Programming Models for Servers in Java
Learn more about various programming models for servers in Java!
Join the DZone community and get the full member experience.
Join For Free
Very often, our applications don't need to handle thousands of users in parallel or process hundreds of thousands of messages in one second. We just need to cope with tens or hundreds of concurrently connected users, let's say in our internal application or some microservice application that's not supposed to be under such a big load.
In this case, we can use some high-level frameworks/libraries that are not as optimized in terms of the threading model/used memory, and still, we can withstand that load with some reasonable resources and pretty quick delivery time.
However, from time to time, we encounter situations where a piece of our system needs to be scaled better than the rest of the applications. Writing this part of our system by the traditional way or frameworks could lead to huge resource consumption, and a lot of instances of the same service would need to be started to handle the load. The algorithms and approaches that lead to the ability to handle tens of thousands of connections are also called the C10K problem.
In this article, I'm going to focus mainly on optimizations that can be done in terms of TCP Connections/Traffic to tune your (micro)service instance to waste as few resources as possible, go deeper into how the OS works with TCP and Sockets, and, last but not least, how to gain an insight into all of these things. Let's get started.
I/O Programming Strategies
Let's describes what kind of I/O programming models we currently have and from what options we need to choose when we design our application. First of all, there is no Good or Bad approach, just approaches that fit better into our current use case. Choosing the wrong approach can have very inconvenient consequences in the future. It can result in wasted resources or even re-writing your application from scratch.
Blocking I/O With Blocking Processing
Thread-per-Connection Server
The idea behind this approach is that the Socket Connection is not accepted (we will show later what does it mean) without any dedicated/free thread. Blocking, in this case, means that the particular thread is tied to the connection and blocks always when it reads from, or writes to, the connection.
public static void main(String[] args) throws IOException {
try (ServerSocket serverSocket = new ServerSocket(5050)) {
while (true) {
Socket clientSocket = serverSocket.accept();
var dis = new DataInputStream(clientSocket.getInputStream());
var dos = new DataOutputStream(clientSocket.getOutputStream());
new Thread(new ClientHandler(dis, dos)).start();
}
}
}The simplest version of a Socket Server that starts on a port 5050 and reads from InputStream and writes to OutputStream in a blocking way. Useful when we need to transfer a small number of objects via a single connection then close it start a new when whenever it's needed.
It can be implemented even without any high-level library.
Reading/writing using blocking streams (waiting on blocking
InputStreamread operation that fills a provided byte array by bytes that are available in TCP Receive Buffer at that time and returns the number of bytes or -1 - the end of the stream) and consuming bytes until we have enough data to construct a request.A big problem and inefficiency can come when we start creating threads for incoming connections unbounded way. We will pay a price for very expensive thread creation and memory impact that comes hand in hand with mapping one Java Thread to one Kernel Thread.
It's not suitable for "real" production unless we really need an application with a low-memory footprint and don't want to load a lot of classes belonging to some frameworks.
Non-Blocking I/O With Blocking Processing
Thread-Pool Based Servers
This is a category that the majority of well-known enterprise HTTP Servers belong to. In general, this model uses several Thread-Pools to make processing more efficient in the multi-CPUs environment and more suitable for enterprise applications. There are several ways how thread-pools can be configured but the basic idea is absolutely the same in all HTTP servers. Please, see HTTP Grizzly I/O Strategies for all possible strategies that can be usually configured in terms of Thread-Pool based non-blocking servers.
The first thread-pool for accepting new connections. It can be even a single-threaded pool if one thread is able to manage the speed of incoming connections. There are usually two backlogs that can be filled up and next incoming connections rejected. Check if you properly use persistent connections if it's possible.

The second thread pool for reading/writing from/to the socket by the non-blocking way (selector threads or IO threads). Every selector thread handles multiple clients (channels).
The third thread pool that separates the non-blocking and blocking parts of the request processing (usually called worker threads). The Selector thread cannot be blocked by some blocking operation because all other channels wouldn't be able to make any progress (there is only one thread for the group of channels and this thread would be blocked).
Non-blocking reading/writing is implemented using buffers, selector threads read new bytes from the socket and write into dedicated buffers (pooled buffers) as long as particular threads handling the request are not satisfied (because they don't have enough data to construct e.g. HTTP request).
We need to clarify the term NON-BLOCKING:
If we talk in the context of Socket Servers, then non-blocking means that threads are not tied to opened connections and don't wait for incoming data (or even writing data if TCP Send Buffers are full), just try to read and if there are no bytes then no bytes are added into buffers for further processing (constructing the request) and the given selector thread proceeds with reading from another opened connection.
However, in terms of processing the request, the code is in most cases BLOCKING, which means that we execute some piece of code that blocks the current thread and this thread waits for completion of I/O-bound processing (database query, HTTP invocation, reading from disk, ..) or some long-lasting CPU-bound processing (computing hashes/factorial, crypto mining, ..). If the execution is completed then the thread is woken up and proceeds in some business logic.
The BLOCKING nature of our business logic is the main reason why worker-pools are so huge, we just need to get plenty of threads into play to increase throughput. Otherwise, in case of higher load (e.g. more HTTP Requests), we could end up with all threads in blocked state and with no available thread for request processing (there are no threads in Runnable State to be ready for an execution on CPU).
Advantages
Even if the number of requests is pretty high and a lot of our worker threads are blocked on some blocking operation, we are able to accept new connections, even if we are probably not able to handle their request immediately and data must wait in TCP Receive Buffers.
This programming model is used by many frameworks/libraries (Spring Controllers, Jersey, ..) and HTTP Servers (Jetty, Tomcat, Grizzly ..) under the hood because it's very easy to write business code and let the threads block if it's really needed.
Disadvantages
Parallelism is not usually determined by the number of CPUs but is very limited by the nature of blocking operations and the number of worker threads. In general, it means that if the time ratio of a blocking operation (I/O) and further execution (during the request process) is too high, then we can end up with:
A lot of blocked threads on a blocking operation (database query, ..) and
A lot of request waiting for a worker thread to be processed and
CPU that is very unutilized because of no thread can proceed further in its execution
Bigger thread pools lead to context-switching and inefficient use of CPU caches
How to Set Up Your Thread Pools
Ok, we have one or multiple Thread-pools for handling blocking business operations. However, what is the optimal size of the thread-pool? We can encounter two problems:
The thread-pool is too small and we don't have enough threads to cover the time when all threads are blocked, let's say waiting for I/O operations, and your CPUs are not effectively used.
The thread-pool is too big and we pay a price for a lot of threads that are actually idle (see below what is the price when we run a lot of threads).
I would refer to a great book Java Concurrency in Practice from Brian Goetz that says that sizing thread pools is not the exact science, it's more about understanding your environment and the nature of your tasks.
How many CPUs and how much memory your environment have?
Do tasks perform mostly computation, I/O, or some combination?
Do they require a scarce resource (JDBC connection)? Thread pool and connection pool would influence each other and probably does not make sense to increase the thread pool to get better throughput when we fully utilize the connection pool.
If our program contains I/O or other blocking operations, you need a larger pool because your threads are not allowed to be placed on CPU all the time. You need to estimate the ratio of waiting time to compute time for your tasks using some profilers or benchmarks and observe CPU utilization in different phases of your production workload (peak time vs. off-peak).

Non-Blocking I/O With Non-Blocking Processing
Servers Based on the Same Number of Threads as CPU Cores
This strategy is the most efficient if we are able to manage the majority of our workload in a non-blocking way. That means that handling our socket (accepting connections, reading, writing) is implemented using a non-blocking algorithm but even business processing does not contain any blocking operations.
The typical representative for this strategy is Netty Framework, therefore let's dive into the architectural basics of how this framework is implemented to be able to see why it's the best fit for solving the C10K problem. If you want to dive into details how it really works then I can recommend the resources below:
Netty in Action - written by the author of Netty Framework Norman Mauer. It's a great resource to get know how to implement clients or servers based on Netty using handlers with various protocols.
User Guide for 4.x - a sample application in Netty that shows all basic principles.
I/O Library With an Asynchronous Programming Model
Netty is an I/O library and framework that simplified non-blocking IO programming and provide an asynchronous programming model for events that will happen during the lifecycle of the server and incoming connections. We just need to hook up to the callbacks with our lambdas and we get everything for free.
A lot of protocols are ready to use without having a dependency on some huge library
It's very discouraging to start building an application with pure JDK NIO but Netty contains features that keep programmers on a lower level and provide a possibility to make a lot of things much more efficient. Netty already contains the majority of well-known protocols which means we can work with them much more efficiently than in higher-level libraries (e.g. Jersey/Spring MVC for HTTP/REST) with a lot of boilerplate.
Identify the right non-blocking use-cases to fully utilize the power of Netty
I/O processing, protocol's implementation, and all other handlers are supposed to use non-blocking operations to never stop the current thread. We can always use an additional thread pool for blocking operations. However, if we need to switch processing of our every request to the dedicated thread pool for blocking operations then we barely utilize the power of Netty because we very likely end up in the same situation as with Non-Blocking IO with Blocking Processing - one big thread-pool just in a different part of our application.
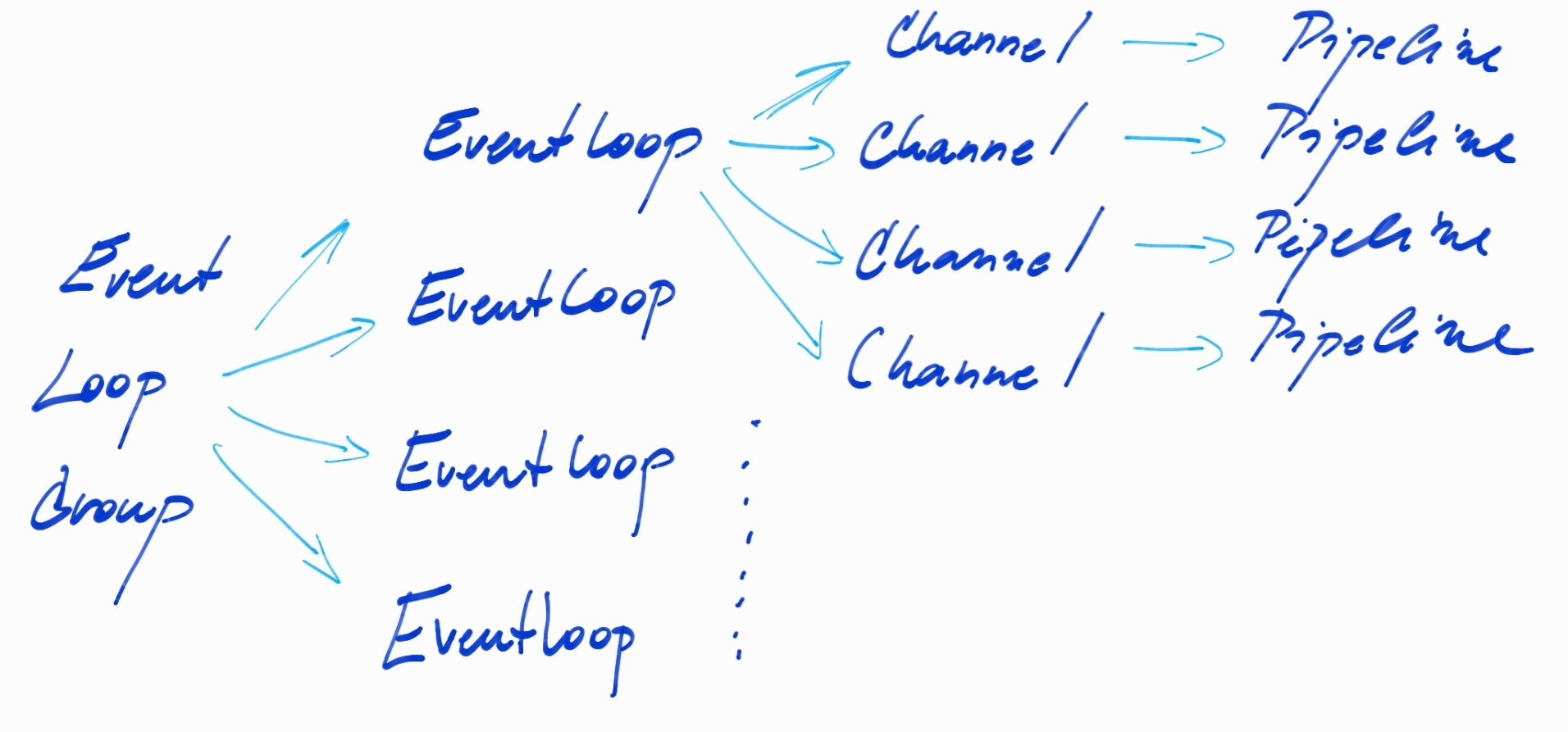
On the picture above, we can see the main components that are parts of Netty Architecture
EventLoopGroup — gathers event loops and provides channels to be registered to one of the event loops.
EventLoop — handles all I/O operations for the registered Channels for the given event loop. EventLoop runs only on one thread. Therefore, the optimal number of event loops for one
EventLoopGroupis the number of CPUs (some frameworks use a number of CPUs + 1 to have additional thread when Page Fault occurs).Pipeline —keeps an execution order of handlers (components that are ordered and executed when some input or output event occurs, contains the actual business logic). Pipeline and handlers are executed on the thread belonging to
EventLoop, therefore, the blocking operation in handlers blocks all other processing/channels on the givenEventLoop.
Summary
Thank you for reading my article and please leave comments below. If you would like to be notified about new posts, then start following me on Twitter!
Further Reading
Opinions expressed by DZone contributors are their own.
Comments