TBMQ: Open-Source MQTT Broker
Explore and leverage TBMQ: a scalable, fault-tolerant, and efficient MQTT broker free for commercial use and developed by ThingsBoard.
Join the DZone community and get the full member experience.
Join For FreeTBMQ is an open-source MQTT broker that is designed with great care to implement the following attributes:
- Scalability: it is a horizontally scalable platform constructed using cutting-edge open-source technologies;
- Fault tolerance: no single point of failure; each broker (node) within the cluster is identical in terms of functionality;
- Robustness and efficiency: can manage millions of clients and process millions of messages per second;
- Durability: provides high message durability, ensuring that data is never lost.
![TBMQ Node]() Motivation
Motivation
 Motivation
MotivationAt ThingsBoard, we've gained a lot of experience in building scalable IoT applications, which has helped us identify two main scenarios for MQTT-based solutions. In the first scenario, numerous devices generate a large volume of messages that are consumed by specific applications, resulting in a fan-in pattern. Normally, a few applications are set up to handle these lots of incoming data. They must be persistent clients with a Quality of Service (QoS) level set to 1 or 2, capable of retaining all the data even when they're temporarily offline due to restarts or upgrades. This ensures applications don't miss any single message. On the other hand, the second scenario involves numerous devices subscribing to specific updates or notifications that must be delivered. This leads to a few incoming requests that cause a high volume of outgoing data. This case is known as a fan-out pattern. Acknowledging these scenarios, we intentionally designed TBMQ to be exceptionally well-suited for both.
Our design principles focused on ensuring the broker’s fault tolerance and high availability. Thus, we deliberately avoided reliance on master or coordinated processes. We ensured the same functionality across all nodes within the cluster.
We prioritized supporting distributed processing, allowing for effortless horizontal scalability as our operations grow. We wanted our broker to support high-throughput and guarantee low-latency delivery of messages to clients. Ensuring data durability and replication was crucial in our design. We aimed for a system where once the broker acknowledges receiving a message, it remains safe and won’t be lost.
To ensure the fulfillment of the above requirements and prevent message loss in the case of clients or some of the broker instances failures, TBMQ uses the powerful capabilities of Kafka as its underlying infrastructure.
How Does TBMQ Work in a Nutshell?
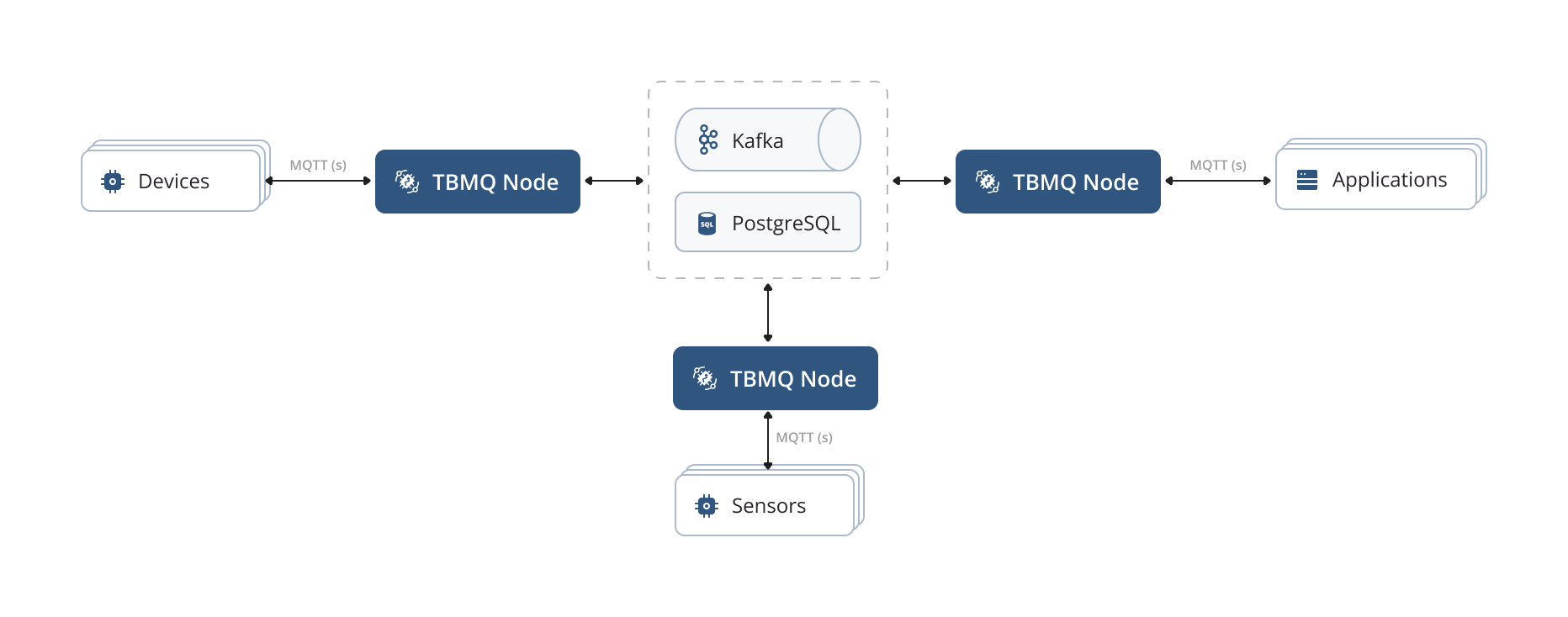
Kafka plays a crucial role in various stages of the MQTT message processing. All unprocessed published messages, client sessions, and subscriptions are stored within dedicated Kafka topics. A comprehensive list of Kafka topics used within TBMQ is available here. All broker nodes can readily access the most up-to-date status of client sessions and subscriptions by utilizing these topics. They maintain local copies of sessions and subscriptions for efficient message processing and delivery. When a client loses connection to a specific broker node, other nodes can seamlessly continue operations based on the latest state. Additionally, newly added broker nodes to the cluster get this vital information upon their activation.
Client subscriptions hold significant importance within the MQTT publish/subscribe pattern. TBMQ employs the Trie data structure to optimize performance, enabling efficient persistence of client subscriptions in memory and facilitating swift access to relevant topic patterns.
Upon a publisher client sending a PUBLISH message, it is stored in the initial Kafka topic, tbmq.msg.all. Once Kafka acknowledges the message’s persistence, the broker promptly responds to the publisher with either a PUBACK/PUBREC message or no response at all, depending on the chosen QoS level.
Subsequently, separate threads, functioning as Kafka consumers, retrieve messages from the mentioned Kafka topic and utilize the Subscription Trie data structure to identify the intended recipients. Depending on the client type (DEVICE or APPLICATION) and the persistence options described below, the broker either redirects the message to another specific Kafka topic or directly delivers it to the recipient.
Non-Persistent Client
A client is classified as a non-persistent one when the following conditions are met in the CONNECT packet:
For MQTT v3.x:
clean_sessionflag is set to true.
For MQTT v5:
clean_startflag is set to true andsessionExpiryIntervalis set to 0 or not specified.
In the case of non-persistent clients, all messages intended for them are published directly without undergoing additional persistence. It is important to note that non-persistent clients can only be of type Device.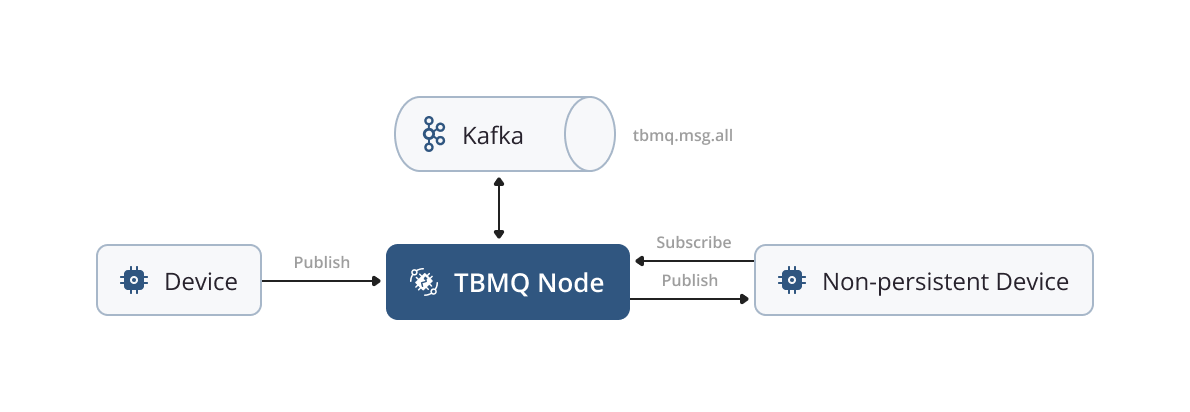
Persistent Client
MQTT clients that do not meet the non-persistent conditions mentioned above are categorized as persistent clients. Let’s delve into the conditions for persistent clients:
For MQTT v3.x:
clean_sessionflag is set to false.
For MQTT v5 clients:
sessionExpiryIntervalis greater than 0 (regardless of theclean_startflag).clean_startflag is set to false andsessionExpiryIntervalis set to 0 or not specified.
Building on our knowledge within the IoT ecosystem and the successful implementation of numerous IoT use cases, we have classified MQTT clients into two distinct categories:
- The DEVICE clients primarily engaged in publishing a significant volume of messages while subscribing to a limited number of topics with relatively low message rates. These clients are typically associated with IoT devices or sensors that frequently transmit data to the broker.
- The APPLICATION clients specialize in subscribing to topics with high message rates. They often require messages to be persisted when the client is offline with later delivery, ensuring the availability of crucial data. These clients are commonly used for real-time analytics, data processing, or other application-level functionalities.
Consequently, we made a strategic decision to optimize performance by separating the processing flow for these two types of clients.
Persistent Device Client
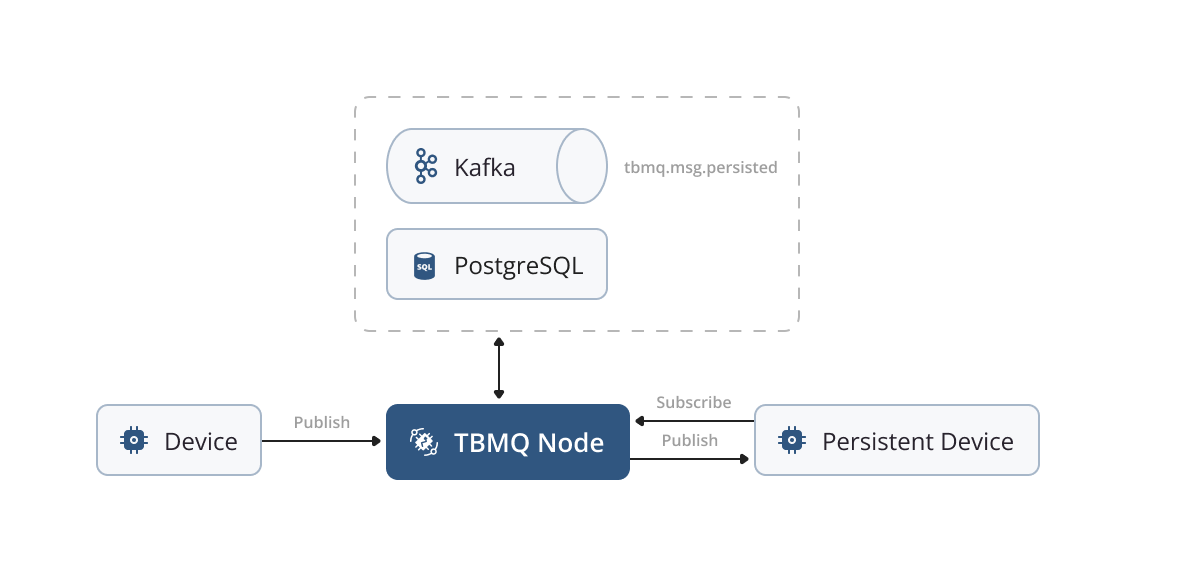
For Device persistent clients, we use the tbmq.msg.persisted Kafka topic as a means of processing published messages that are extracted from the tbmq.msg.all topic. Dedicated threads, functioning as Kafka consumers, retrieve these messages and store them in a PostgreSQL database utilized for persistence storage. This approach is particularly suitable for Device clients, as they typically do not require extensive message reception. This approach helps us recover stored messages smoothly when a client reconnects. At the same time, it ensures good performance for scenarios involving a low incoming message rate.
We expect persistent Device clients to receive no more than 5K messages/second overall due to PostgreSQL limitations. We plan to add support for Redis to optimize persistent storage for Device clients.
Persistent Application Client
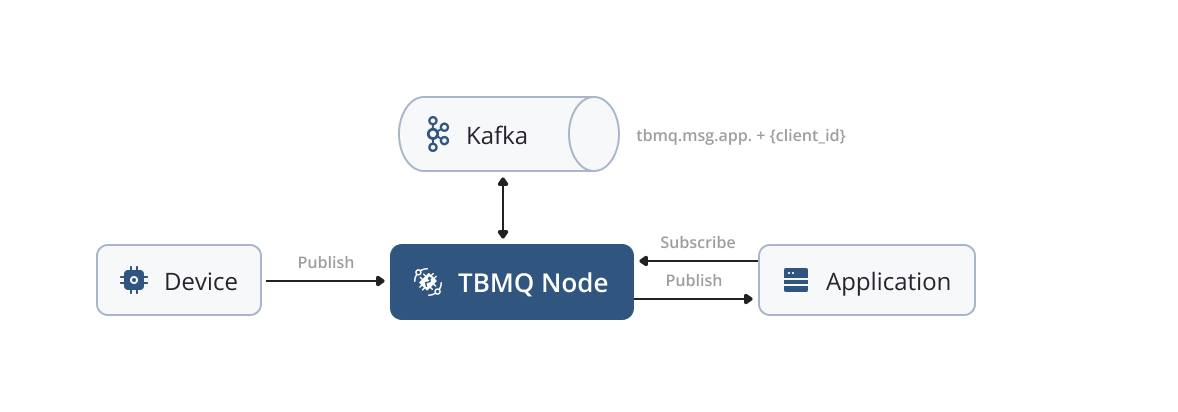 The number of Application clients corresponds to the number of Kafka topics used. The latest version of Kafka can handle millions of topics, making this design suitable even for the largest enterprise use cases.
The number of Application clients corresponds to the number of Kafka topics used. The latest version of Kafka can handle millions of topics, making this design suitable even for the largest enterprise use cases.
Any message read from the tbmq.msg.all topic meant for a specific Application client is then stored in the corresponding Kafka topic. A separate thread (Kafka consumer) is assigned to each Application. These threads retrieve messages from the corresponding Kafka topics and deliver them to the respective clients. This approach significantly improves performance by ensuring efficient message delivery. Additionally, the nature of the Kafka consumer group makes the MQTT 5 shared subscription feature extremely efficient for Application clients.
Application clients can handle a large volume of received messages, reaching millions per second.
Summary
In conclusion, TBMQ's design emphasizes meeting the complex demands of IoT communication. It prioritizes scalability, fault tolerance, and efficiency, relying on Kafka for reliable message handling across various scenarios.
By distinguishing processing strategies for Device and Application clients, TBMQ optimizes message persistence and guarantees consistent and fast message delivery.
Links
Published at DZone with permission of Dima Landiak. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments