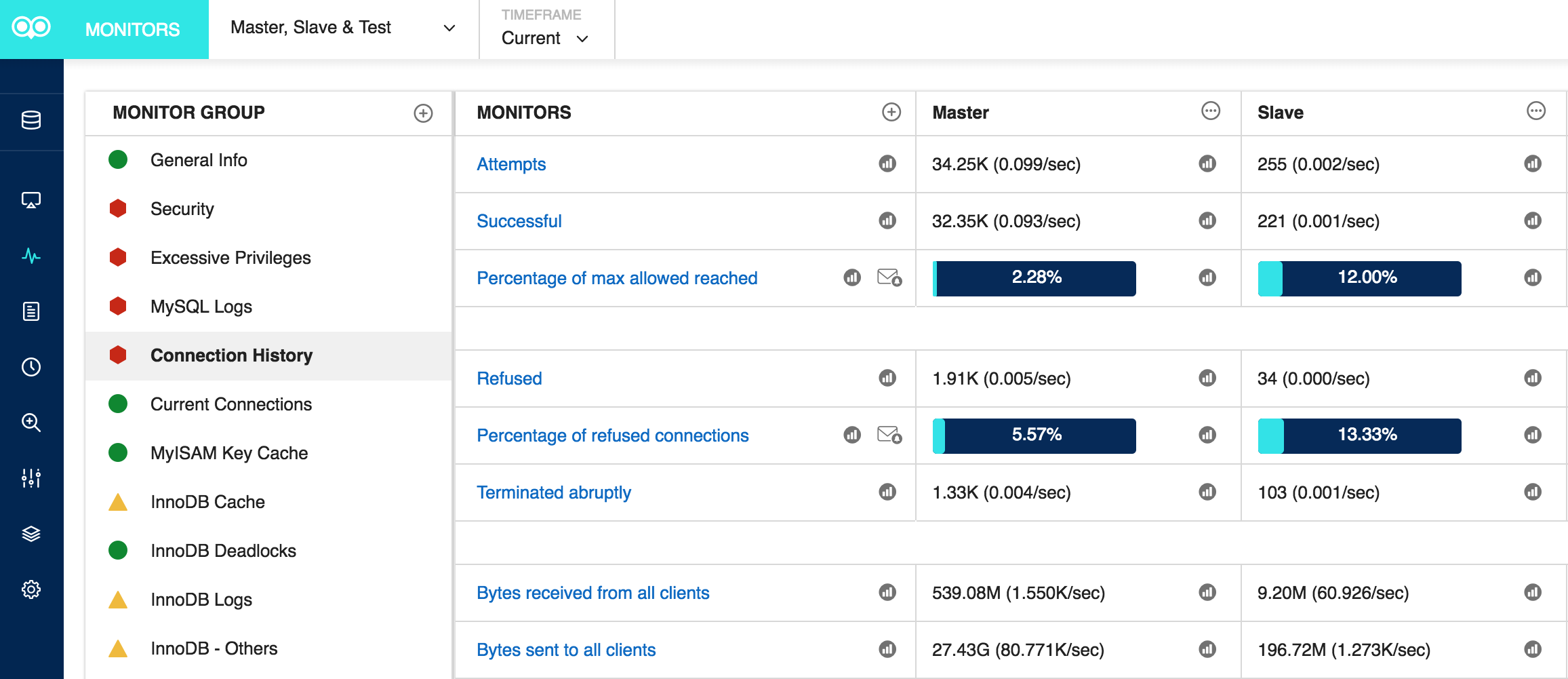
Monyog monitor – Connection History
Buffer Pool Usage
MySQL’s default storage engine, InnoDB, uses a special storage area called the buffer pool to cache data for tables and indexes. Buffer pool metrics are categorized as resource metrics. As such, their main value is in the investigation, rather than the detection, of performance issues.
Configuring the Buffer Pool
You can configure various aspects of the InnoDB buffer pool to improve performance.
The buffer pool defaults to a relatively small 128MB. Ideally, you should increase the size of the buffer pool to as large a value as is practical, while leaving enough memory for other processes on the server to run without excessive paging. That typically amounts to about 80 percent of physical memory on a dedicated database server. The idea is that, the larger the buffer pool, the more InnoDB acts like an in-memory database, reading data from disk once and then accessing the data from memory during subsequent reads.
Please note:
- InnoDB’s memory overhead can increase the memory footprint by about 10 percent beyond the allotted buffer pool size.
- Once physical memory is exhausted, your system will resort to paging and performance will suffer significantly. Hence, if database performance starts to degrade while disk I/O is rising, it might be time to expand the buffer pool.
Buffer-pool resizing operations are performed in chunks, and the size of the buffer pool must be set to a multiple of the chunk size times the number of instances:
innodb_buffer_pool_size = N * innodb_buffer_pool_chunk_size
* innodb_buffer_pool_instancesThe chunk size defaults to 128MB but is configurable as of MySQL 5.7.5. The value of both parameters can be checked as follows:
SHOW GLOBAL VARIABLES LIKE "innodb_buffer_pool_chunk_size";
SHOW GLOBAL VARIABLES LIKE "innodb_buffer_pool_instances";
If querying the innodb_buffer_pool_chunk_size returns no results, the parameter is not tunable in your version of MySQL and can be assumed to be 128MB.
To set the buffer pool size and number of instances at server startup, invoke mysqld.exe with the following parameters:
$ mysqld --innodb_buffer_pool_size=8G --innodb_buffer_pool_instances=16
As of MySQL 5.7.5, you can also resize the buffer pool on-the-fly via a SET command specifying the desired size in bytes. For instance, with two buffer pool instances, you could set each to 4GB by setting the total size to 8GB:
SET GLOBAL innodb_buffer_pool_size=8589934592;
Important InnoDB Buffer Pool Metrics
InnoDB Standard Monitor output, which can be accessed using “SHOW ENGINE INNODB STATUS”, provides a number of metrics pertaining to operations of the InnoDB buffer pool, under the BUFFER POOL AND MEMORY section. Here is some typical content:
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 2198863872
Dictionary memory allocated 776332
Buffer pool size 131072
Free buffers 124908
Database pages 5720
Old database pages 2071
Modified db pages 910
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 4, not young 0
0.10 youngs/s, 0.00 non-youngs/s
Pages read 197, created 5523, written 5060
0.00 reads/s, 190.89 creates/s, 244.94 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 5720, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
A Word About the InnoDB Buffer Pool LRU Algorithm
In order to better understand what the above metrics mean, we should briefly review how the InnoDB Buffer Pool LRU Algorithm works.
InnoDB manages the buffer pool as a list, using a variation of the least recently used (LRU) algorithm. When room is needed to add a new page to the pool, InnoDB evicts the least recently used page and adds the new page to the middle of the list. This “midpoint insertion strategy” treats the list as two sublists:
- At the head, a sublist of “new” (or “young”) pages that were accessed recently.
- At the tail, a sublist of “old” pages that were accessed less recently.
This algorithm keeps pages that are heavily used by queries in the new sublist. The old sublist contains less-used pages, which are candidates for eviction.
With that in mind, here are some of the more important fields in the InnoDB Standard Monitor output:
- Old database pages: The number of pages in the old sublist of the buffer pool.
- Pages made young, not young: The number of old pages that were moved to the head of the buffer pool (the new sublist), and the number of pages that have remained in the old sublist without being made new.
- Youngs/s non-youngs/s: The number of accesses to old pages that have resulted in making them young or not. This metric differs from that of the previous item in two ways. First, it relates only to old pages. Second, it is based on the number of accesses to pages and not the number of pages. (There can be multiple accesses to a given page, all of which are counted.)
- Young-making rate: Hits that cause blocks to move to the head of the buffer pool.
- Not: Hits that do not cause blocks to move to the head of the buffer pool.
The young-making rate and not rate will not normally add up to the overall buffer pool hit rate.
Some MySQL Performance Tuning Tips
If you see very low youngs/s values when you do not have large scans going on, that may be an indication that you have to either reduce the delay time for a block to be moved from the old to the new sublist, or increase the percentage of the buffer pool used for the old sublist.
If you do not see a lot of non-youngs/s when you are doing large table scans (and lots of youngs/s), try tuning your delay value to be larger.
The innodb_old_blocks_time global variable specifies how long in milliseconds (ms) a page inserted into the old sublist must stay there after its first access before it can be moved to the new sublist. If the value is 0, a page inserted into the old sublist moves immediately to the new sublist the first time it is accessed, no matter how soon after insertion the access occurs. If the value is greater than 0, pages remain in the old sublist until an access occurs at least that many milliseconds after the first access. For example, a value of 1000 causes pages to stay in the old sublist for 1 second after the first access before they become eligible to move to the new sublist.
The following statement sets the innodb_old_blocks_time to zero:
SET GLOBAL innodb_old_blocks_time = 0; The innodb_old_blocks_pct global variable specifies the approximate percentage of the buffer pool that InnoDB uses for the old block sublist. Increasing the old sublist percentage makes it larger, so blocks in that sublist take longer to move to the tail and be evicted. This increases the likelihood that they will be accessed again and be made young. The range of values is 5 to 95. The default value is 37 (that is, 3/8 of the pool).
When scanning small tables that do fit into memory, there is less overhead for moving pages around within the buffer pool, so you can leave innodb_old_blocks_pct at its default value, or even higher, such as innodb_old_blocks_pct=50.
There are many other global status variables you can examine in addition to innodb_old_blocks_time and innodb_old_blocks_pct:
SHOW GLOBAL STATUS LIKE 'Innodb_buffer_pool%';
Variable_nameValue
-----------------------------------------------------------
Innodb_buffer_pool_dump_status, not started
Innodb_buffer_pool_dump_status not started
Innodb_buffer_pool_load_status not started
Innodb_buffer_pool_pages_data460
Innodb_buffer_pool_bytes_data7536640
Innodb_buffer_pool_pages_dirty 0
Innodb_buffer_pool_bytes_dirty 0
Innodb_buffer_pool_pages_flushed1
Innodb_buffer_pool_pages_free7730
Innodb_buffer_pool_pages_misc2
Innodb_buffer_pool_pages_total 8192
Innodb_buffer_pool_read_ahead_rnd0
Innodb_buffer_pool_read_ahead0
Innodb_buffer_pool_read_ahead_evicted 0
Innodb_buffer_pool_read_requests15397
Innodb_buffer_pool_reads461
Innodb_buffer_pool_wait_free0
Innodb_buffer_pool_write_requests1Of these, some metrics will be more useful to you than others. Standouts include:
- Metrics tracking the total size of the buffer pool
- How much is in use
- How effectively the buffer pool is serving reads
The metrics Innodb_buffer_pool_read_requests and Innodb_buffer_pool_reads are integral to gauging buffer pool utilization. Innodb_buffer_pool_read_requests are the number of requests to read a row from the buffer pool and Innodb_buffer_pool_reads is the number of times Innodb has to perform read data from disk to fetch required data pages. Reading from memory is generally much faster than reading from disk, so keep an eye out for increasing Innodb_buffer_pool_reads numbers!
Buffer pool efficiency can be calculated using the formula:
innodb_buffer_pool_reads/innodb_buffer_pool_read_requests*100= 0.001
Here’s an example:
mysql> SHOW GLOBAL STATUS LIKE 'innodb_buffer_pool_rea%';
Variable_name Value
-----------------------------------------------
Innodb_buffer_pool_read_requests | 2905072850 |
Innodb_buffer_pool_reads | 1073291394 |
Calculating the Innodb buffer pool efficiency:
(107329139 / 2905072850 * 100) = 37
In this particular case, the Innodb is doing more disk reads, so the Innodb buffer pool is not large enough.
Buffer pool utilization is another useful metric to check. The utilization metric is not available as such but can be easily calculated as follows:
(Innodb_buffer_pool_pages_total - Innodb_buffer_pool_pages_free)
----------------------------------------------------------------
Innodb_buffer_pool_pages_total
Here’s an example:
SHOW GLOBAL STATUS LIKE 'Innodb_buffer_pool_pages%';
Variable_name Value
-----------------------------------------------
Innodb_buffer_pool_pages_data460
Innodb_buffer_pool_pages_dirty 0
Innodb_buffer_pool_pages_flushed1
Innodb_buffer_pool_pages_free7730
Innodb_buffer_pool_pages_misc2
Innodb_buffer_pool_pages_total 8192
Plugging the numbers into our formula:
(8192 – 7730) / 8192 = 0.056396484375
We can convert that into a percentage by multiplying by 100:
0.056396484375 * 100 = 5.64% (Quite low!)
The fact that your database is serving a large number of reads from disk while the buffer pool is near empty is not in itself cause for celebration; it may be that your cache has recently been cleared and is still in the process of refilling. However, should this condition continues for an extended amount of time, it’s very likely that there is plenty of memory to accommodate your dataset.
High buffer pool utilization is not necessarily a bad thing either, as long as old data is being aged out of the cache according to the LRU policy.
Only when read operations are overpowering the buffer pool, should you start to seriously think about scaling up your cache.
Converting Buffer Pool Metrics to Bytes
Most buffer pool metrics are reported as a count of memory pages, which is not all that useful. Luckily, page counts can be converted to bytes, which makes it a lot easier to determine the actual size of your buffer pool. For instance, this simple formula gives us the total size of buffer pool in bytes:
Innodb_buffer_pool_pages_total * innodb_page_size
The innodb_page_size can be retrieved using a SHOW VARIABLES query:
SHOW VARIABLES LIKE "innodb_page_size"
Monyog offers the most useful Buffer Pool metrics at a glance:

Conclusion
In this final installment of 2-part blog series, we learned how to capture and study MySQL metrics that provide the most value for the effort. The salient points covered include:
- Client connection requests on the network interfaces that the server listens to are handled by the Connection manager.
- It’s important to monitor your client connections because, once the database server runs out of available connections, new client connections are refused!
- Every time a client is unable to connect, the server increments the Aborted_connects status variable.
- Fine-grained connection metrics such as Connection_errors_max_connections and Connection_errors_internal can be instrumental in pinpointing the source of connection problems.
- MySQL’s default storage engine, InnoDB, uses a special storage area called the buffer pool to cache data for tables and indexes.
- Buffer pool metrics are categorized as resource metrics.
- You can configure various aspects of the InnoDB buffer pool to improve performance.
- InnoDB Standard Monitor output provides a number of metrics pertaining to the operation of the InnoDB buffer pool.
- The least recently used (LRU) algorithm employs a “midpoint insertion strategy” that treats the pages as “old” and “new” sublists.
- The LRU algorithm can be tuned using the innodb_old_blocks_time and innodb_old_blocks_pct global variables.
By tracking the most useful metrics and reviewing them in the most informative way(s), we strike a balance between over-monitoring and firefighting unforeseen crises.
Monyog is a MySQL monitoring tool that improves the database performance of your MySQL powered systems. Download your free trial.
Published at DZone with permission of Shree Nair. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments