Streaming Data From Files Into Multi-Broker Kafka Clusters
Join the DZone community and get the full member experience.
Join For FreeThere are multiple ways to ingest data streams into the Apache Kafka topic and subsequently deliver to various types of consumers who are hooked to the topic. The stream of data that collects continuously from the topic by consumers, passes through multiple data pipelines and then stream processing engines like Apache Spark, Apache Flink, Amazon Kinesis, etc and eventually landed upon the real-time applications to deliver a final data-driven decision. From finances, manufacturing, insurance, telecom, healthcare, commerce, and more, real-time applications are becoming the best solution for organizations to take immediate action, gain insights from the updated data. In the present day, Apache Kafka shapes the central nervous system that brings data from all aspects of the business to the large information operational hubs where choices are made.
The text files contain unformatted ASCII text and are commonly used for the storage of information. Each line of the file represents a data record and can be updated continuously to store. Every insert of a new line or lines on the text file can be considered as new data insertion on the file. Henceforth, every addition of a new line or lines on the text file continuously either by humans or applications (no modification on the already inserted line)and subsequently moves or sends to a different location can be considered as data streaming from the file. Every addition of a new line or row in the text file can be analyzed continuously by exporting the new line/lines to the Kafka topic and importing them by consumers that hooks up with the topic.
In this article, we are going to see how FileSource and FileSink Connector can be leveraged for streaming data from a text file to a multi-broker Apache topic and subsequently sink to another file. Kafka Connect is a tool for streaming data between Apache Kafka and other external systems and the FileSource Connector is one of the connectors to stream data from files and FileSink connector to sink the data from the topic to another file. Similarly, numerous types of connector are available like Kafka Connect JDBC Source connector that imports data from any relational database with a JDBC driver into an Apache Kafka topic. Confluent.io developed numerous connectors for import and export data into Kafka from various sources like HDFS, Amazon S3, Google cloud storage, etc. Connectors belong to commercial as well as Confluent Community License. Please click here to know more about the Confluent Kafka connector.
File Source connector to stream or export data into Kafka topic and File Sink connector to import or sink data from the Kafka topic to another file. The file that receives the data continuously from the topic can be considered as a consumer. These two connectors are part of the Open Source Apache Kafka ecosystem and do not require any separate installation. This article has been segmented into 4 parts. Let’s begin with the assumptions.
1. Assumptions
Here I am considering the operational Kafka cluster having four nodes and each one is already installed and running Kafka of version 2.6.0 with Zookeeper (V 3.5.6) on top of OS Ubuntu 14.04 LTS and java version “1.8.0_101”. Schema Registry won’t be running to run/execute this exercise. You can read here how to integrate Confluent Schema Registry with a multi-node Kafka cluster.
2. Configuration
a. Two configuration files namely connect-file-source.properties and connect-file-sink.properties available under the config directory of Kafka have to be modified.
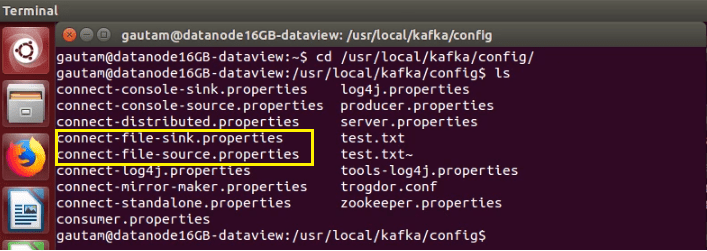
In file connect-file-source.properties, update the key with a value that is the file name with an absolute path from which data would stream or export continuously to a topic. And the next one is the topic name.
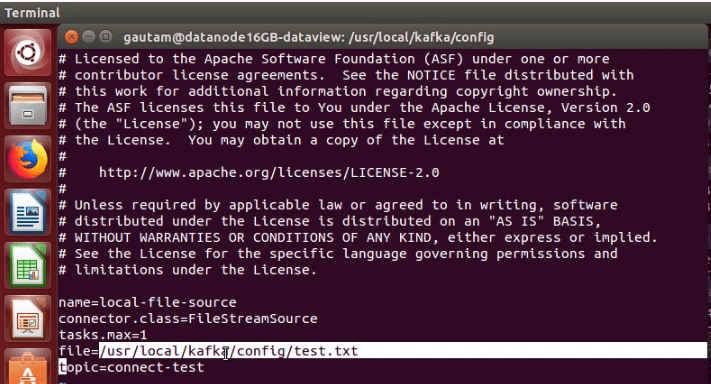
Similarly another file connect-file-sink.properties to where data sinks continuously from the topic. Since data would be exported and imported through files from the same topic, the name of the topic should be the same on both the configuration files.
b. Created one new topic using the following command using kafka-topics.sh available inside bin directory in the running cluster to dedicate completely for file data streaming only. And updated the same topic name in both the configuration files.
xxxxxxxxxx
$Kafka_Home/bin$ ./kafka-topics.sh –bootstrap-server <list of IP Address and port separated by comma(,) > –create –replication-factor <replication factor number> –partitions <Number of partition in the topic> –topic <Topic Name>

c. Update connect-standalone.properties
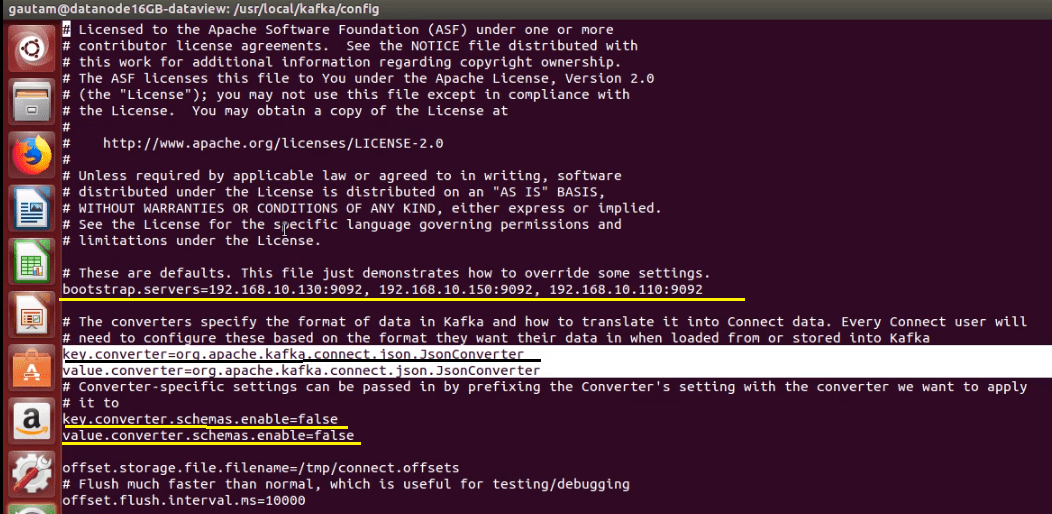
The connect-standalone.properties file available under the config directory of Kafka and going to run both the connector in Standalone mode. In Standalone mode, a single process executes all connectors and their associated tasks. By default, the key ” bootstrap.servers ” in the properties file available with the value ” localhost:9092” but we are going to run the connectors in a multi-node/multi-broker cluster so it has to be updated with the IP address of each node and port separated by comma (,)
x
bootstrap.servers=192.168.10.130:9092, 192.168.10.150:9092, 192.168.10.110:9092
Since, we won’t be preserving the versioned history of schemas while streaming data from file to Kafka Topic, Schema Registry is not used or coupled with the cluster. Because of this reason the following keys need to set the value as “false”. By default values are as “true”.
x
key.converter.schemas.enable=false
value.converter.schemas.enable=false
Also, the format of data would be JSON when loaded from or stored into Kafka because of this no need for any changes on the following keys. Of course, need an update if we use Avro or Protobuf.
x
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
3. Execution
To stream the data written in the file and subsequent update continuously hereafter with text, the script connect-standalone.sh available inside the bin directory, has to be executed from the terminal with the location of two files namely connect-standalone.properties and connect-file-source.properties as parameters. Before that, make sure the multi-broker Kafka cluster is up and running.
xxxxxxxxxx
/kafka/bin $ ./connect-standalone.sh ../config/connect-standalone.properties ../config/connect-file-source.properties
 Eventually, the text starts importing from the file to the configured topic internally with the appearance of the following logs on the terminal. If we insert a new line or words in the file and saved it, the same would be imported to the topic immediately.
Eventually, the text starts importing from the file to the configured topic internally with the appearance of the following logs on the terminal. If we insert a new line or words in the file and saved it, the same would be imported to the topic immediately.
Using console-consumer.sh available inside the bin directory We can verify/view the imported data by consuming from that topic. Similarly, the data that already imported or streamed to the topic from the file can be exported to a different file permanently by executing connect-file-sink.sh script from the terminal.
/kafka/bin $ ./connect-standalone.sh ../config/connect-standalone.properties ../config/connect-file-sink.properties
 In nutshell, whatever we write in the configured input file can be streamed to another file by leveraging Kafka file source and sink connectors together. If interested, you can watch the following video on how data is continuously streaming from one text file to another.
In nutshell, whatever we write in the configured input file can be streamed to another file by leveraging Kafka file source and sink connectors together. If interested, you can watch the following video on how data is continuously streaming from one text file to another.
4. Conclusion
We have seen in this article that how easy to stream data continuously from a text file to another using Kafka and built-in File Source and File Sink connector without writing a single line of code. Also, the File connector (Both source and sink) is a powerful open-sourced solution that you can leverage to visualized data streaming for understanding or POC development without banking on any other third-party streaming data source. Please do not hesitate to share this article if you like this approach
Published at DZone with permission of Gautam Goswami, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments