The Database CI/CD Best Practice With GitHub
Database change is a tricky part of the development process. Can we treat databases the same way we treat code by making it part of the CI/CD cycle?
Join the DZone community and get the full member experience.
Join For FreeDatabase change is a tricky part of the application development process: it usually involves multiple databases from different environments and cross-team collaboration, to add on top of it, databases are touch and go. It got us thinking: can we treat databases the same way we treat application code?
DORA (DevOps Research & Assessment) pointed out that integrating database work into the software delivery process positively contributes to continuous delivery. It’s about time to make databases a part of the CI/CD cycle.
But how does it work?
Critical Elements of Database CI/CD
To answer the "how", we first need to sort out the typical database change workflow. Before SQL statements can be safely applied to the database, there are two key steps: review & change.
1. SQL Review
This step is to make sure that the changes:
- Implement the business logic accurately;
- Follow database design best practices;
Here, the devs are generally responsible for the former task and the DBAs for the latter. The DevOps philosophy looks to solve this problem by integrating Ops and Devs. The reality is that when DBA exists in an organization, it is difficult to merge the two teams directly. One potential solution is to retain the DBA’s task while enabling dev teams to pre-review the SQL. This shift-left approach can significantly reduce the chance of release delays. Moreover, if there are no DBAs in an organization, then it is even more crucial to empower the dev team with the capability to make sure the SQL doesn’t wreak havoc on the database.
2. SQL Change Execution
This step is to make sure that:
- Statements are executed correctly. We don’t want wrong database connections, insufficient permissions, object name conflicts, or basic syntax errors on our hands.
- All planned statements are executed. Omissions may occur when there are many scripts to be executed or if there are multiple target databases for batch execution.
- The change execution process should not impact the business. Hardware resource exhaustion and locking the table for an extended period are not pleasant for the company.
To avoid change-related errors, reducing the manual aspects is also crucial: the more things are automated, the fewer chances for mistakes to happen. Pre-configured pipelines to automatically apply SQL to the databases? That sounds rad. To avoid affecting regular business operations negatively, various zero-downtime change techniques should be adopted, especially for databases with large datasets.
Thus, the critical elements for implementing Database CI/CD should enable dev teams to perform SQL reviews and streamlined SQL change rollout.
SQL Review and Change Rollout With VCS Integration
Let’s first explore how to enable the dev teams to perform SQL reviews themselves.
Very few developers are experts at reviewing SQL statements for "architecturally correctness," and even for senior DBAs, the manual checks can be highly inefficient and error-prone. Fortunately, the industry has created various automated review tools by integrating different SQL check specifications.
However, these tools have one common problem - they are all designed for the DBAs. On the one hand, these tools often require higher operational privileges to the databases and are thus not suitable to be used directly by developers. On the other hand, developers have their IDE, and a separate external arbitrator is the last thing they need. Imagine how bad it would be when you have to copy & paste code between multiple tools.
So what should a developer-friendly SQL review tool look like?
We usually perform the traditional code review process on version control systems (VCS), and the same should be applied to SQL. Therefore, SQL review tools should be integrated into the code review workflow. Once enabled, the SQL Review Action available on the GitHub Marketplace will be triggered as you submit PR on GitHub.
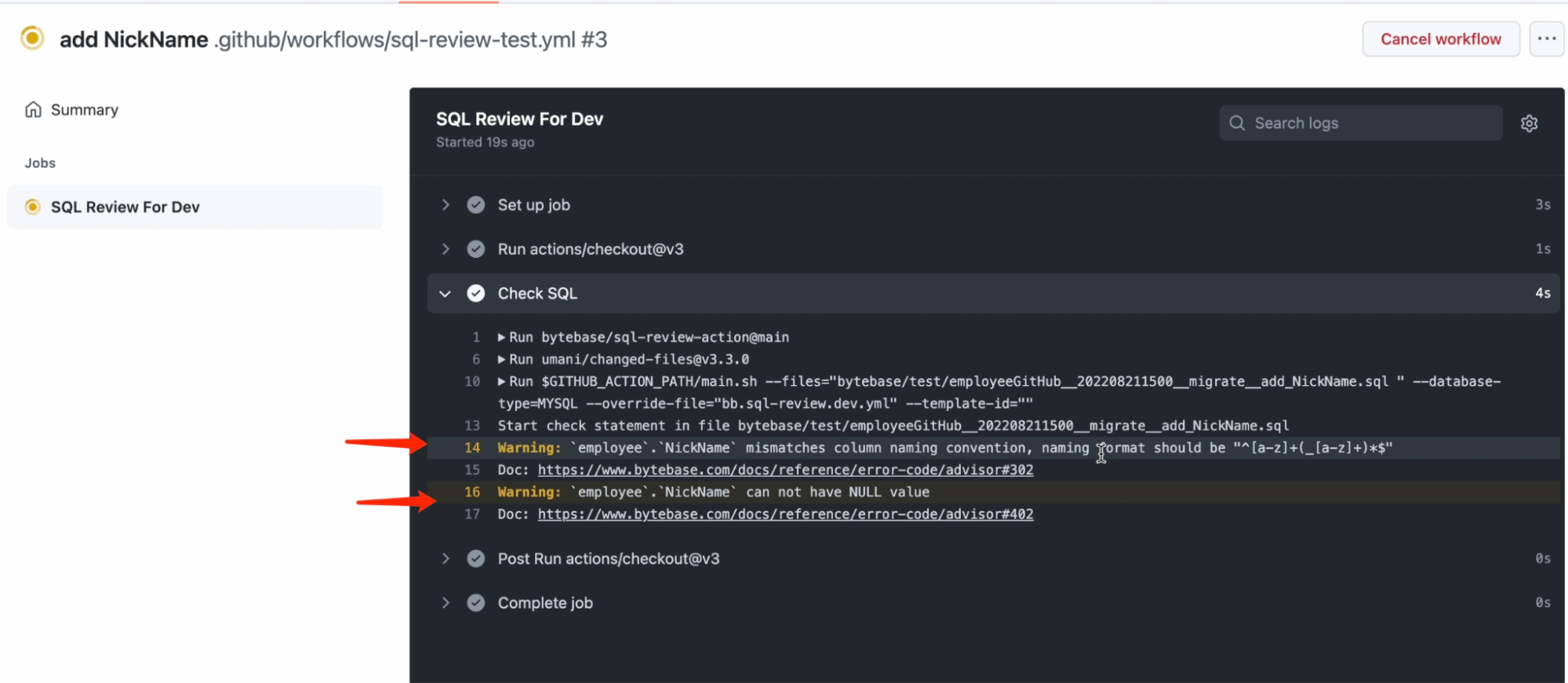
Let’s look at how to implement streamlined SQL change rollouts.
Standalone SQL deployment tools are not uncommon. These tools typically upload SQL scripts manually, proceed with the deployment via an approval flow, and then provide feedback after the rollout is complete. This model accurately depicts how the developers and the DBAs work independently, and the fragmented process is one of the most common reasons for delayed releases. After all, who can guarantee that there will never be a mistake when you are constantly moving SQL scripts between multiple systems manually?
We need a more efficient and automated release process. Let’s recall the classic CI/CD workflow for application code: commit changes > code review > merge branch > auto-build > auto-deploy. Since we’ve already implemented SQL review on GitHub Actions, why can’t we include the subsequent rollout process?
Well, yes, we can!
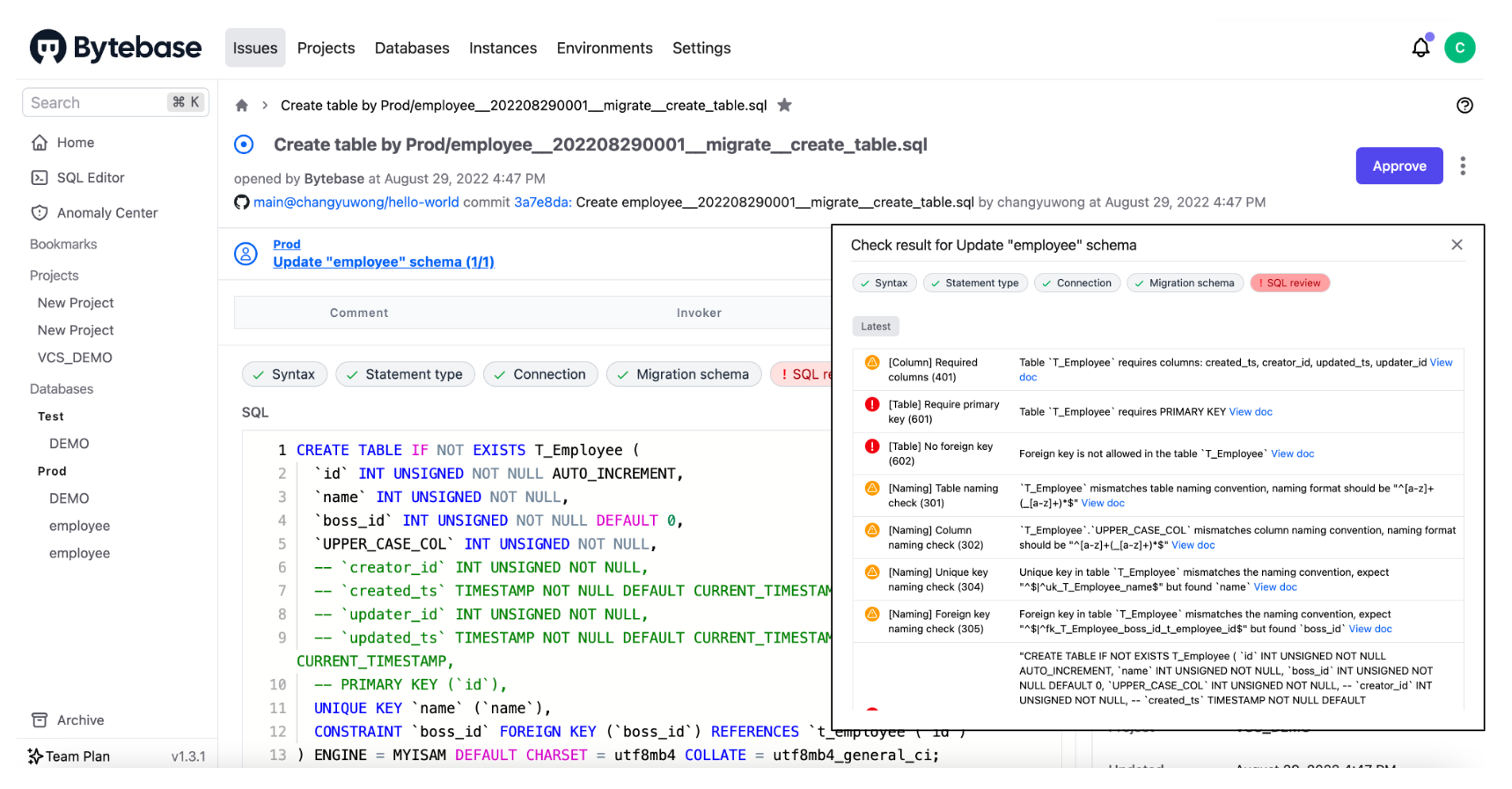
A SQL change rollout tool for Database CI/CD should have the ability to integrate with VCS. Once your SQL scripts have been vetted and merged into the target branch, the release process is triggered, and the scripts are automatically pushed to Bytebase. Of course, the DBA can perform another sanity check before executing the SQL against the target database.
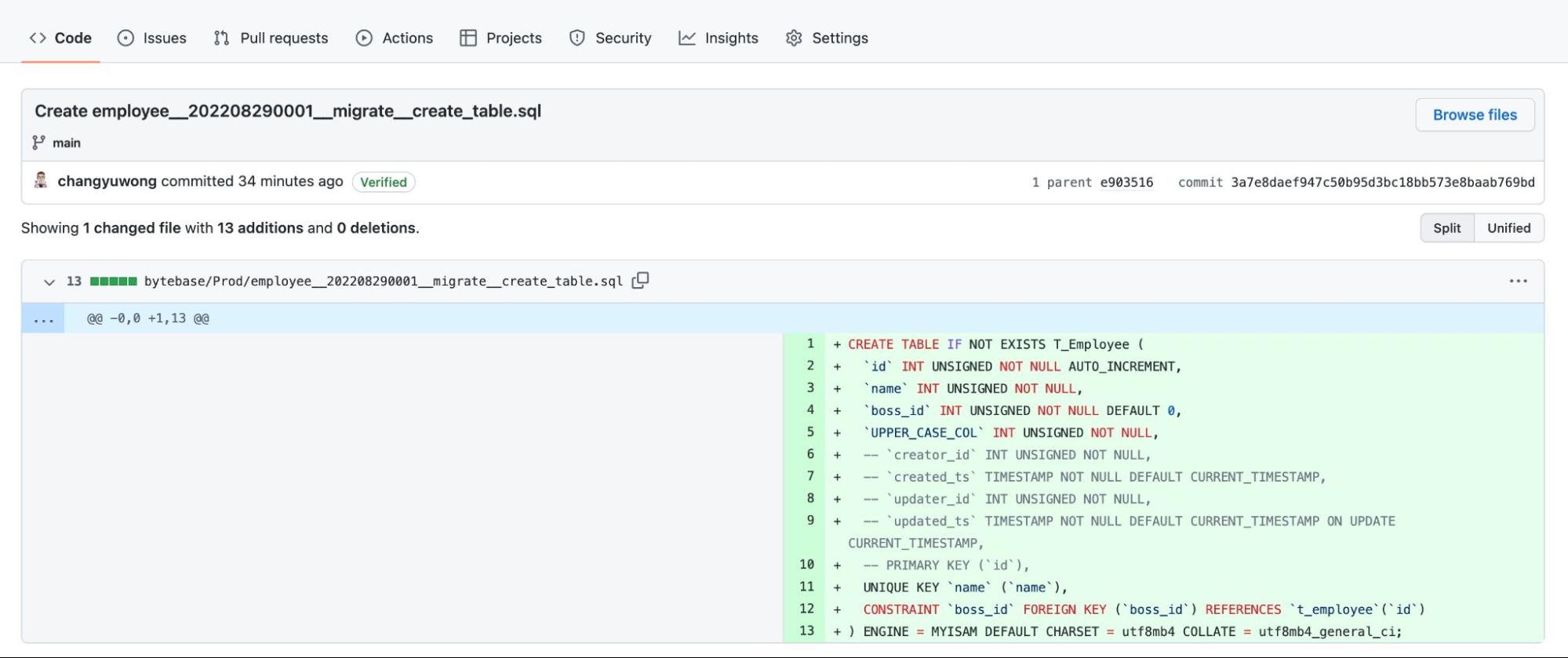
A Complete Database CI/CD Workflow
Here, we present a complete Database CI/CD workflow:
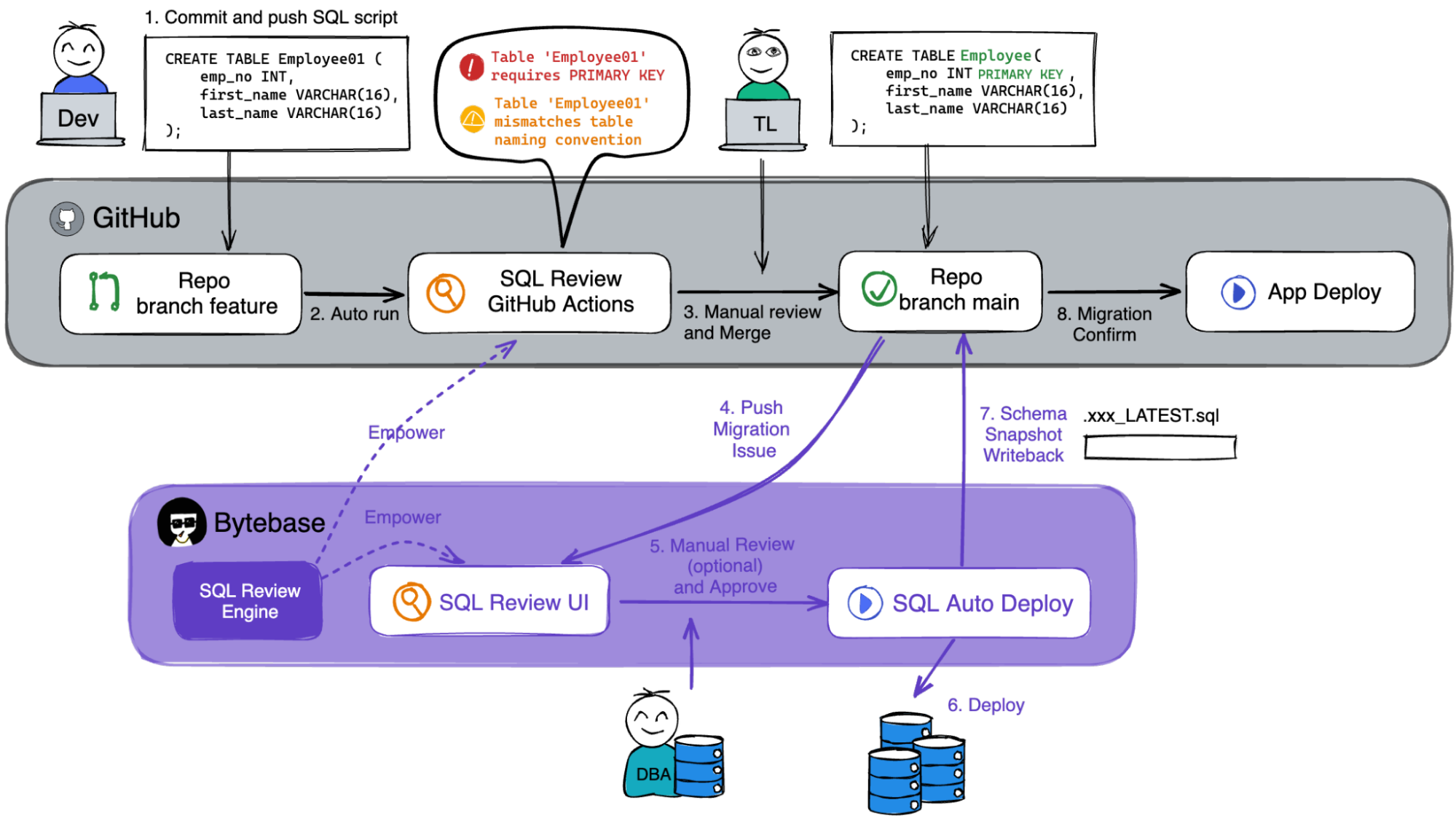
- The developer creates a Merge Request / Pull Request containing the SQL migration script;
- SQL Review Action is automatically triggered to review SQL and offers suggestions to assist the code review;
- After several possible iterations, the team leader or another peer on the dev teams approves the change and merges the SQL script into a branch;
- The merge event automatically triggers the release pipeline in Bytebase and creates a release ticket capturing the intended change;
- (Optional) A DBA or a designated reviewer may review the change scripts via Bytebase’s built-in UI;
- Approved scripts are executed gradually according to the configured rollout stages;
- The latest database schema is automatically written back to the code repository after applying changes. With this, the Dev team always has a copy of the latest schema. Furthermore, they can configure downstream pipelines based on the change of that latest schema;
- Confirm the migration and proceed to the corresponding application rollout.
This workflow fits in nicely with the existing CI/CD process and is natural to the Developers. Acute readers may have already spotted the described steps are an implementation of the landmark article Evolutionary Database Design.
Published at DZone with permission of Cayden Wang. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments