The Zero Copy Principle With Apache Kafka
When doing computer processes, the zero-copy technique is employed to prevent the CPU from being used for data copying across memory regions.
Join the DZone community and get the full member experience.
Join For FreeThe Apache Kafka, a distributed event streaming technology, can process trillions of events each day and eventually demonstrate its tremendous throughput and low latency. That’s building trust and over 80% of Fortune 100 businesses use and rely on Kafka. To develop high-performance data pipelines, streaming analytics, data integration, etc., thousands of companies presently use Kafka around the globe. By leveraging the zero-copy principle, Kafka improves efficiency in terms of data transfer. In short, when doing computer processes, the zero-copy technique is employed to prevent the CPU from being used for data copying across memory regions. Additionally, it removes pointless data copies, conserving memory bandwidth and CPU cycles.
Broadly, the zero-copy principle in Apache Kafka refers to a technique used to improve the efficiency of data transfer between producers and consumers by minimizing the amount of data copying performed by the operating system. By minimizing the CPU and memory overhead involved in copying data across buffers, the zero-copy technique can be very helpful for high-throughput, low-latency systems like Kafka.
Without the zero-copy principle or adopting a traditional approach, when data is produced by a Kafka producer irrespective of any programming language, it is typically stored in a buffer (e.g., a byte array). When this data needs to be sent to the Kafka broker for storage in a designated topic, the data is copied from the producer’s buffer to a network buffer managed by the operating system. Eventually, the operating system then copies the data from its buffer to the network interface for transmission.
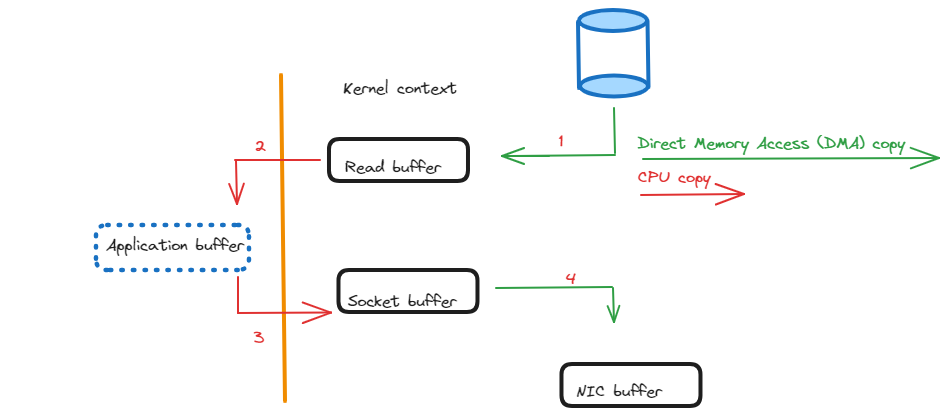
But with the zero-copy approach, the operating system leverages features such as scatter-gather I/O or memory-mapped files to avoid unnecessary data copying. Instead of copying the data multiple times between different buffers, the operating system allows the data to be read directly from the producer’s buffer and written directly to the network interface, or vice versa. This eliminates the need for intermediary buffers and reduces the CPU and memory overhead associated with copying large amounts of data.
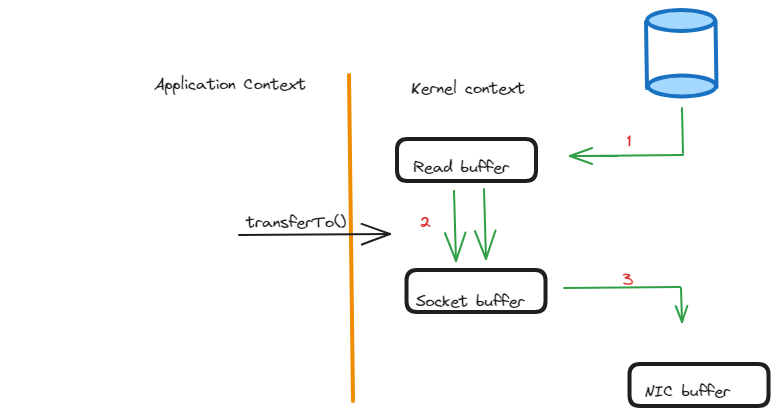
The advantages of Apache Kafka’s zero-copy principle include:
- Reduced CPU usage: The zero-copy technique lowers the CPU use related to data transfer activities by minimizing needless data copying. In order to get high throughput and low latency performance with Kafka, this is essential.
- Improved latency: Minimizing data copying can lead to lower latency, as data can be transmitted more quickly without the additional overhead of copying between buffers.
- Efficient use of system resources: In situations when there are large volumes of data and strict performance requirements, Kafka can utilize system resources more effectively thanks to the zero-copy principle.
It’s crucial to remember that the capabilities of the underlying operating system and network hardware affect how successful zero-copy is. Kafka maximizes data flow between producers and brokers by utilizing the zero-copy principle, which enhances the overall effectiveness and performance of Apache Kafka, the distributed event streaming system.
Hope you have enjoyed this read. Please like and share if you find this composition valuable.
Published at DZone with permission of Gautam Goswami, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments