Stop Treating Your Data Engineer Like a Data Catalog
Data trust starts and ends with communication. Here’s how best-in-class data teams are proactively certifying tables as approved for use across their organizations.
Join the DZone community and get the full member experience.
Join For FreeData trust starts and ends with communication. Here’s how best-in-class data teams proactively certify tables as approved for use across their organizations.
Say it with me: data engineers are not data catalogs.
In their job description, you would be hard-pressed to find “answering multiple Slack messages every week about which tables are good to use for this report,” but it happens nonetheless.
Data analysts aren’t psychic. Yet, they are often placed in the position of having to intuit if the data being piped is trustworthy.
This misalignment has arisen as data teams are pushed to move faster, weave themselves across the data mesh, and enable increasingly self-service data platforms.
It’s the data team’s equivalent of the classic document version control issues that have plagued knowledge workers for decades. What starts as a tight pitch deck evolves into:
- A million people making and sharing ad-hoc slides;
- Massaging content on those slides until it becomes an echo of its original intent; and
- Creating copies labeled V6_Final_RealFinal.
The same thing happens across the data team. Everyone is trying to do the right thing (i.e., support your stakeholders, generate insights, pipe more data, etc.), but everyone is also moving fast.
One day, you notice you have 6 different models with slight variations essentially doing the same thing…and no one knows which one is most up-to-date or even which field to use.
This creates real operational problems downstream, including:
- Inefficient cycles of redundant “traffic control;.”
- Lower data quality;
- Time spent resolving problems created by analysts using improper/problematic data;
- Lower data trust across the organization; and
- Increased data downtime
When you don’t trust your data or have lower data reliability, organizations often pad the margins of error in their forecasts.
Peleton’s recent production halt highlighted that poor forecasting can be especially problematic during the pandemic when uncertainty across demand, supply chains, and the overall business environment is at an all-time high.
More Data Discovery, More Problems
Data Discovery is a new approach to understanding the health of your distributed data assets in real-time, and it’s an essential part of the solution.
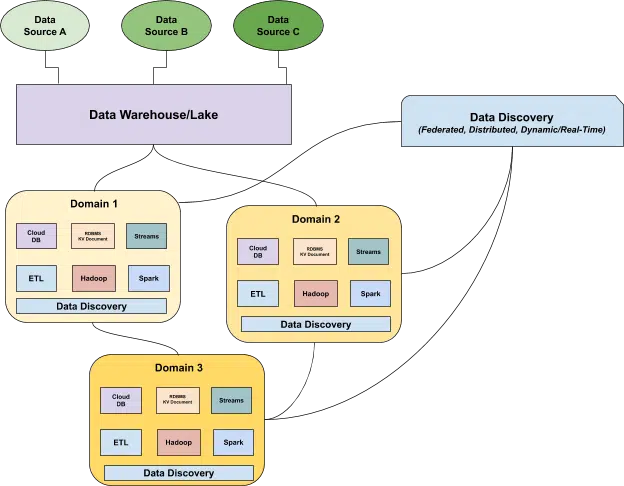
Data discovery provides a domain-specific, dynamic understanding of your data based on how it’s being ingested, stored, aggregated, and used by a set of specific consumers.
As with a data catalog, governance standards and tooling are federated across these domains (allowing for greater accessibility and interoperability), but unlike a data catalog, data discovery surfaces a real-time understanding of the data’s current state as opposed to its ideal or “cataloged” state.
It is especially useful when teams take a distributed approach to governance that holds different data owners accountable for their data as products, which allows data-savvy users throughout the business to self-serve from those products.
But as data becomes more accessible, how can downstream stakeholders determine what data sets have been served, transformed, and approved by a given domain’s data team?
How can one domain be sure a common set of data quality standards, ownership, and communication processes are being upheld across the organization?
One of my customers, a leading media company with a mature data organization, faced these exact questions. As a result, we have worked with them and several others to implement a data certification program.
What Is Data Certification?
Data certification is when data assets are approved for use across the organization after meeting mutually agreed-upon SLAs or service-level agreements for data quality, observability, ownership/accountability, issue resolution, and communication.
Like data quality, data validation, or data verification, data certification layers on critical processes that align people, frameworks, and technology to central business policies.
Data certification requirements vary based on the needs of the business, the capacity of the data engineering team, and the availability of data, but typically incorporate the following features:

Here’s how it works.
6 Steps to Implementing a Data Certification Program
Step 1: Build Out Your Data Observability Capabilities
Implementing data observability–an organization’s ability to fully understand the health of the data in their system–is an important first step in the data certification process.
Not only do you need insight into your current performance to set a baseline, but you also need a systemic end-to-end approach for proactive incident discovery, alerting, and triaging.
If anything within the pipeline breaks–and it will break–you will be the first to know. This head start and a detailed understanding of the data ecosystem will reduce the time to detection and resolution by pinpointing where errors occur.
Knowing what systems and data sets have a tendency to create the largest or most frequent problems downstream also helps inform the process of writing effective data SLAs (Step 4).
Additionally, understanding the upstream dependencies of your most important tables or reports helps data teams understand what data to give the most attention.
The bottom line is that a table or data set should be closely monitored for anomalies (ideally continuously learning and evolving via machine learning) to be considered certified.
Step 2: Determine Your Data Owners
Each certified data asset should have a responsible party across its lifecycle from the ingestion to the analytics layer.

Step 3. Understand What “Good” Data Looks Like
By asking your business stakeholders the “who, what, when, where, and why,” you can understand what data quality means to them and which data is the most important.
This will enable you to develop key performance indicators such as:
- Freshness:
- Data will be refreshed by 7:00 am daily (great for cases where the CEO or other key executives are checking their dashboards at 7:30 am).
- Data will never be older than X hours.
- Distribution:
- Column X will never be null.
- Column Y will always be unique.
- Therefore, field X will always be equal to or greater than field Y.
- Volume:
- Table X will never decrease in size.
- Schema:
- No fields will be deleted on this table.
- Lineage:
- 100% of the data populating table X will have upstream sources and downstream ingestors mapped and include relevant metadata.
- Data downtime (or availability):
- Data downtime is defined as the number of incidents multiplied by (the time to detection + time to resolution). An example of a data downtime SLA could be table X will have less than Y hours of downtime a year.
- SLAs that measure each of the components of data downtime can be more actionable. Examples include reducing our incidents X%, time to detection X%, and time to resolution X%.
- Query Speed:
- Locally Optimistic suggests: “Average query run time is an excellent place to start, but you may need to create a more nuanced metric (e.g., X% of queries finish in <Y seconds).
- Ingestion (great for keeping external partners accountable):
- Data will be received by 5 am each morning from partner Y.
This process also enables you to configure granular alerting rules tailored to what matters most to the business.
Step 4: Set Clear SLAs for Your Most Important Data Sets
Setting SLAs (service level agreements) for your data pipeline is a major step toward increasing your data reliability and is essential to a data certification program. SLAs need to be specific, measurable, and achievable.
Not only do SLAs describe an agreed-upon standard of service, but they also define the relationship between parties. In other words, they outline who is responsible for what during normal operations and when issues occur.
Brandon Beidel, a Senior Data Scientist with Red Ventures, suggests that an effective SLA is realistic. For example, simply saying “having reliable data at all times” is too vague to be useful; instead, Brandon suggests that teams should set focused SLAs.
“Good SLAs are specific and detailed. They will describe why it’s important to the business, what the expectations are when those expectations need to be met, how they will be met, where the data lives, and who is impacted by it.”
Beidel includes how the team should respond within his SLAs if the SLA isn’t met.
For example, “the data in table X will be refreshed every day by 7:00 am” will transform into “Team Z will ensure the data in table X will be refreshed every day by 7:00 am. Within 2 hours of an anomaly alert, the team will verify, communicate to affected parties, and begin a root cause analysis of the issue. A ticket will be created within one business day, and the wider team will be updated on the progress made toward resolution.”
To achieve this level of specificity and organization, teams should align early – and often – with stakeholders to understand what good data looks like.
That includes within the data team as well as the business. A good SLA needs to be informed by the realities of how the business operates and how your users consume the data.
I take a slightly different approach and differentiate between what I consider the SLA of “table x will be updated by 7 am” and the SLO (Service Level Objective) of “we will aim to meet this SLA 99% of the time.”
However you decide to approach it, I’d recommend against boiling the ocean. Most of my customers are implementing their data certification programs as “go forward” first and cleaning up older assets in a second wave.
Many of the best data teams will start certifying the most critical tables and data sets: the ones that add the most value to the business, have the most query activity, the number of users, or dependencies.
Some are also implementing tiers of certification–bronze, silver, gold–that convey different levels of service and support.
Step 5: Develop Your Communication and Incident Management Processes
Where and how will alerts be sent to the team? How will the following steps and progress be communicated internally and externally?
While this may seem like table stakes, clear and transparent communication is essential to creating a culture of accountability.
Many teams opt to have alerts and incident triage discussions in Slack, PagerDuty, or Microsoft Teams. This enables rapid coordination while giving full transparency to the wider team as part of a health incident management workflow.
It’s also important to consider how to communicate major outages to the rest of the organization.
For example, if an alert turns out to be a huge production outage, how does the on-call engineer inform the rest of the company? Where do they make that announcement, and how frequently do they provide updates?
Step 6: Determine a Mechanism to Tag the Data as Certified
At this point, you have created SLAs with measurable objectives, transparent ownership, clear communication processes, and strong issue resolution expectations. You have the tools and proactive measures to empower your teams to be successful.
The final step is to certify and surface the approved data assets for your stakeholders.
I recommend decentralizing the certification process. After all, the certification process is designed to help make teams faster and more scalable. Having centralized regulations enacted at the domain level will achieve these goals and avoid creating too much red tape.
For the certification process, data teams will tag, search and leverage their tables appropriately using data discovery solutions, a home-grown tool, or some other form of the data catalog.
Step 7: Train Your Data Team and Downstream Consumers
Of course, just because tables are tagged as certified doesn’t guarantee analysts will stay inbound. The team will need to be trained in the proper procedures, which will need to be enforced as necessary.
Fine-tuning the level of alerts and communication is important as well.
Occasionally receiving alerts that don’t require action is healthy. For example, you may have a table that grows significantly in size, but it was expected because the team added a new data source.
Nothing is broken and in need of fixing, but it’s still helpful for the team to know. After all, “expected” behavior to one person might still be newsworthy and critical to another member of the team – or even another domain.
However, alert fatigue is real. For example, suppose the team is starting to ignore alerts. In that case, it can be a sign to optimize your approach by either adjusting your monitors or bi-furcating communication channels to better surface the most important information.
When it comes to your data consumers, don’t be shy! You have put in an incredibly robust system for data quality aligned to their needs. Help them move from a subjective to objective understanding of how your team performs and start giving them the vocabulary to be part of the solution.
It’s All About Proactive Communication
Data certification can be a beautiful process to see in action. The data engineer tags the table as certified along with the owner of the data set and surfaces it within the data warehouse for an analyst to grab it and use in their dashboard. And viola! No more (or at least a lot less) data downtime.
At its core, this process underscores that without the proper processes and culture in place, certifying reliability and building organizational trust in your data is extremely difficult. Technology will never be a replacement for good data hygiene, but it certainly helps.
Published at DZone with permission of Will Robins. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments