Streaming Data From MongoDB Atlas to SingleStore Kai Using Kafka and CDC
Learn how to use the new SingleStore CDC solution.
Join the DZone community and get the full member experience.
Join For FreeSingleStore provides a Change Data Capture (CDC) solution to stream data from MongoDB to SingleStore Kai. In this article, we'll see how to connect an Apache Kafka broker to MongoDB Atlas and then stream the data from MongoDB Atlas to SingleStore Kai using the CDC solution. We'll also use Metabase to create a simple analytics dashboard for SingleStore Kai.
The notebook file used in this article is available on GitHub.
What Is CDC?
CDC is a way to keep track of changes that happen in a database or a system. SingleStore now provides a CDC solution that works with MongoDB.
To demonstrate the CDC solution, we'll use a Kafka broker to stream data to a MongoDB Atlas cluster and then use the CDC pipeline to propagate the data from MongoDB Atlas to SingleStore Kai. We'll also create a simple analytics dashboard using Metabase.
Figure 1 shows the high-level architecture of our system.
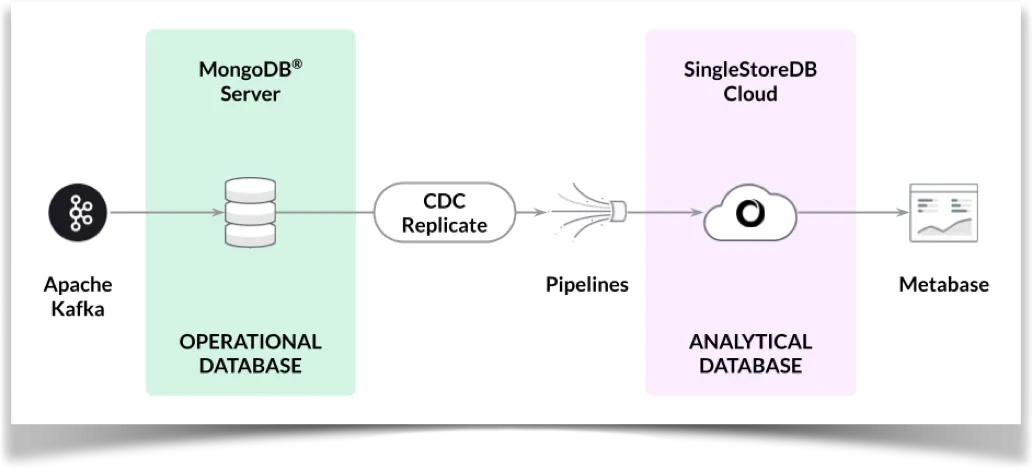
Figure 1. High-Level Architecture (Source: SingleStore)
We'll focus on other scenarios using the CDC solution in future articles.
MongoDB Atlas
We'll use MongoDB Atlas in an M0 Sandbox. We'll configure an admin user with atlasAdmin privileges under Database Access. We'll temporarily allow access from anywhere (IP Address 0.0.0.0/0) under Network Access. We'll note down the username, password, and host.
Apache Kafka
We'll configure a Kafka broker to stream data into MongoDB Atlas. We'll use a Jupyter Notebook to achieve this.
First, we'll install some libraries:
!pip install pymongo kafka-python --quietNext, we'll connect to MongoDB Atlas and the Kafka broker:
from kafka import KafkaConsumer
from pymongo import MongoClient
try:
client = MongoClient("mongodb+srv://<username>:<password>@<host>/?retryWrites=true&w=majority")
db = client.adtech
print("Connected successfully")
except:
print("Could not connect")
consumer = KafkaConsumer(
"ad_events",
bootstrap_servers = ["public-kafka.memcompute.com:9092"]
)We'll replace <username>, <password> and <host> with the values that we saved earlier from MongoDB Atlas.
Initially, we'll load 100 records into MongoDB Atlas, as follows:
MAX_ITERATIONS = 100
for iteration, message in enumerate(consumer, start = 1):
if iteration > MAX_ITERATIONS:
break
try:
record = message.value.decode("utf-8")
user_id, event_name, advertiser, campaign, gender, income, page_url, region, country = map(str.strip, record.split("\t"))
events_record = {
"user_id": int(user_id),
"event_name": event_name,
"advertiser": advertiser,
"campaign": int(campaign.split()[0]),
"gender": gender,
"income": income,
"page_url": page_url,
"region": region,
"country": country
}
db.events.insert_one(events_record)
except Exception as e:
print(f"Iteration {iteration}: Could not insert data - {str(e)}")The data should load successfully and we should see a database called adtech with a collection called events. Documents in the collection should be similar in structure to the following example:
_id: ObjectId('64ec906d0e8c0f7bcf72a8ed')
user_id: 3857963415
event_name: "Impression"
advertiser: "Sherwin-Williams"
campaign: 13
gender: "Female"
income: "25k and below",
page_url: "/2013/02/how-to-make-glitter-valentines-heart-boxes.html/"
region: "Michigan"
country: "US"These documents represent Ad Campaign events. The events collection stores details of the advertiser, campaign and various demographic information about the user, such as gender and income.
SingleStore Kai
A previous article showed the steps to create a free SingleStoreDB Cloud account. We'll use the following settings:
- Workspace Group Name: CDC Demo Group
- Cloud Provider: AWS
- Region: US East 1 (N. Virginia)
- Workspace Name: cdc-demo
- Size: S-00
- Settings:
- SingleStore Kai selected
Once the workspace is available, we'll make a note of our password and host. The host will be available from CDC Demo Group > Overview > Workspaces > cdc-demo > Connect > Connect Directly > SQL IDE > Host. We'll need this information later for Metabase. We'll also temporarily allow access from anywhere by configuring the firewall under CDC Demo Group > Firewall.
From the left navigation pane, we'll select DEVELOP > SQL Editor to create a adtech database and link, as follows:
CREATE DATABASE IF NOT EXISTS adtech;
USE adtech;
DROP LINK adtech.link;
CREATE LINK adtech.link AS MONGODB
CONFIG '{"mongodb.hosts": "<primary>:27017, <secondary>:27017, <secondary>:27017",
"collection.include.list": "adtech.*",
"mongodb.ssl.enabled": "true",
"mongodb.authsource": "admin",
"mongodb.members.auto.discover": "false"}'
CREDENTIALS '{"mongodb.user": "<username>",
"mongodb.password": "<password>"}';
CREATE TABLES AS INFER PIPELINE AS LOAD DATA LINK adtech.link '*' FORMAT AVRO;We'll replace <username> and <password> with the values that we saved earlier from MongoDB Atlas. We'll also need to replace the values for <primary>, <secondary> and <secondary> with the full address for each from MongoDB Atlas.
We'll now check for any tables, as follows:
SHOW TABLES;This should show one table called events:
+------------------+
| Tables_in_adtech |
+------------------+
| events |
+------------------+We'll check the structure of the table:
DESCRIBE events;The output should be as follows:
+-------+------+------+------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------+------+------+---------+-------+
| _id | text | NO | UNI | NULL | |
| _more | JSON | NO | | NULL | |
+-------+------+------+------+---------+-------+Next, we'll check for any pipelines:
SHOW PIPELINES;This will show one pipeline called events that is currently Stopped:
+---------------------+---------+-----------+
| Pipelines_in_adtech | State | Scheduled |
+---------------------+---------+-----------+
| events | Stopped | False |
+---------------------+---------+-----------+Now we'll start the events pipeline:
START ALL PIPELINES;and the state should change to Running:
+---------------------+---------+-----------+
| Pipelines_in_adtech | State | Scheduled |
+---------------------+---------+-----------+
| events | Running | False |
+---------------------+---------+-----------+If we now run the following command:
SELECT COUNT(*) FROM events;it should return 100 as the result:
+----------+
| COUNT(*) |
+----------+
| 100 |
+----------+We'll check one row in the events table, as follows:
SELECT * FROM events LIMIT 1;The output should be similar to the following:
+--------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| _id | _more |
+--------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| {"$oid": "64ec906d0e8c0f7bcf72a8f7"} | {"_id":{"$oid":"64ec906d0e8c0f7bcf72a8f7"},"advertiser":"Wendys","campaign":13,"country":"US","event_name":"Click","gender":"Female","income":"75k - 99k","page_url":"/2014/05/flamingo-pop-bridal-shower-collab-with.html","region":"New Mexico","user_id":3857963416} |
+--------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+The CDC solution has successfully connected to MongoDB Atlas and replicated all 100 records to SingleStore Kai.
Let's now create a dashboard using Metabase.
Metabase
Details of how to install, configure, and create a connection to Metabase were described in a previous article. We'll create visualizations using slight variations of the queries used in the earlier article.
1. Total Number of Events
SELECT COUNT(*) FROM events;2. Events by Region
SELECT _more::country AS `events.country`, COUNT(_more::country) AS 'events.countofevents'
FROM adtech.events AS events
GROUP BY 1;3. Events by Top 5 Advertisers
SELECT _more::advertiser AS `events.advertiser`, COUNT(*) AS `events.count`
FROM adtech.events AS events
WHERE (_more::advertiser LIKE '%Subway%' OR _more::advertiser LIKE '%McDonals%' OR _more::advertiser LIKE '%Starbucks%' OR _more::advertiser LIKE '%Dollar General%' OR _more::advertiser LIKE '%YUM! Brands%' OR _more::advertiser LIKE '%Dunkin Brands Group%')
GROUP BY 1
ORDER BY `events.count` DESC;4. Ad Visitors by Gender and Income
SELECT *
FROM (SELECT *, DENSE_RANK() OVER (ORDER BY xx.z___min_rank) AS z___pivot_row_rank, RANK() OVER (PARTITION BY xx.z__pivot_col_rank ORDER BY xx.z___min_rank) AS z__pivot_col_ordering, CASE
WHEN xx.z___min_rank = xx.z___rank THEN 1
ELSE 0
END AS z__is_highest_ranked_cell
FROM (SELECT *, Min(aa.z___rank) OVER (PARTITION BY aa.`events.income`) AS z___min_rank
FROM (SELECT *, RANK() OVER (ORDER BY CASE
WHEN bb.z__pivot_col_rank = 1 THEN (CASE
WHEN bb.`events.count` IS NOT NULL THEN 0
ELSE 1
END)
ELSE 2
END, CASE
WHEN bb.z__pivot_col_rank = 1 THEN bb.`events.count`
ELSE NULL
END DESC, bb.`events.count` DESC, bb.z__pivot_col_rank, bb.`events.income`) AS z___rank
FROM (SELECT *, DENSE_RANK() OVER (ORDER BY CASE
WHEN ww.`events.gender` IS NULL THEN 1
ELSE 0
END, ww.`events.gender`) AS z__pivot_col_rank
FROM (SELECT _more::gender AS `events.gender`, _more::income AS `events.income`, COUNT(*) AS `events.count`
FROM adtech.events AS events
WHERE (_more::income <> 'unknown' OR _more::income IS NULL)
GROUP BY 1, 2) ww) bb
WHERE bb.z__pivot_col_rank <= 16384) aa) xx) zz
WHERE (zz.z__pivot_col_rank <= 50 OR zz.z__is_highest_ranked_cell = 1) AND (zz.z___pivot_row_rank <= 500 OR zz.z__pivot_col_ordering = 1)
ORDER BY zz.z___pivot_row_rank;Figure 2 shows an example of the charts sized and positioned on the AdTech dashboard. We'll set the auto-refresh option to 1 minute.

Figure 2. Final Dashboard
If we load more data into MongoDB Atlas using the Jupyter notebook by changing MAX_ITERATIONS, we'll see the data propagated to SingleStore Kai and the new data reflected in the AdTech dashboard.
Summary
In this article, we created a CDC pipeline to augment MongoDB Atlas with SingleStore Kai. SingleStore Kai can be used for analytics due to its far superior performance, as highlighted by several benchmarks. We also used Metabase to create a quick visual dashboard to help us gain insights into our Ad Campaign.
Published at DZone with permission of Akmal Chaudhri. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments