The Lakehouse: An Uplift of Data Warehouse Architecture
This article highlights how an architectural pattern is enhanced and transformed into a traditional data warehouse, eventually turning it into a data lakehouse.
Join the DZone community and get the full member experience.
Join For FreeIn short, the initial architecture of the data warehouse was designed to provide analytical insights by collecting data from various heterogeneous data sources into the centralized repository and acted as a fulcrum for decision support and business intelligence (BI). But it has continued with numerous challenges, like more time consumed on data model designing because it only supports schema-on-write, the inability to store unstructured data, tight integration of computing, and storage into an on-premises appliance, etc.
This article intends to highlight how the architectural pattern is enhanced to transform the traditional data warehouse by rolling over the second-generation platform data lake and eventually turning it into a lakehouse. Although the present data warehouse supports three-tier architecture with an online analytical processing (OLAP) server as the middle tier, it is still a consolidated platform for machine learning and data science with metadata, caching, and indexing layers that are not yet available as a separate tier.
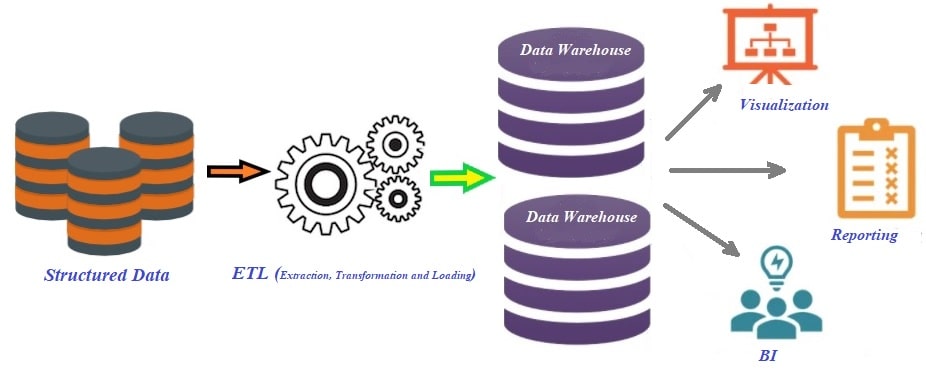
Architecture of Traditional Data Warehouse Platform
The organizations, as well as enterprises, were looking for some alternative/advanced data warehousing system to resolve the complexities and problems associated with traditional data warehouse systems (as mentioned in the beginning) due to rapidly growing unstructured datasets like audio, videos, etc. After surfacing the Apache Hadoop eco-system in the post year 2006, the major bottleneck for extraction and transformation of raw data into structured format (row and column) prior to loading into traditional data warehousing system has been resolved by leveraging HDFS (Hadoop Distributed File System). HDFS handles large data sets running on commodity hardware and accommodates applications that have data sets that are typically gigabytes to terabytes in size. Besides, it can scale horizontally by adding new nodes on the cluster to accommodate a massive volume of data irrespective of any data format on demand. You can read here how Apache Hadoop can be installed and configured on a multi-node cluster.
Another major relief achieved with the Hadoop eco-system (Apache Hive) is that it supports schema-on-read. Due to the strict schema-on-write principle with traditional data warehouses, ETL steps were very time-consuming to adhere to designed tablespaces. In one line statement, we can define a data lake as a repository to store huge amounts of raw data in its native formats (structured, unstructured, and semi-structured) for big data processing with subsequent analysis, predictive analytics, executing machine learning code/app to build algorithms, and more.
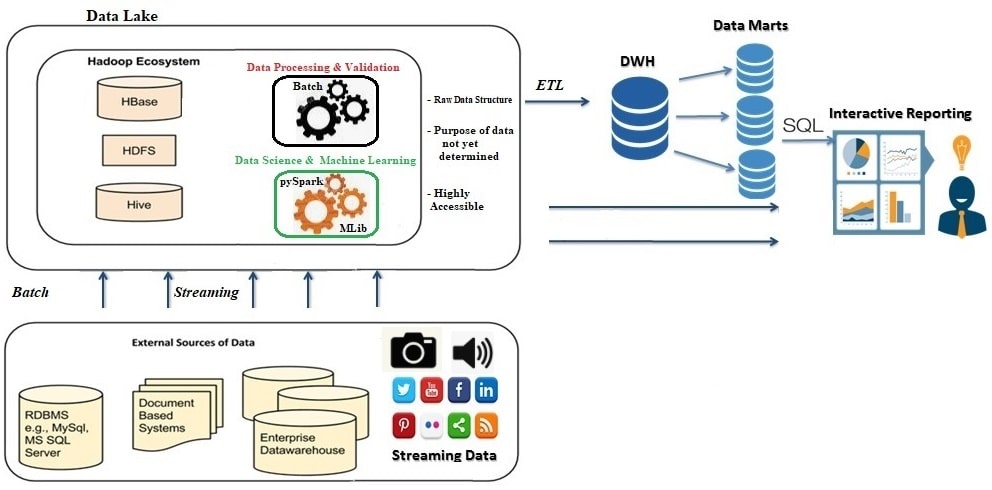
Data Lake Architecture
Even though a data lake doesn’t require data transformation prior to loading, as there isn’t any schema for data to fit, maintaining the data quality is a big concern. A data lake is not fully equipped to handle the issues related to data governance and security. Machine learning (ML), as well as data science applications, needs to process a large amount of data with non-SQL code so that they can be deployed and run successfully over a data lake. But these applications are not well served by data lakes due to a lack of well-optimized processing engines compared to SQL engines. However, these engines are not sufficient alone to solve all the problems with data lakes and replace data warehouses. Features like ACID properties and efficient access methods like indexes are still missing in data lakes. On top of it, these ML and data science applications encounter data management problems such as data quality, consistency, and isolation. Data lakes require additional tools and techniques to support SQL queries so that business intelligence and reporting can be executed.
The idea of data lakehouses is at a beginning phase and will have processing power on top of data lakes, such as S3, HDFS, Azure Blob, and more. The lakehouse combines the benefit of a data lake’s low-cost storage in an open format accessible by a variety of systems and a data warehouse’s powerful management and optimization features. The concept of a data lakehouse was introduced by Databricks and AWS.
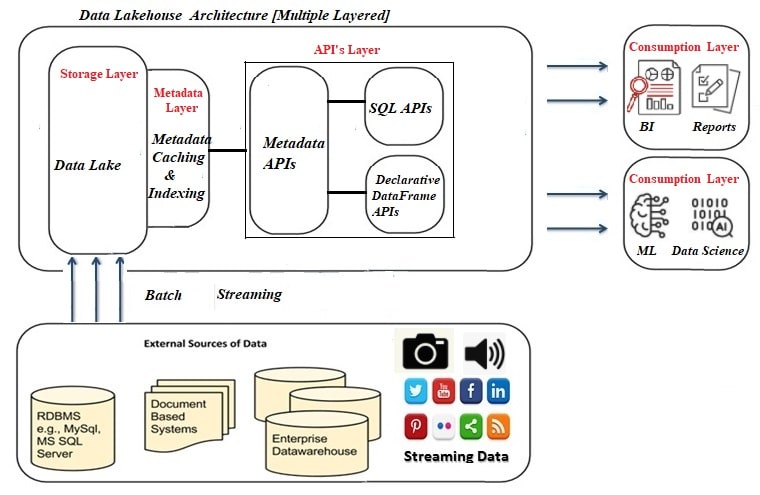 The Multi-Layered Lakehouse Architecture
The Multi-Layered Lakehouse Architecture
A lakehouse will have the capacity to boost the speed of advanced analytics workloads and give them better data management features. From a bird's eye view, the lakehouse will be segmented into five layers, namely the ingestion layer, storage layer, metadata layer, API layer, and eventually the consumption layer.
- The ingestion layer is the first layer in the lakehouse and takes care of pulling data from a variety of sources and delivering it to the storage layer. A variety of components can be used in this layer to ingest data, such as Apache Kafka for data streaming from IoT devices, Apache Sqoop to import data from RDBMS, and many more to support batch data processing as well.
- Data lakehouses are best suited for cloud repository services due to the separation of computing and storage layers. The lakehouse can be implemented on-premise by leveraging HDFS platform. And its design is supposed to allow keeping all kinds of data in low-cost object stores, e.g. AWS S3, as objects using a standard file format such as Apache Parquet.
- The metadata layer in the lakehouse would hold the responsibility of providing metadata (data giving information about other data pieces) for all objects in the lake storage. Besides, the opportunity to fulfill management, features includes:
- ACID transactions to ensure that concurrent transaction
- Caching to cache files from the cloud object store using faster storage devices such as SSDs and RAM on the processing nodes
- Indexing for faster query-making
- The API layer in lakehouses facilitates two types of API: declarative DataFrame API and SQL API. With the help of DataFrame APIs, the data scientists can consume the data directly to execute their various applications. Some machine learning libraries like TensorFlow and Spark MLlib can read open file formats like Parquet and query the metadata layer directly. Similarly, SQL API can be utilized to get the data for BI (combination business analytics, data mining, data visualization, etc.) and various reporting tools.
- Finally, the consumption layer holds various tools and apps like Power BI, Tableau, and many more. A lakehouse’s consumption layer can be utilized by all users across an organization to carry out all sorts of analytical tasks including business intelligence dashboards, data visualization, SQL queries, and machine learning jobs.
The lakehouse architecture is best suited to provide a single point of access within an organization for all sorts of data despite the purpose.
Conclusion
Data cleaning complexity, query compatibility, the monolithic architecture of the lakehouse, caching for hot data, etc., are a few limitations to be considered before completely relying upon lakehouse architecture. Even with all the hype around data lakehouses, it’s worth remembering that the concept is in the very nascent stage. Going forward in the near future, there will be a requirement for tools that enables data discovery, data usage metrics, data governance capabilities, and more on the lakehouse.
Hope you enjoyed this read. Please like and share if you feel this composition is valuable.
Published at DZone with permission of Gautam Goswami, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments