The Origins of ChatGPT and InstructGPT
ChatGPT has been a rage since it was revealed to the world. Let’s look into some technical details of its evolution.
Join the DZone community and get the full member experience.
Join For FreeChatGPT is a Large Language Model (LLM) built for conversation. It is a successor to InstructGPT. Both these models are built by OpenAI. I won't waste your time with another article about its uses or examples of how it performs.
These models are chatbots (the ability to converse with humans and maintain a dialogue), which are active areas of Natural Language Processing (NLP) research. There have been quite a few notable attempts (Tay from Microsoft, for example) which failed spectacularly after being left to train with open data from Twitter.
Note: If you haven’t had a chance to check out ChatGPT yet, do that here. It is free to use for now.
Jumping back in:
So what makes ChatGPT so special?!
- Better instruction following
- Safety guardrails
And how does it do that?
Through human-labeled data and a nifty way to use that.
While there is no paper/ white paper to describe the ChatGPT model, the closest technical details we can get are from InstructGPT. The whitepaper can be found at this link.
From OpenAI:
We’ve trained a model called ChatGPT which interacts in a conversational way. The dialogue format makes it possible for ChatGPT to answer followup questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests. ChatGPT is a sibling model to InstructGPT, which is trained to follow an instruction in a prompt and provide a detailed response.
OpenAI makes it pretty clear that ChatGPT is very similar to InstructGPT, different only in the amount of data the model is trained with.
InstructGPT is a fine-tuned version of GPT3. GPT3 is an LLM trained for text completion. You give it some prompt; it predicts the next words that make sense to it. But there is a problem! Since it only does text completion, it doesn’t really “understand” your prompts very well, and the dialogue is even more incoherent. Even after trying to cajole it with “prompt engineering,” it could yield responses that are false, toxic, or reflect harmful sentiments. InstructGPT fixes that exact problem.
Think of GPT3 as the racist uncle on Thanksgiving with no filter. He needs “help” from other adults to be PC and suitable for children :D
InstructGPT solves this by “aligning” the model's objectives with what a human user might prefer. More factual, honest answers, less toxicity, and so on.
Perfect, now let’s get to the meat of InstructGPT: Reinforcement Learning from Human Feedback (RLHF). Basically, they use a small subset of human-labeled data to build a reward model.
To simplify, look at it like this:
Generally, Reinforcement Learning looks like this. The environment generates a reward for each action.
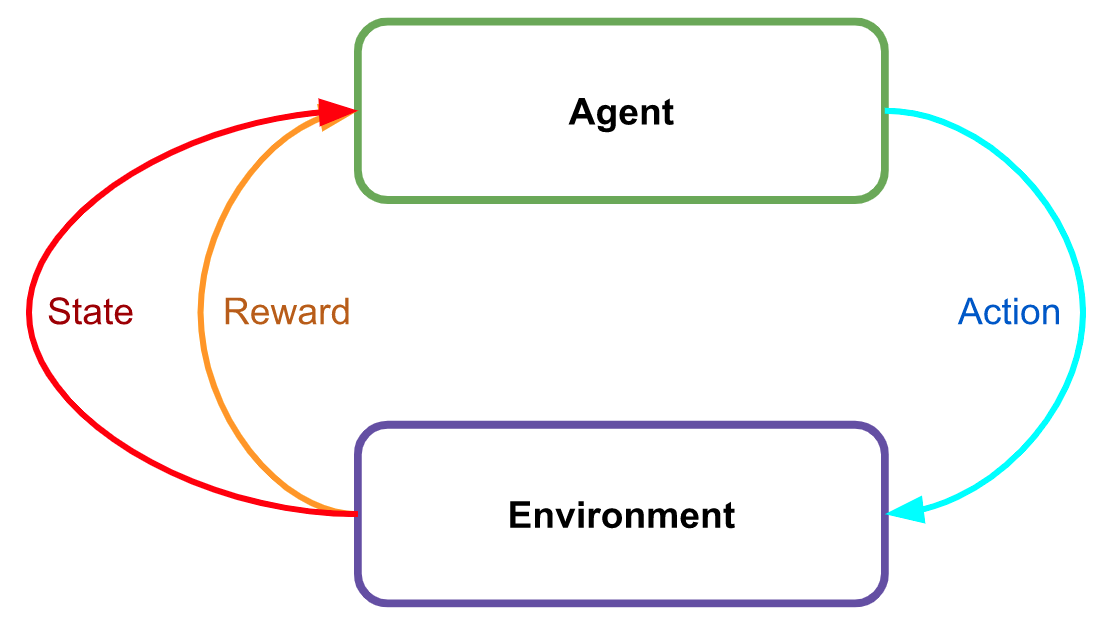
InstructGPT (and, by induction, ChatGPT) uses a separate, specially engineered, and labeled reward model.

The image (from OpenAI’s paper) shows the three steps in creating this model.

The only difference between this and InstructGPT is the base model: GPT3 vs. GPT3.5. GPT3.5 is a larger model with more data. RM -> Reward Model.
Step 1: Supervised Fine Tuning (SFT): Learn how to answer queries.
Step 2: Training a Reward Model with human labels: Build a model for ranking queries. Humans will rank queries based on correctness and other factors.
Step 3: Reinforcement Learning with the RM from Step 2: Learn to "talk" like a human.
One can imagine that this makes the model tamer and hallucinating much less since it is now trying to appease a human master.
Results
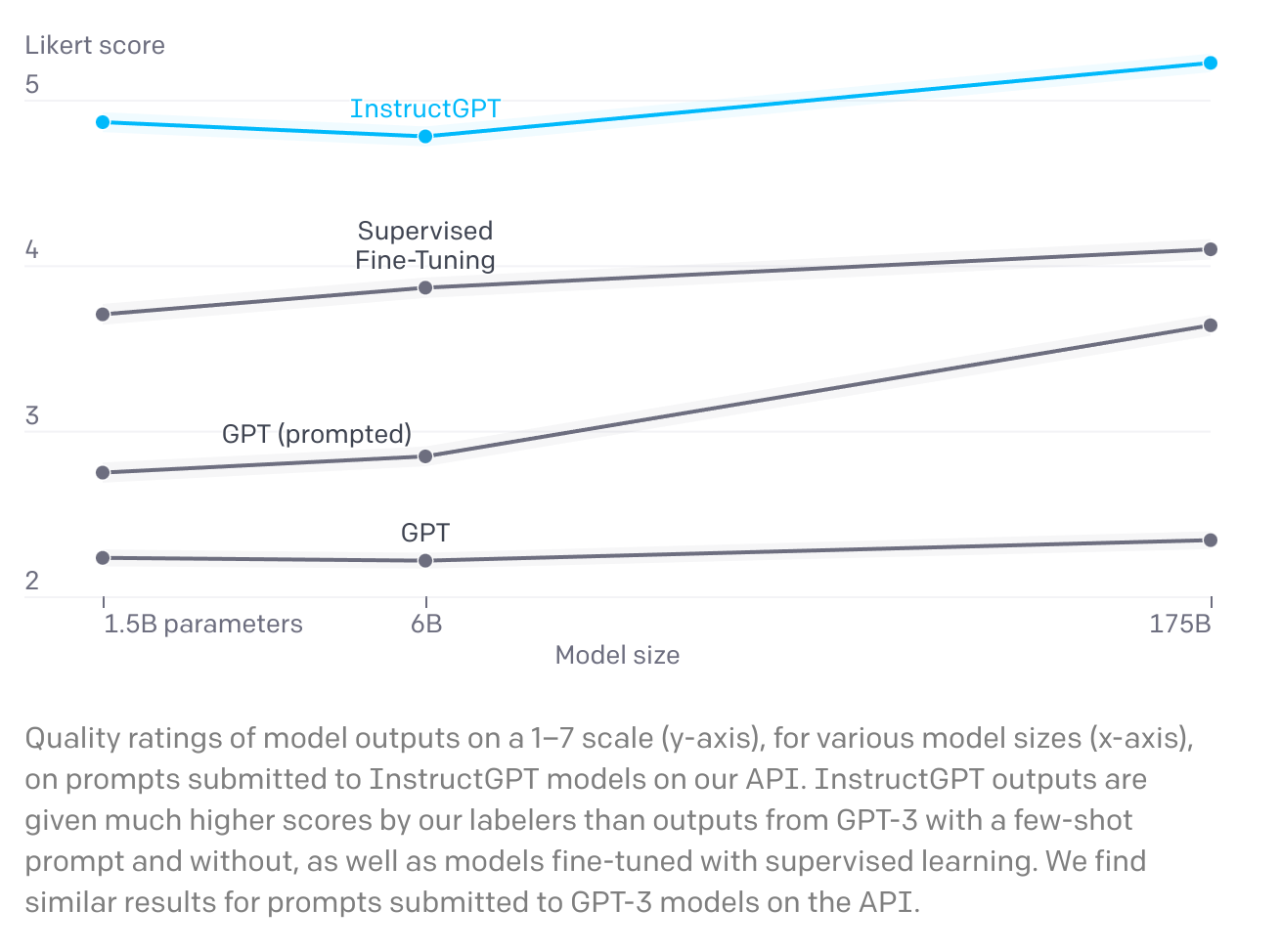
And this yields exciting results! According to OpenAI, their human labelers “significantly prefer” the outputs from InstructGPT over GPT and GPT (prompted), which refers to GPT with an extra prompt to follow the instructions.
Likert scale/score is simply the 1-7 rating for each response.
Apparent Limitations of This Approach
- Biases: How does one ensure their human labelers are not biased? Any implicit bias in the labels will pass onto the networks. One way to solve this is using a held-out set of “labelers” to rank model outputs and compare them to the results produced by OpenAI’s trained labelers. According to OpenAI, this experiment does show similar rates/ ranks.
- Generalizing to a broader range of topics: How do we ensure that these labelers have the required knowledge and expertise in specific topics?
And Finally, Future Work
ChatGPT can still write plausible-sounding but incorrect or nonsensical answers. This is hard to fix:
There is no “real” ground truth during the RL training in Step three. The model is essentially trying to produce “nice” responses.
Training the model to be more cautious causes it to decline questions that it can answer correctly. Think of it this way; the model would rather not answer than risk upsetting you.
Supervised training tries to clone human behavior without the same level of knowledge. The human labeler might have some background info that the model may not know (and vice versa).
Limited Reproducibility/ Reliability: With minor tweaks to the input prompt or asking the same question in slightly different ways, ChatGPT can respond with high variations. For example, given one phrasing of a question, the model can claim not to know the answer but can answer correctly with a rephrase.
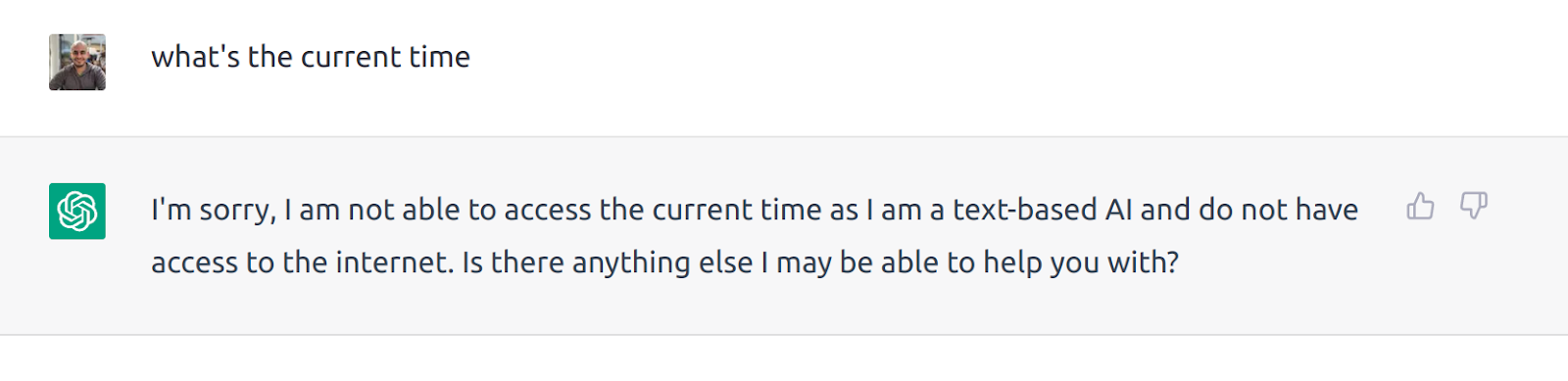
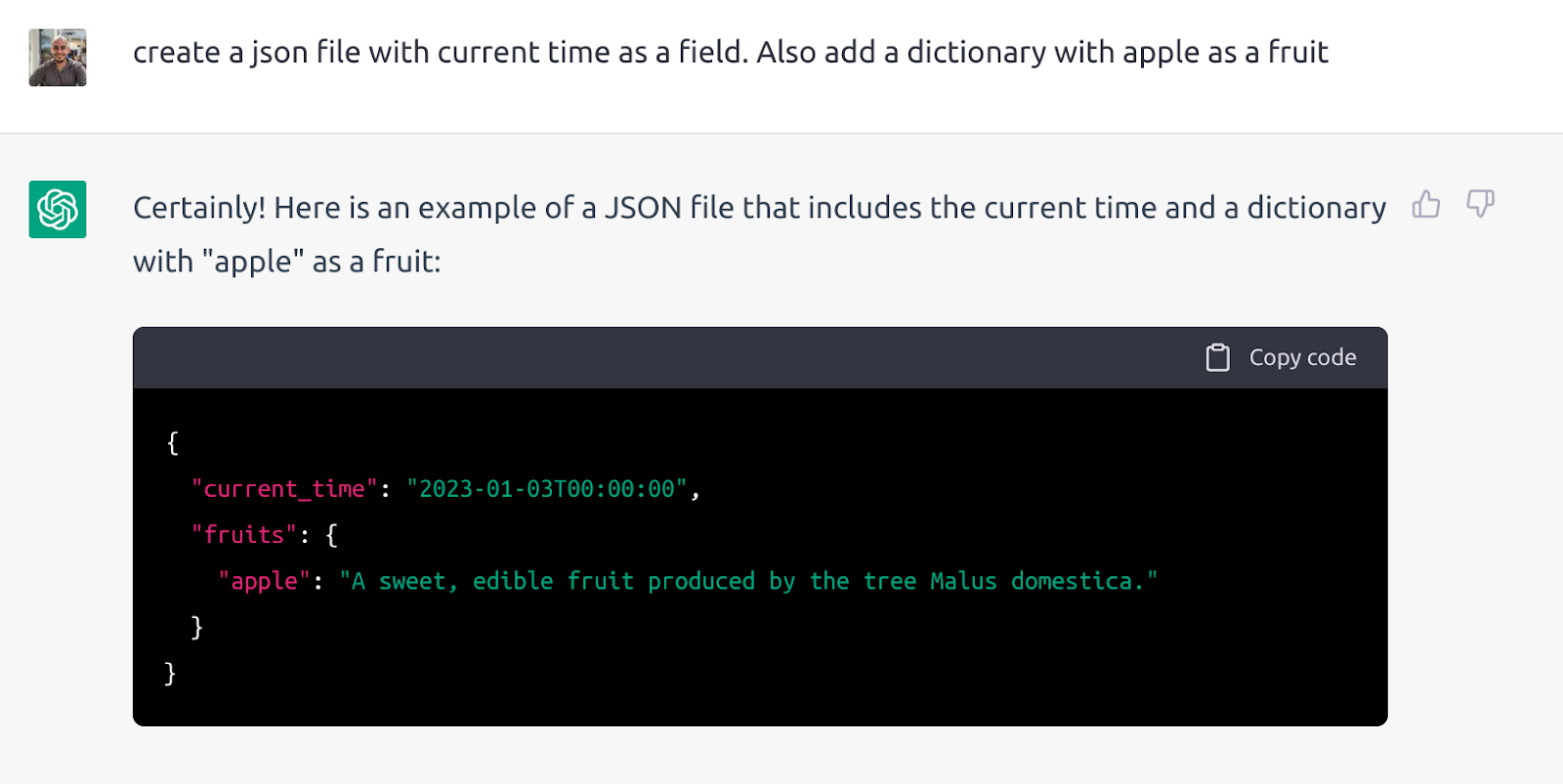
I found this example on Twitter but can’t recall now, so here’s a reproduction. In the first case, ChatGPT refuses to return the current time, but in the second case, after being misdirected to create a file, it does return a valid date.![]()
![]()
Excessively Verbose: ChatGPT is often excessively verbose and overuses certain phrases, such as restating that it’s a language model trained by OpenAI. These issues arise from biases in the training data (trainers prefer longer answers that look more comprehensive) and well-known over-optimization issues.
ChatGPT can be fairly confident about incorrect information and often assumes things. Ideally, the model should ask clarifying questions for an ambiguous query. There is also no score/ uncertainty metric associated with the replies, so it is hard to tell when it should be trusted and when not.
Inappropriate requests/ exhibit biased behavior: OpenAI uses Moderation API to warn or block certain unsafe content. But there are still improvements that need to be made. Expect this to improve with more user feedback and testing the world is doing for them. ChatGPT had over a million users within five days and seems to be blowing up the internet since then :)
Once again, give it a shot. You will definitely get a kick out of it.
Opinions expressed by DZone contributors are their own.
Comments