Telemetry Pipelines Workshop: Parsing Multiple Events
As this workshop series about cloud-native observability continues, learn how to build a telemetry pipeline for parsing multiple events with Fluent Bit.
Join the DZone community and get the full member experience.
Join For FreeThis article is part of a series exploring a workshop guiding you through the open source project Fluent Bit, what it is, a basic installation, and setting up the first telemetry pipeline project. Learn how to manage your cloud-native data from source to destination using the telemetry pipeline phases covering collection, aggregation, transformation, and forwarding from any source to any destination.
The previous article in this series saw us building our first telemetry pipelines with Fluent Bit. In this article, we continue onwards with some more specific use cases that pipelines solve. You can find more details in the accompanying workshop lab.
Let's get started with this use case.
Before we get started it's important to review the phases of a telemetry pipeline. In the diagram below we see them laid out again. Each incoming event goes from input to parser to filter to buffer to routing before they are sent to their final output destination(s).
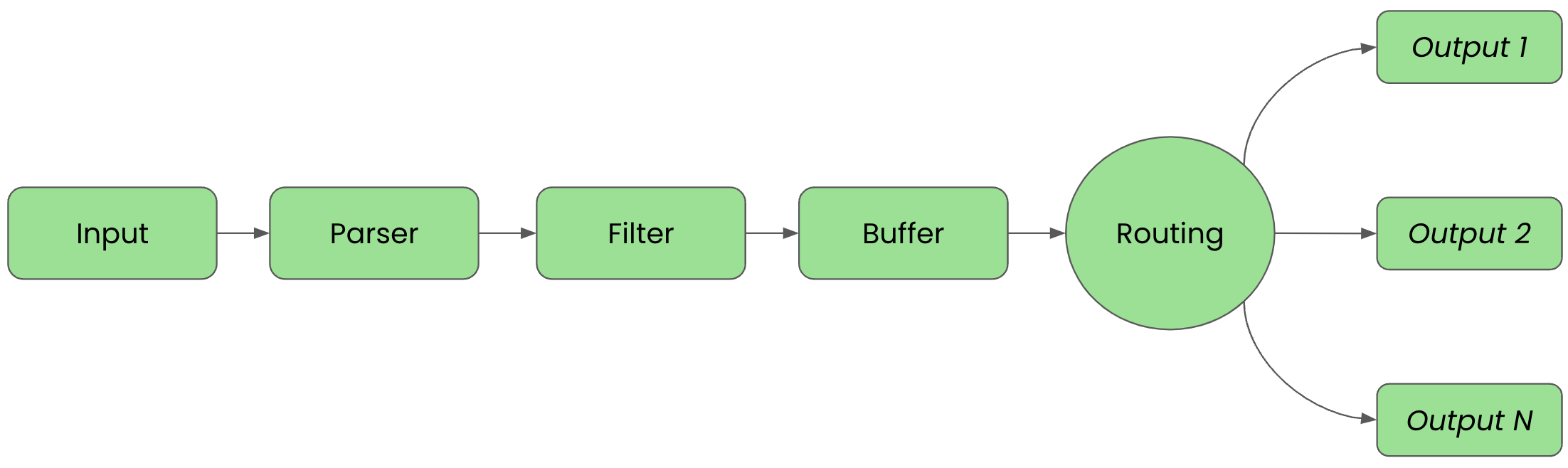 For clarity in this article, we'll split up the configuration into files that are imported into a main fluent bit configuration file that we'll name workshop-fb.conf.
For clarity in this article, we'll split up the configuration into files that are imported into a main fluent bit configuration file that we'll name workshop-fb.conf.
Parsing Multiple Events
One of the more common use cases for telemetry pipelines is having multiple event streams producing data that creates the situation that keys are not unique if parsed without some cleanup. Let's illustrate how Fluent Bit can easily provide us with a means to both parse and filter events from multiple input sources to clean up any duplicate keys before sending onward to a destination.
To provide an example, we start with an inputs.conf file containing a configuration using the dummy plugin to generate two types of events, both using the same key to cause confusion if we try querying without cleaning them up first:
# This entry generates a success message.
[INPUT]
Name dummy
Tag event.success
Dummy {"message":"true 200 success"}
# This entry generates an error message.
[INPUT]
Name dummy
Tag event.error
Dummy {"message":"false 500 error"}
Our configuration is tagging each successful event with event.success and failure events with event.error. The confusion will be caused by configuring the dummy message with the same key, message, for both event definitions. This will cause our incoming events to be confusing to deal with.
The file called outputs.conf contains but one destination as shown in the following configuration:
# This entry directs all tags (it matches any we encounter)
# to print to standard output, which is our console.
#
[OUTPUT]
Name stdout
Match *
With our inputs and outputs configured, we can now bring them together in a single main configuration file we mentioned at the start. Let's create a new file called workshop-fb.conf in our favorite editor. Add the following configuration; for now, just importing our other two files:
# Fluent Bit main configuration file. # # Imports section, assumes these files are in the same # directory as the main configuration file. # @INCLUDE inputs.conf @INCLUDE outputs.conf
To see if our configuration works, we can test run it with our Fluent Bit installation. Depending on the chosen install method used from the previous articles in this series, we have the option to run it from source, or using container images. First, we show how to run it using the source install execution from the directory we created to hold all our configuration files:
# source install. # $ [PATH_TO]/fluent-bit --config=workshop-fb.conf
The console output should look something like this - noting that we've cut out the ASCII logo at startup:
...
[2024/04/05 16:49:33] [ info] [input:dummy:dummy.0] initializing
[2024/04/05 16:49:33] [ info] [input:dummy:dummy.0] storage_strategy='memory' (memory only)
[2024/04/05 16:49:33] [ info] [input:dummy:dummy.1] initializing
[2024/04/05 16:49:33] [ info] [input:dummy:dummy.1] storage_strategy='memory' (memory only)
[2024/04/05 16:49:33] [ info] [output:stdout:stdout.0] worker #0 started
[2024/04/05 16:49:33] [ info] [sp] stream processor started
[0] event.success: [[1712328574.915990000, {}], {"message"=>"true 200 success"}]
[0] event.error: [[1712328574.917728000, {}], {"message"=>"false 500 error"}]
[0] event.success: [[1712328575.915732000, {}], {"message"=>"true 200 success"}]
[0] event.error: [[1712328575.916608000, {}], {"message"=>"false 500 error"}]
[0] event.success: [[1712328576.915161000, {}], {"message"=>"true 200 success"}]
[0] event.error: [[1712328576.915288000, {}], {"message"=>"false 500 error"}]
...
Also note the alternating generated event lines with messages that are hard to separate when using the same key. These events alternate in the console until exiting with CTRL_C.
Next, we show how to run our telemetry pipeline configuration using a container image. First thing that is needed is a file called Buildfile. This is going to be used to build a new container image and insert our configuration files. Note this file needs to be in the same directory as your configuration files; otherwise, adjust the file path names:
FROM cr.fluentbit.io/fluent/fluent-bit:3.0.1 COPY ./workshop-fb.conf /fluent-bit/etc/fluent-bit.conf COPY ./inputs.conf /fluent-bit/etc/inputs.conf COPY ./outputs.conf /fluent-bit/etc/outputs.conf
Now we'll build a new container image as follows using the Buildfile, naming it with a version tag, and assuming you are in the same directory (using Podman as discussed in previous articles):
$ podman build -t workshop-fb:v4 -f Buildfile STEP 1/4: FROM cr.fluentbit.io/fluent/fluent-bit:3.0.1 STEP 2/4: COPY ./workshop-fb.conf /fluent-bit/etc/fluent-bit.conf --> a379e7611210 STEP 3/4: COPY ./inputs.conf /fluent-bit/etc/inputs.conf --> f39b10d3d6d0 STEP 4/4: COPY ./outputs.conf /fluent-bit/etc/outputs.conf COMMIT workshop-fb:v4 --> b06df84452b6 Successfully tagged localhost/workshop-fb:v4 b06df84452b6eb7a040b75a1cc4088c0739a6a4e2a8bbc2007608529576ebeba
Now, to run our new container image:
$ podman run workshop-fb:v4
The output looks exactly like the source output above, just with different timestamps. Again you can stop the container using CTRL_C.
Now we have dirty ingested data coming into our pipeline, showing that we have multiple messages on the same key. To be able to clean this up for usage before passing on to the backend (output), we need to make use of both the Parser and Filter phases.
First, in the Parser phase, where unstructured data is converted into structured data, we'll make use of the built in REGEX parser plugin to structure the duplicate messages into something more usable. For clarity, this is where we are working in our telemetry pipeline:
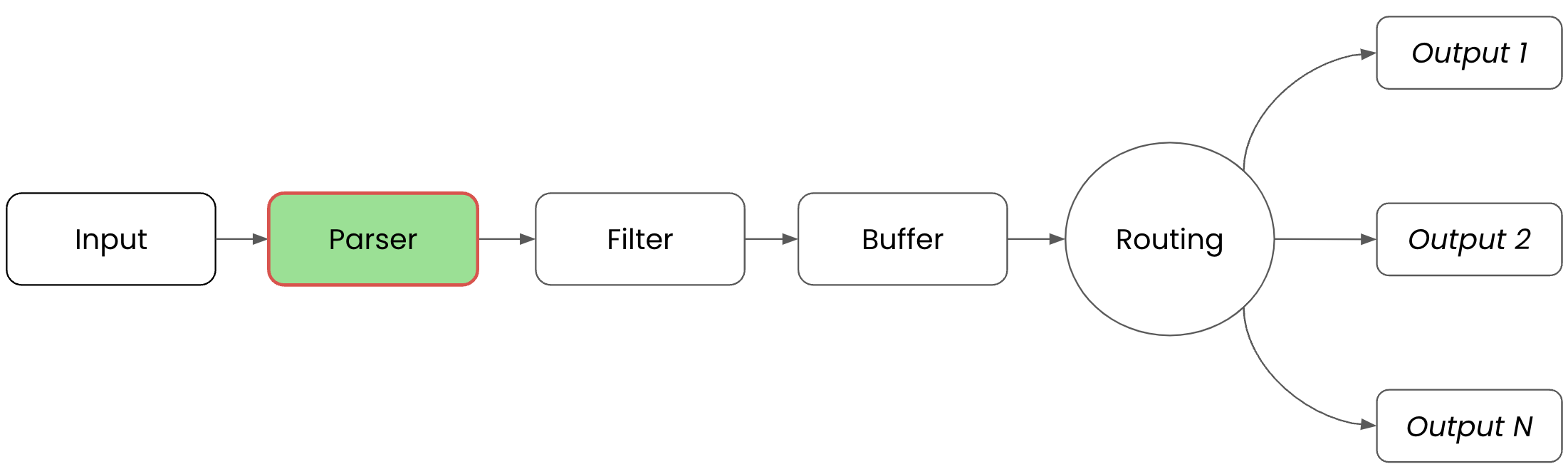
To set up the parser configuration, we create a new file called parsers.conf in our favorite editor. Add the following configuration, where we are defining a PARSER, naming the parser message_cleaning_parser, selecting the built-in regex parser, and applying the regular expression shown here to convert each message into a structured format (note this actually is applied to incoming messages in the next phase of the telemetry pipeline):
# This parser uses the built-in parser plugin and applies the
# regex to all incoming events.
#
[PARSER]
Name message_cleaning_parser
Format regex
Regex ^(?<valid_message>[^ ]+) (?<code>[^ ]+) (?<type>[^ ]+)$
Next up is the Filter phase where we will apply the parser. For clarity, the following visual is provided:
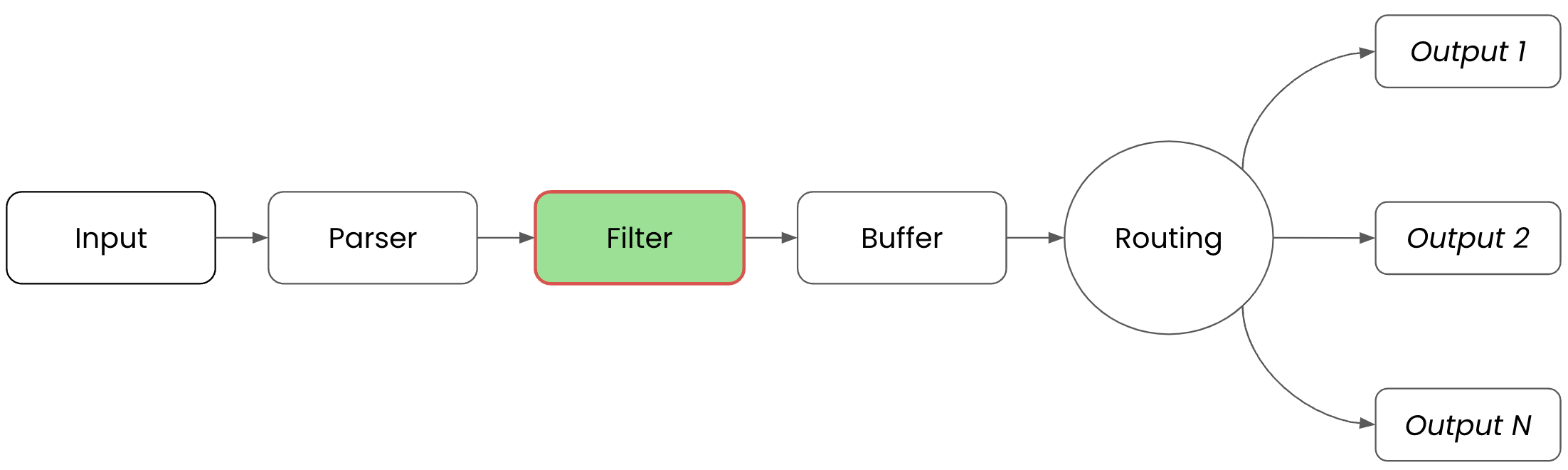
In the Filter phase, the previously defined parser is put to the test. To set up the filter configuration we create a new file called filters.conf in our favorite editor. Add the following configuration where we are defining a FILTER, naming the filter message_parser, matching all incoming messages to apply this filter, looking for the key message to select the value to be fed into the parser, and applying the parser message_cleaning_parser to it:
# This filter is applied to all events and uses the named parser to
# apply values found with the chosen key if it exists.
#
[FILTER]
Name parser
Match *
Key_Name message
Parser message_cleaning_parser
To make sure the new filter and parser are included, we update our main configuration file workshop-fb.conf as follows:
# Fluent Bit main configuration file. [SERVICE] parsers_file parsers.conf # Imports section. @INCLUDE inputs.conf @INCLUDE outputs.conf @INCLUDE filters.conf
To verify that our configuration works we can test run it with our Fluent Bit installation. Depending on the chosen install method, here we show how to run it using the source installation followed by the container version. Below, the source install is shown from the directory we created to hold all our configuration files:
# source install. # $ [PATH_TO]/fluent-bit --config=workshop-fb.conf
The console output should look something like this - noting that we've cut out the ASCII logo at startup:
...
[2024/04/09 16:19:42] [ info] [input:dummy:dummy.0] initializing
[2024/04/09 16:19:42] [ info] [input:dummy:dummy.0] storage_strategy='memory' (memory only)
[2024/04/09 16:19:42] [ info] [input:dummy:dummy.1] initializing
[2024/04/09 16:19:42] [ info] [input:dummy:dummy.1] storage_strategy='memory' (memory only)
[2024/04/09 16:19:42] [ info] [output:stdout:stdout.0] worker #0 started
[2024/04/09 16:19:42] [ info] [sp] stream processor started
[0] event.success: [[1712672383.962198000, {}], {"valid_message"=>"true", "code"=>"200", "type"=>"success"}]
[0] event.error: [[1712672383.964528000, {}], {"valid_message"=>"false", "code"=>"500", "type"=>"error"}]
[0] event.success: [[1712672384.961942000, {}], {"valid_message"=>"true", "code"=>"200", "type"=>"success"}]
[0] event.error: [[1712672384.962105000, {}], {"valid_message"=>"false", "code"=>"500", "type"=>"error"}]
...
Be sure to scroll to the right in the above window to see the full console output. Note the alternating generated event lines with parsed messages that now contain keys to simplify later querying. This runs until exiting with CTRL_C.
Let's now try testing our configuration by running it using a container image. The first thing that is needed is to open in our favorite editor the file Buildfile. This is going to be expanded to include the filters and parsers configuration files. Note this file needs to be in the same directory as our configuration files; otherwise, adjust the file path names:
FROM cr.fluentbit.io/fluent/fluent-bit:3.0.1 COPY ./workshop-fb.conf /fluent-bit/etc/fluent-bit.conf COPY ./inputs.conf /fluent-bit/etc/inputs.conf COPY ./outputs.conf /fluent-bit/etc/outputs.conf COPY ./filters.conf /fluent-bit/etc/filters.conf COPY ./parsers.conf /fluent-bit/etc/parsers.conf
Now we'll build a new container image, naming it with a version tag as follows using the Buildfile and assuming you are in the same directory (using Podman as discussed in previous articles):
$ podman build -t workshop-fb:v4 -f Buildfile STEP 1/6: FROM cr.fluentbit.io/fluent/fluent-bit:3.0.1 STEP 2/6: COPY ./workshop-fb.conf /fluent-bit/etc/fluent-bit.conf --> 7eee3091e091 STEP 3/6: COPY ./inputs.conf /fluent-bit/etc/inputs.conf --> 53ff32210b0e STEP 4/6: COPY ./outputs.conf /fluent-bit/etc/outputs.conf --> 62168aa0c600 STEP 5/6: COPY ./filters.conf /fluent-bit/etc/filters.conf --> 08f0878ded1e STEP 6/6: COPY ./parsers.conf /fluent-bit/etc/parsers.conf COMMIT workshop-fb:v4 --> 92825169e230 Successfully tagged localhost/workshop-fb:v4 92825169e230a0cc36764d6190ee67319b6f4dfc56d2954d267dc89dab8939bd
Now to run our new container image:
$ podman run workshop-fb:v4
The output looks exactly like the source output above, noting that the alternating generated event lines with parsed messages now contain keys to simplify later querying.
This completes our use cases for this article, be sure to explore this hands-on experience with the accompanying workshop lab.
What's Next?
This article walked us through a telemetry pipeline use case for multiple events using parsing and filtering. The series continues with the next step where we'll explore how to collect metrics using a telemetry pipeline.
Stay tuned for more hands on material to help you with your cloud native observability journey.
Opinions expressed by DZone contributors are their own.
Comments