The Evolution of Cloud-Native Authorization
There's been a lot of buzz about fine-grained access control in the past several years. Here's an overview of the key ideas and best practices that have emerged.
Join the DZone community and get the full member experience.
Join For FreeAuthentication in the Age of SaaS and Cloud
Let's start with the differences between authentication and authorization. People tend to lump these concepts together as auth, but they're two distinct processes.
Authentication describes the process of finding out that you are who you say you are. In the past, we used user IDs and passwords. These days it's much more common to use magic links or multi-factor authentication, etc. but, it's the same process.
Authentication used to be the responsibility of the operating system that logs you in once you provide a password. But over the past 15 years, as we moved into the age of SaaS and cloud, that changed. The first generation of SaaS and cloud apps had to reinvent this process because there were no longer any operating systems to ask to authenticate the user's identity.
In the course of the last 15 years, we started to work together as an industry to develop standards around authentication, like OAuth2, OpenID connect, and SAML. We’ve started to use JWTs and so on. Today, no one has to build a log-in system if they don't want to. Numerous developer services can help you do this.
Overall, you can say that we've successfully moved identity from on-premises to the realm of SaaS in the cloud.
Authorization, on the other hand, has not transitioned to the cloud. Authorization, or access control, is the process of discerning what you can see and do once you're logged in. Unlike authentication, authorization is a problem that is far from being solved.
The problem is that there aren’t any industry standards for authorization. You can apply some patterns like role-based access control (RBAC) and attribute-based access control (ABAC), but there are no standards because authorization is a domain-specific problem. There aren't any developer services either. Can you think of a Twilio or a Stripe for authorization? And because there are no standards, or developer services to speak of, companies lose agility because they have to spend time building an in-house authorization system and go through the pain that entails.
You have to think about the opportunity cost. How much will it cost you to spend time developing and maintaining an in-house access control system, instead of focusing on your value propositions? And, unfortunately, when companies do this themselves they do it poorly. This is the reason that broken access control ranks #1 in the top 10 security issues listed by the open web application security project (OWASP). It seems like we really dug ourselves into a pretty big hole and now it's time to dig ourselves back out.
Cloud-Native Authorization
Let's look at how we got here. There have been three transitions that have affected the world of software in general and authorization in particular:
1. Transition to SaaS: Authentication made the move successfully, but access control hasn’t. If we dig into why, we see that back in the day, when applications just talked to the operating system, we had a directory, like LDAP. In this directory, you had groups, with users assigned to those groups. Those groups would typically map to your business application roles and things were pretty simple. But now, we don't have an operating system or a global directory that we can query, so every application has to reinvent the authorization process.
2. Rise of microservices: We’ve seen an architectural shift moving from monolithic applications into microservices. Back when we had monoliths, authorization happened at one time and in one place in the code. Today, we have multiple microservices, and each microservice has to do its own authorization. We also have to think about authorizing interactions between microservices, so that only the right interaction patterns are allowed.
3. Zero-trust: The move from the perimeter-based security approach to zero trust security. With zero trust, a lot of the responsibility for security moved away from the environment and into the application.
We have a new world order now where everything is in the cloud, everything is a microservice, and zero trust is a must. Unfortunately, not all applications have caught up with this new paradigm, and when we compare well-architected applications to poorly architected ones we clearly see five anti-patterns and five corresponding best practices emerge.
Five Best Practices of Cloud-Native Access Control

1. Purpose-Built Authorization Service
Today, every service authorizes on its own. If each microservice has to worry about its authorization, each microservice is likely to do it a little bit differently. So when you want to change the authorization behavior across your entire system, you have to think about how each microservice has to be updated and how the authorization logic works in that microservice, which becomes very difficult as you add more microservices to your system.
The best practice that we want to consider is to extract the authorization logic out of the microservices and create a purpose-built microservice that will only deal with authorization.
In the past couple of years, large organizations have begun publishing papers that describe how their purpose-built authorization system works. It all started with the Google Zanzibar paper that describes how they built the authorization system for Google Drive and other services. Other companies followed and described how they built their purpose-built authorization service and a distributed system around it. These include Intuit’s AuthZ paper, Airbnb's Himeji, Carta’s AuthZ, and Netflix’s PAS. We are now starting to distill these learnings and are putting them into software.
2. Fine-Grained Access Control
The second anti-pattern is baking coarse-grained roles into your application. We often see this in applications where you have roles, such as "admin," "member," and "viewer." These roles are baked directly into the application code and as developers add more permissions, they try to cascade those permissions into these existing roles, which makes the authorization model hard to fine-tune.
The best practice, in this case, is to start with a fine-grained authorization model that applies the principle of least privilege. The goal is to give a user only the permissions that they need, no more and no less. This is important because when the identity is compromised — and this is not a question of if, it's a question of when — we can limit the damage that this compromised identity can potentially cause by limiting the permissions that we assign to the roles that we specify.
3. Policy-Based Access Management
The third anti-pattern that we see is authorization "spaghetti code," where developers have a sprinkled "switch" and "if" statements all around the code that governs the authorization logic. That's a bad idea and costs a lot when you want to change the way that authorization happens across your system.
The best practice here is to maintain a clear separation of duties and keep the authorization-related logic in an authorization policy. By separating policy from application code we ensure that the developer team is responsible for developing the app and the application security team is responsible for securing it.
4. Real-Time Access Checks
The fourth anti-pattern is using stale permissions in an access token. This tends to occur in the early life of an app, when developers leverage scopes and then bake those scopes into the access token.
Here’s a scenario: a user that has an "admin" scope logs in. That scope is baked into the access token and wherever that user interacts with our system using an unexpired access token with the "admin" scope, that user has admin privileges. Why is this bad? Because if we want to remove the "admin" scope from the user and invalidate it, we’ll run into a hurdle. As long as the user holds an unexpired access token, they're going to have access to all the resources that the access token grants them.
You simply cannot have a fine-grade access control model using access tokens. Even if the issuer of the access token has visibility into what resources the user can access, it’s impractical to stuff those entitlements in an access token. Let's say we have a collection of documents and we want to give a user a read permission to a document. Which document are we talking about? All documents? Only a few of them? Clearly this approach doesn’t scale.
The best practice here is never to assume that the access token has the permissions that we need and instead have real-time access checks that take into account the identity context, the resource context, and the permission before we grant access to a protected resource.
5. Centralized Decision Logs
Lastly, unauthorized access is not a question of if, it's a question of when. With that said, companies tend to neglect to maintain consistent authorization logs, which limits their ability to trace unauthorized incidents.
The best practice is to have fine-grained, centralized authorization logs. We need to monitor and log everything in a centralized location that we can analyze downstream to get a better understanding of what’s happening in our system.
Fine-Grained Access Control Patterns

Let's talk a little bit more about fine-grained access control and how it came to be.
Access Control Lists (ACL)
Back in the 80s, operating systems would define permissions, such as "read," "write," and "execute" on files and folders. This patterns was called access control lists (ACL)
With ACL, you can answer questions like: "Does Alice have `read` access to this file?"
Role-Based Access Control (RBAC)
RBAC, or role-based access control, came around in the 90s and early 2000s with the advent of directories like LDAP and Active Directory. These directories give you the ability to create groups and then assign users to groups, which typically correspond to a particular role in a business application. An admin would assign a user to a group to give them the appropriate permissions, and everything was done in one console.
With RBAC, you can answer questions like: "Is Bob in the `Sales admin` role?"
Attribute-Based Access Control (ABAC)
The next evolution was attribute-based access control (ABAC) and that's where we started to move away from coarse roles and toward fine-grained access control. In the early 2000s and 2010s, we saw standards like XACML define how to construct fine-grained authorization policies.
You could define permissions based on attributes, including user-attributes (e.g. the department the user was in) and resource attributes (e.g. what folder is the user trying to access?), or maybe even environmental attributes, (e.g. what is the user's geography? what is the current time and day?)With ABAC, you can answer questions like: "Is Mallory in the `Sales` department? Is the document in the `Sales` folder? And is it currently working hours in the US?"
Relationship-Based Access Control (ReBAC)
Last, but not least, there is the Zanzibar paper and a new authorization model called relationship-based access control (ReBAC). In this model, you define a set of subjects (typically your users or groups), a set of objects (such as organizations, directories, folders, or maybe tenants). Then you define whether a particular subject has a relationship with an object. A "viewer," "admin," or "editor" would be relationships between a user and a folder object, for example.
With ReBAC, you can answer very complex questions, by traversing this relationship graph that is formed by objects, subjects, and relationships.
Two Approaches to Fine-Grained Access Control
Two ecosystems have emerged around the concept of fine-grained access control:
1. “Policy-as-Code”: In this paradigm, we express policies as a set of rules written in the Rego language. This is the successor to ABAC, where the Open Policy Agent (OPA) project is popular.
OPA is a general-purpose decision engine and it's built for policy-based access management and ABAC. However, it has disadvantages: the language you write policies in, Rego, is a Datalog-derived language that has a high learning curve. It also doesn't help you with modeling application-specific authorization. And because it is truly general purpose, you have to build everything from rudimentary building blocks.
OPA also leaves the difficult problem of getting relevant user and resource data to the decision engine as an exercise for the developer implementing the project. Getting data to the decision engine is crucial because the decision has to take place in milliseconds since it's in the critical path of every application request. And that means that you have to solve this distributed systems problem yourself if you really want to build an authorization system on top of OPA.
All in all, OPA is a really good place to start, but you're going to face some hurdles.
2. “Policy-as-data”: The policy isn't stored as a set of rules, but rather it is ingrained in the data structure. The relationship graph itself is a very opinionated model, so you don't have to design the model yourself. We have "subjects," "objects," and "relationships" which gives you a lot of flexibility.
If your domain model looks like Google Drive, with folders, files, and users, it's a really good place to start. On the other hand, it is still an immature ecosystem, with many competing open-source implementations. It's also difficult to combine it with other authorization models, like RBAC and ABAC.
The Rise of Policy-Based Access Management
Policy-based access management, as the name suggests, lifts the authorization logic out of the application code and into a policy that is its own artifact.
Here’s an example of a policy written in Rego:
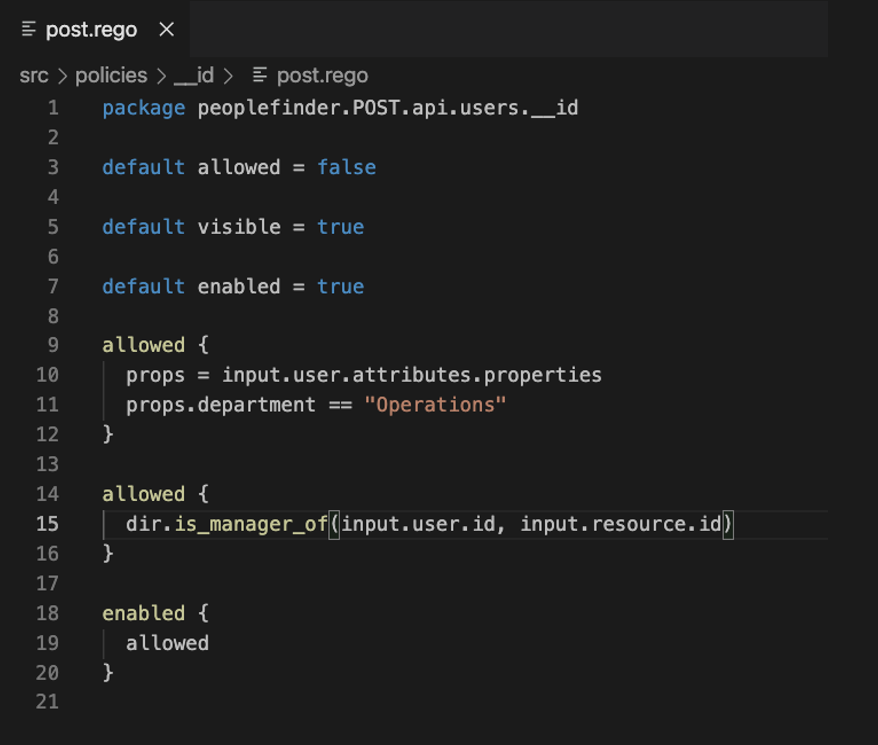
This is really where the principle of least privilege comes into play. You can see that we're denying access, for example, in the allowed clause, until we have enough proof to grant it. The policy is going to return "allowed = false" unless we have some reason to change that to "allowed = true." On line 9, we can see that we're checking that the user's department is "Operations." If it is, this allowed clause will evaluate as true.
Now let's take a quick look at what the application code looks like after we've extracted the authorization logic into the policy:
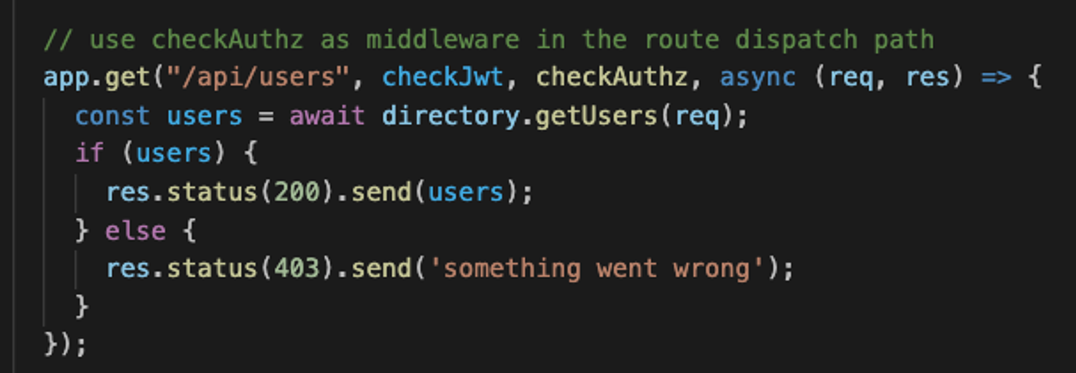
The code snippet above is an express.js endpoint that is responsible for passing the user identity, verified by the check JWT middleware. If the allowed clause from the policy returns true, the middleware will pass the request to the next function, and if not, it will return a 403.
There are many reasons to separate authorization logic from your application code. This lets you have a separate artifact, which can be stored and versioned exactly the same way that we would our application code. Every policy change will be part of a git change log, which provides us with an audit trail for our policy.
Additionally, with the authorization logic separated from the application code, we're adhering to the principle of separation of duties. The security team can manage the authorization policy and the development team can focus on the application. And when we have the policy artifact, we can build it into an immutable image and sign it to maintain a secure supply chain. Here’s a link to the open-source project that does just that: https://github.com/opcr-io/policy.
Real-Time Enforcement Is a Distributed Systems Problem
Real-time access checks are critical for modern authorization. Authorization is a really hard problem to solve because when done correctly it is a distributed systems problem. And distributed system problems are not trivial.
The first challenge is that our authorization service has to authorize locally because it is in the critical path of every single application request. Authorization happens for every request that tries to access a protected resource. Authorization requires 100% availability and milliseconds of latency. For that to happen authorization needs to be performed locally.
We want to authorize locally, but manage our authorization policies and data, globally. We want to make sure the data we are basing our authorization decisions on is fresh and updated across all of our local authorizers. For this we need a control plane that will manage our policies, user directory, and all the resource data, and ensure that every change is distributed to the edge in real-time. We also want to aggregate decision logs from all the local authorizers and stream them to your preferred logging system.
Conclusion
Cloud-native authorization is a complex problem that has yet to be entirely solved. As a result, every cloud application is reinventing the wheel. Based on our conversations, we’ve identified five anti-patterns and best practices for application authorization in the age of cloud computing.
First, you want your authorization to be fine-grained, using any access control pattern that fits best with your application and organization, whether that is RBAC, ABAC, ReBAC, or a combination thereof. Second, you want to separate concerns and extract your access control logic from the application code and into a policy that is handed over to the security team. Third, it is crucial to perform real-time access checks, based on fresh user and resource information. Fourth, you want to manage all of your users, resources, policies, and relationships in one place to increase agility. Lastly, you want to collect and store authorization decision logs for compliance.
Published at DZone with permission of Noa Shavit. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments