Top 20 Requirements of a Data Warehouse
We take a look at some of the considerations that a great data warehouse needs to cover. Do you agree with these points?
Join the DZone community and get the full member experience.
Join For FreeThis is one of most challenging and interesting periods of my career, as there's never been a better time to work in the Analytics and Data Warehousing industry.
This article will present a wish list. A set of requirements of an ideal Data Warehouse Analytics platform, and reveal how a new and highly innovative solution delivers a unique architecture, which addresses each of requirements of my ideal wish list.
What Problem Are We Trying to Solve?
When called to a design review meeting, my favorite phrase "What problem are we trying to solve?" Inevitably, when you get a team of highly experienced solution architects in the room, they immediately start suggesting solutions, and often disagreeing with each other about the best approach. It's a bit like when you get three economists in a room, and get four opinions.
In data warehousing, what problem are we really trying to solve? Here are my thoughts on a potential wish list of requirements.
The Requirements
- Workload Separation: One of the greatest challenges facing solution architects today is maintaining the balance of compute resources for a number of competing user groups. The most obvious one is ELT/ETL load processes which need to extract, transform, clean, and aggregate the data, and the end-users who want to analyze the results to extract value. Who should be given priority? The diagram below illustrates the massively different workloads of these two competing groups. The ELT processes perhaps running a regular batch load with multiple parallel processes causing 100% CPU usage, and the analyst workload which is much more irregular. This requirement is to separate these workloads, and eliminate the contention between user groups.

- Maximize Data Loading Throughput: As indicated above, we need to rapidly extract, load, and transform the data, and this means we need to maximize the throughput — the total amount of work completed, rather than the performance of any single query. To achieve this, we typically need to run multiple parallel load streams with CPU usage approaching 100%, and this is challenging alongside the need balance these demands with the need for a high level of end-user concurrency.
- Maximize Concurrency: A typical analytics platform has a number of busy users who just want to get their job done. They want their results as quickly as possible, but they are often fighting for machine resources with everyone else. In summary, we need to maximize concurrency. The ability to handle a large number of queries from multiple users at the same time. Almost every data warehouse, both on-premise and cloud-based, is built upon a single principle: size for the biggest workload, and hope for the best. While solutions like Google BigQuery and Amazon Redshift provide some flexibility, they, like every on-premise platform, are eventually restricted by the size of the platform. The reality for most users is query performance is often poor, and at month or year end, it becomes a struggle to deliver results in time. In an ideal world, the data warehouse would automatically scale-out to add additional compute resources on-the-fly as they were needed. The hardware resources would simply grow (and shrink) to match the demands, and the users would be billed for the actual compute time they used – not a monolithic investment every five years with the promise of superb performance – for a while.
- Minimize Latency – Maximum Speed: C-Suite executives and front office traders want sub-second response times on their dashboards. They are not concerned with the ETL throughput or batch report performance — they want extremely low latency on dashboard queries. An ideal platform would have multiple levels of caching including result set caching to deliver sub-second performance on executive dashboards, while segmenting workloads so performance is not degraded by large complex reports.
- Fast Time to Value: Since data warehouses were first proposed by Ralph Kimball and Bill Inmon in the 1980s, the typical data loading architecture has remained unchanged. Effectively data is extracted from the source systems over-night, and the results transformed and loaded to the warehouse in time for analysis at the start of the next working day. In an increasingly global 24x7 economy over-night batch processing is no longer an option. With globally-based supply chains and customers, the systems which feed the warehouse no longer pause, and data must be fed constantly, in near real-time. To put this in context, back in 1995 a leading UK mobile phone provider took 30 days to capture and analyze retail cellphone sales, and the marketing director was thrilled when we delivered a warehouse solution to capture results from the previous day. The currently installed systems need to combine operational data (customer cellphone numbers) with usage patterns by location and volume in near real-time to identify and protect against fraudulent use. An ideal data warehouse would provide native facilities to stream data in near real-time while maintaining full ACID transactional consistency, automatically scaling up or down the compute resources needed, and isolating the potentially massive spikes in workload from end-users.
- Need to handle Semi-Structured Data: The rapid rise of Hadoop and NoSQL solutions (for example, MongoDB and Couchbase) was largely driven by the need to process semi-structured data, and JSON format in particular. Unlike traditional structured data which comes in a predefined structured form, (like a spreadsheet with rows and columns), JSON data includes repeating groups of values, and the structure may change over time. Initially used by web sites to provide a standard data transfer method, JSON is now the defacto data transfer method for a huge volume of web-based traffic, and is increasing used by sensors to format and deliver data as part of the Internet of Things industry. The particular challenge around handling JSON is its flexible nature, which means the structure is expected to change over time with new attributes being added, and a single data warehouse often needs to take multiple feeds from a wide variety of sources, each in a different structure. Ideally, the data warehouse would handle both structured and semi-structured data natively. It would be possible to simply load JSON or XML data directly into the warehouse without building an ETL pipeline to extract the key components. We could then write queries to combine both the structured data (eg. Sales transactions), alongside the semi-structured data (eg. Social media feeds) from the same location.
- Business Intelligence Performance: Related to data loading throughput, this requirement refers the business intelligence community who often need to run large and complex reports to deliver business insight. Often working to demanding deadlines they need the maximum available compute performance especially for end of month or end of year reports.
- Independently Sized: One size fits all is no longer a viable approach. Any business has multiple independent groups of users, each with different processing requirements. It should be possible to run multiple independent analytics workloads on independently deployed computers, each sized to the needs and budget which is illustrated in the diagram below.
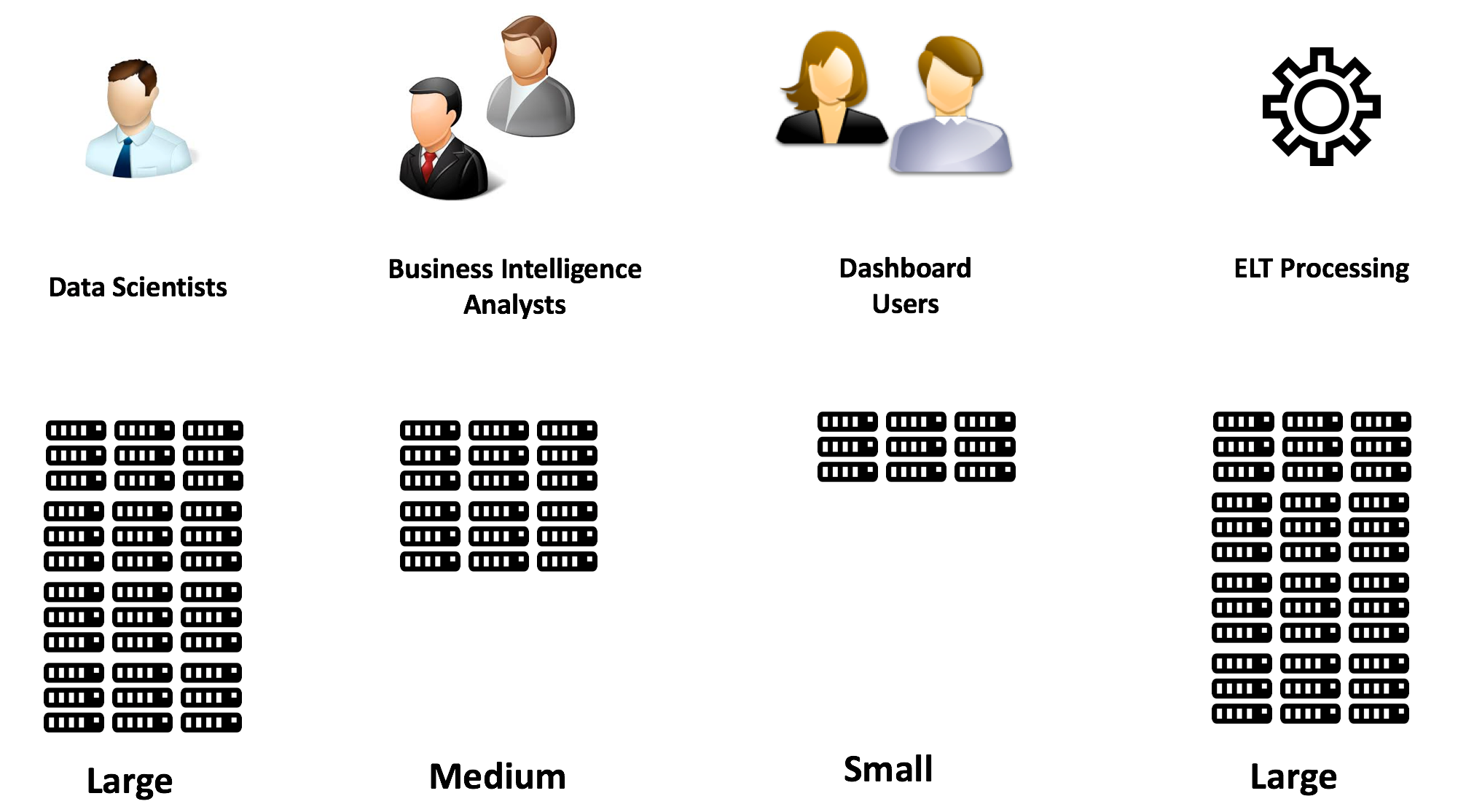
Traditionally, the only way to guarantee performance for a departmental group of users was to invest in, and maintain, their own hardware, but call it a Data Mart to hide the fact it was really another Data Silo. This leads to inconsistencies, as data is summarized and reported from multiple sources, and no two reports agree the same result.
An ideal solution would be capable of running large compute intensive ELT/ETL processes on huge powerful machines without impacting smaller departmental teams of business intelligence analysts running queries against the same data. Each user group would have their own independently sized machines, and each could be sized appropriately.
Of course, every data mart (data silo) can in theory be sized independently, but ideally, we want all the users to have access to all the data. Why extract, transform and copy the data to another location? Every department should be able to transparently access all the data across the entire enterprise (subject to authority), but each independently sized to the task at hand.
"Once copied, data will diverge” - The Law of Data Silos.
- Low Entry Point: Every multi-terabyte data warehouse starts with a single requirement, a single fact table, perhaps a single report. If successful, the platform grows, but it's important (especially to small to medium sized start-ups), to have a low entry point. Data Warehousing used to be the province of large multi-nationals, but business insight is a critical requirement for any business, small or large.
- Quickly Scalable: The system must be incrementally scalable — perhaps from gigabytes to terabytes or even multiples of petabytes. It must be possible to add additional compute and storage resources as they are needed, ideally without any down-time or compute intensive data reorganization or distribution. In short, it must be possible to add additional compute and storage resources to either increase concurrency (more users) or processing (faster delivery of huge workloads) without down-time or interruption of service.
- Inexpensive: The solution should involve no up front capital expenditure or commitment, and be inexpensive to operate with costs in line with usage. Until recently, the only options available to build an analytics platform involved a huge capital outlay on expensive hardware and database licenses. Once analytic query demands and data volumes exceed the multi-terabyte level, we typically needed a lengthy and expensive migration project to move to a larger, even more expensive system. This is no longer a viable strategy, and the ideal solution should use a flexible pay-as-you-use model with costs in line with usage.
- Elasticity: Closely related to the inexpensive requirement above, this means the solution needs to dynamically match the compute resources requirement. It should be possible to rapidly increase the available resources to match a regular or unexpected query workload, perhaps to process end of month reporting or a massive data processing task. Equally, it should be easy to scale back the processing resources when the task completes, with costs in line with usage, and ideally the entire process should be transparent to users. Finally, when not needed, it should be possible to suspend compute resources to control costs, with the option to automatically resume processing within seconds when needed.
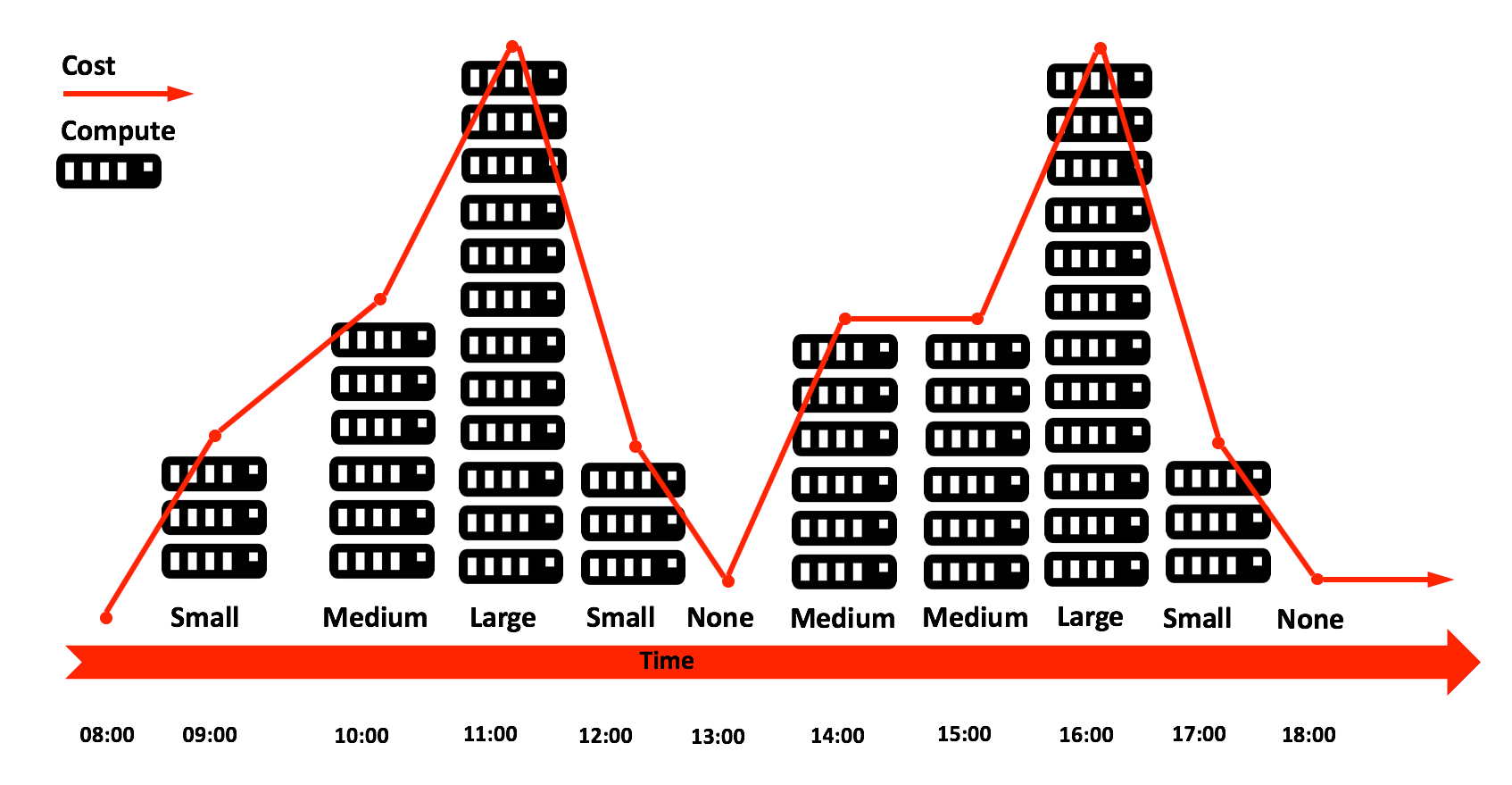
- Consolidated: Many data warehouse initiatives lead to a disparate number of independently loaded data marts. Aside from the risk of inconsistencies creeping in, there's also the issue around timing delivery as results fail to be delivered consistently to all marts at the same instant. In one project, users frequently complained of inconsistent sales figures from two systems which were (ironically) sourced from the same raw data. This requirement means all the data should be consolidated into a single data-store, and accessible to all users. Likewise, the solution should support queries against structured and semi-structured data to avoid the spread of technologies including relational, NoSQL, and Hadoop data stores.
- Low Administration Burden: Oracle supports 14 types of indexes including B-Tree, Bitmap, Partitioned, Clustered, and Index Organized Tables, and there are numerous situations in which indexes are disabled, potentially leading to an exception or failure. Equally, Oracle llg has over 450 independently adjustable parameters to tune the database, and most systems need a highly skilled DBA for support. Likewise, even with the professional support of Cloudera, Hortonworks, or MapR, it's remarkably difficult to deploy and maintain a Hadoop cluster, and Gartner estimates around 85% of Big Data initiatives don't make it to production. The ideal analytics solution should be simple with few opportunities for major mistakes. In short, it should just work.
- Accessible for Data Sharing: As Bill Schmarzo (CTO at EMC Global Services) has indicated, "Data monetization is the holy grail of Big Data." In his book, Understanding how Data Powers Big Business, he describes the five stages of maturity including Data Monetization, which are illustrated below.
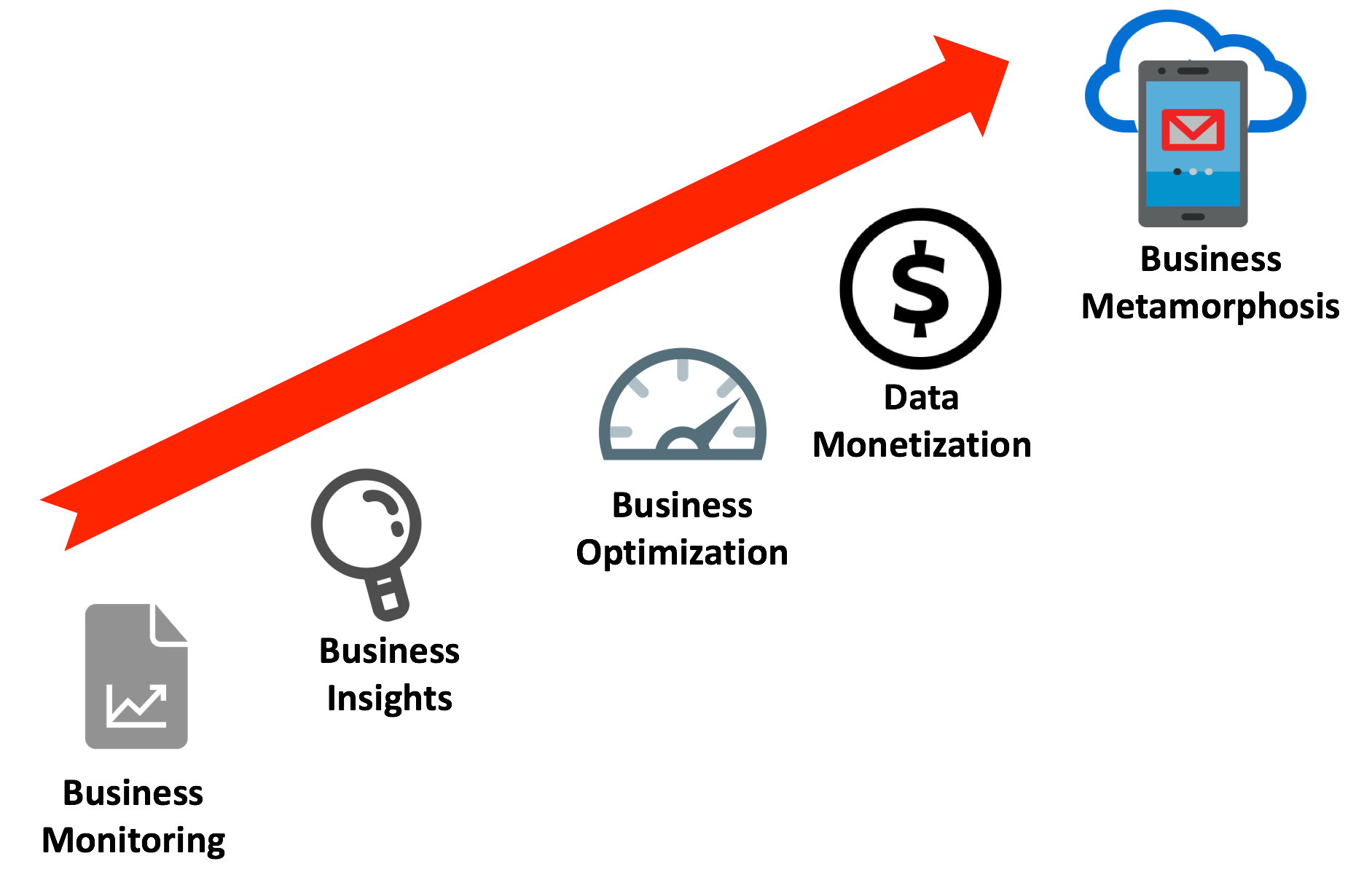 This requirement refers to the ability to securely share access to data with business partners, suppliers, or subsidiaries. The traditional method involves building an expensive ETL pipeline to extract and deliver the data to partners or delivering a pre-defined analytics dashboard which is either expensive to build and maintain or (in the case of pre-built dashboards) limits the analytic options available. The ideal analytic platform would allow secure access to any authorized client, anywhere in the world to run their own reports and analyses. That way, as the data changes, there's no need extract and transfer data changes, it's simply queried in place.
This requirement refers to the ability to securely share access to data with business partners, suppliers, or subsidiaries. The traditional method involves building an expensive ETL pipeline to extract and deliver the data to partners or delivering a pre-defined analytics dashboard which is either expensive to build and maintain or (in the case of pre-built dashboards) limits the analytic options available. The ideal analytic platform would allow secure access to any authorized client, anywhere in the world to run their own reports and analyses. That way, as the data changes, there's no need extract and transfer data changes, it's simply queried in place. - Technically Accessible: As NoSOL database vendors have realized, solutions which are accessible only to Java programmers are of limited use, and systems must be accessible to business analysts and users using industry standard SQL. This requirement means the solution must support industry standard SQL rather than an application programmer interface (API).
- Hold all the Data: As the voracious appetite for data grows, it’s no longer an option to scale up to a larger hardware platform every few years. The ideal solution would provide an infinite data storage capacity, with potentially infinite compute resources. It should have already proven itself with some of the largest data consumers on the planet, and support systems with petabytes of data in a single table.
- Simplicity: Having worked in IT since 1984 as a developer, designer, and architect, the single biggest lesson I've learned is to Keep it Simple. As I have indicated before – I find designers sometimes deliver over-complex generic solutions that could (in theory) do anything, but in reality, are remarkably difficult to operate and often misunderstood. The solution should be elegant, and most importantly, simple.
"Everything should be as simple as possible, but not simpler." - Albert Einstein.
Summary
I’d expect many people reading this article to be highly skeptical that it's even remotely possible to deliver a solution to satisfy all the above requirements, and just a few years ago I would have agreed. However. Snowflake Computing (founded in 2012) was established by a team of ex-Oracle database experts, and they have achieved just that.

In my next article, I will explain in detail how Snowflake delivers a unique and innovative architecture which supports multiple different sized workloads without any contention. Each may be sized to the particular problem, and even automatically scale out as additional users make additional demands on the system. A fully ACID transactionally consistent SQL database, it is remarkably easy to maintain with few options to tune and configure — it just works.
Best of all, it is the only data warehouse which was built entirely for the cloud, and has all the benefits of infinite storage, and almost unlimited compute resources on demand. Watch this space!
"Everyone is going to move to the cloud. That's going to be hugely disruptive. We're going to run database systems where we run a million nodes. "- Professor Mike Stonebraker (MIT).
Disclaimer: The opinions expressed in my articles are my own and will not necessarily reflect those of my employer (past or present) or indeed any client I have worked with.
Note: This article first appeared on my personal blog.
Published at DZone with permission of John Ryan, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments