The Distributed Data Problem
How to serve your customers’ needs—no matter where they are.
Join the DZone community and get the full member experience.
Join For FreeToday, online retailers sell millions of products and services to customers all around the world. This was more prevalent in 2020, as COVID-19 restrictions all but eliminated visits to brick-and-mortar stores and in-person transactions. Of course, consumers still needed to purchase food, clothing, and other essentials, and, as a result, worldwide digital sales channels rose to the tune of $4.2 trillion, up $900 billion from just a year prior.
Was it enough for those retailers to have robust websites and mobile apps to keep their customers from shopping with competitors? Unfortunately, not. Looking across the eCommerce landscape of 2020, there were clear winners and losers. But what was the deciding factor?
Consider this: 40% of consumers will leave after only three seconds if a web page or mobile app fails to fully load. That’s not a lot of time to make sure that everything renders properly. While there is a lot to be said for properly optimizing images and code, all that work can be for naught if data latency consumes a significant portion of load time.
Co-location Helps — But Can Pose New Challenges
A good way to cut down on data latency is to deploy databases in the same geographic regions as the applications they serve. For example, an enterprise headquartered in San Diego may have applications deployed in data centers located in the Western United States (US), the Eastern US, and Western Europe. The customers who live in those regions are directed to the applications and services closest to them.
But what kind of experience will a customer in London have if the app performs quickly, but then slows? Or worse, what if it stalls when it has to make a data call back to San Diego? This is why co-locating an application with its data is so important.
The concept is deceptively simple. Data needs to be distributed to the regions where it’s needed. Actually, accomplishing that, however, can be challenging. One option would be to deploy our data in a traditional, relational database management system (RDBMS) with one database server in each of the three regions.
But then we have to deal with questions that arise from an operational standpoint. How would we keep the database servers in-sync across all regions? How would we scale them to meet fluctuating traffic demands? Questions like these drive what I call the distributed data problem. And, like any complex problem, addressing the issue often requires specific tools.
The Promise of NoSQL With Horizontal Scaling and Data Center Awareness
This is where non-relational, NoSQL (“not only SQL”) databases come into play. NoSQL databases primarily evolved over the last decade as an alternative to single-instance relational database management systems, or RDBMS, which had trouble keeping up with the throughput demands of web-scale internet traffic. They solve scalability problems through a process known as “horizontal scaling” where multiple server instances of the database are linked to each other to form a “cluster.”
Some of the NoSQL database products were also engineered with data center awareness, meaning the database is configured to logically group together certain instances to optimize the distribution of user data and workloads.
For instance, Apache Cassandra, the open-source NoSQL database that was introduced by Facebook in 2007, is both horizontally scalable and data center aware. If we were to deploy Cassandra to solve this problem, it would look something like the image below.
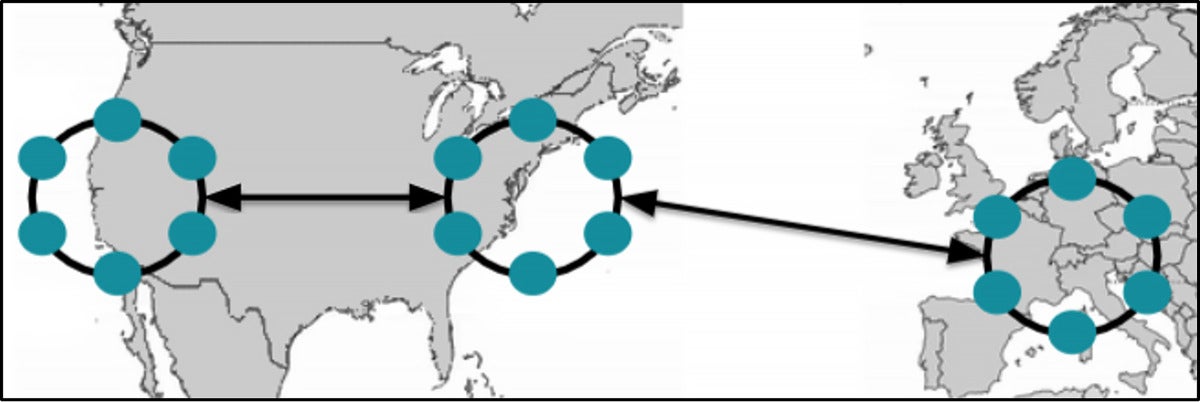
A hypothetical deployment of Apache Cassandra, with one cluster spanning three regional data centers deployed in the Western US, Eastern US, and Western Europe. Map not to scale.
Our hypothetical eCommerce retailer headquartered in San Diego could perform writes on their “local” data center (DC), which would be the Western US DC. That data would then replicate to the other two data centers, in the Eastern US and Western Europe. The applications deployed regionally could then be configured to get data from their local data center.
In this way, all data interactions initiated by the customer would be limited to their own geographic area. This prevents cross-DC, high-latency operations from being noticeable to any end users.
The other advantage to this type of deployment is that the regional data centers can be scaled independently of each other. Perhaps traffic is increasing in Western Europe, requiring additional resources to be added. In this case, new database instances can be added to just that one DC; the resource levels of those that aren’t needed won’t increase—and won’t add unnecessary cost. Once the traffic subsides, the instances in a DC can also be reduced to lower costs.
Of course, scaling a cluster or a DC up and down can require complex infrastructure operations. Deploying databases while using orchestration platforms like Kubernetes can greatly ease that burden, enabling enterprises to worry less about infrastructure and more about new capabilities (To learn more about this topic, check out “A Case for Databases on Kubernetes from a Former Skeptic). Cloud-native, serverless databases like DataStax Astra DB can take that a step further, essentially rendering the underlying infrastructure invisible to application developers.
Two Predictions
I expect that in another 10 years, single-instance databases will become a relic of the past. As that happens, more and more database products will embrace data center awareness.
The trends of horizontal scaling and data center awareness are driving more innovation in database technologies than ever before.
It’s difficult to see when the next big uptick in eCommerce will happen or how widespread the effect will be relative to what we saw in 2020. One thing is certain. Those enterprises that are able to solve the distributed data problem by reducing latency to deliver data more quickly to the apps their customers are using will find themselves well ahead of their competition.
Published at DZone with permission of Aaron Ploetz. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments