Step-By-Step Guide to Building a High-Performing Risk Data Mart
We aim to serve four needs in our data platform development: monitoring and alerting, query and analysis, dashboarding, and data modeling.
Join the DZone community and get the full member experience.
Join For FreePursuing data-driven management, we aim to serve four needs in our data platform development: monitoring and alerting, query and analysis, dashboarding, and data modeling. For these purposes, we built our data processing architecture based on Greenplum and CDH. The most essential part of it is the risk data mart.
Risk Data Mart: Apache Hive
I will walk you through how the risk data mart works following the data flow:
- Our business data is imported into Greenplum for real-time analysis to generate BI reports. Part of this data also goes into Apache Hive for queries and modeling analysis.
- Our risk control variables are updated in Elasticsearch in real-time via message queues, while Elasticsearch ingests data into Hive for analysis, too.
- The risk management decision data is passed from MongoDB to Hive for risk control analysis and modeling.
So these are the three data sources of our risk data mart.

This whole architecture is built with CDH 6.0. The workflows in it can be divided into real-time data streaming and offline risk analysis.
- Real-time data streaming: Real-time data from Apache Kafka will be cleaned by Apache Flink and then written into Elasticsearch. Elasticsearch will aggregate part of the data it receives and send it for reference in risk management.
- Offline risk analysis: Based on the CDH solution and utilizing Sqoop, we ingest data from Greenplum in an offline manner. Then we put this data together with the third-party data from MongoDB. Then, after data cleaning, we pour all this data into Hive for daily batch processing and data queries.
To give a brief overview, these are the components that support the four features of our data processing platform:

As you see, Apache Hive is central to this architecture. But in practice, it takes minutes for Apache Hive to execute analysis, so our next step is to increase query speed.
What Is Slowing Down Our Queries?
Huge Data Volume in External Tables
Our Hive-based data mart is now carrying more than 300 terabytes of data. That's about 20,000 tables and five million fields. Putting them all in external tables is maintenance-intensive. Plus, data ingestion can be a big headache.
Big Flat Tables
Due to the complexity of the rule engine in risk management, our company invests a lot in the derivation of variables. In some dimensions, we have thousands of variables or even more. As a result, a few of the frequently used flat tables in Hive have over 3000 fields. So you can imagine how time-consuming these queries can be.
Unstable Interface
Results produced by daily offline batch processing will be regularly sent to our Elasticsearch clusters. (The data volume in these updates is huge, and the call of the interface can get expired.) This process might cause high I/O and introduce garbage collection jitter, which further leads to unstable interface services.
In addition, since our risk control analysts and modeling engineers are using Hive with Spark, the expanding data architecture is also dragging down query performance.
A Unified Query Gateway
We wanted a unified gateway to manage our heterogeneous data sources. That's why we introduced Apache Doris.

But doesn't that make things even more complicated? Actually, no.
We can connect various data sources to Apache Doris and simply conduct queries on it. This is made possible by the Multi-Catalog feature of Apache Doris: It can interface with various data sources, including data lakes like Apache Hive, Apache Iceberg, and Apache Hudi, and databases like MySQL, Elasticsearch, and Greenplum. That happens to cover our toolkit.
We create Elasticsearch Catalog and Hive Catalog in Apache Doris. These catalogs map to the external data in Elasticsearch and Hive, so we can conduct federated queries across these data sources using Apache Doris as a unified gateway. Also, we use the Spark-Doris-Connector to allow data communication between Spark and Doris. So basically, we replace Apache Hive with Apache Doris as the central hub of our data architecture.

How does that affect our data processing efficiency?
- Monitoring and Alerting: This is about real-time data querying. We access our real-time data in Elasticsearch clusters using Elasticsearch Catalog in Apache Doris. Then we perform queries directly in Apache Doris. It is able to return results within seconds, as opposed to the minute-level response time when we used Hive.
- Query and Analysis: As I said, we have 20,000 tables in Hive, so it wouldn't make sense to map all of them to external tables in Hive. That would mean a hell of maintenance. Instead, we utilize the Multi Catalog feature of Apache Doris 1.2. It enables data mapping at the catalog level, so we can simply create one Hive Catalog in Doris before we can conduct queries. This separates query operations from the daily batching processing workload in Hive, so there will be less resource conflict.
- Dashboarding: We use Tableau and Doris to provide dashboard services. This reduces the query response time to seconds and milliseconds, compared with several minutes back in the "Tableau + Hive" days.
- Modeling: We use Spark and Doris for aggregation modeling. The Spark-Doris-Connector allows mutual synchronization of data, so data from Doris can also be used in modeling for more accurate analysis.
Cluster Monitoring in the Production Environment
We tested this new architecture in our production environment. We built two clusters.
Configuration:
Production cluster: 4 frontends + 8 backends, m5d.16xlarge
Backup cluster: 4 frontends + 4 backends, m5d.16xlarge
This is the monitoring board:
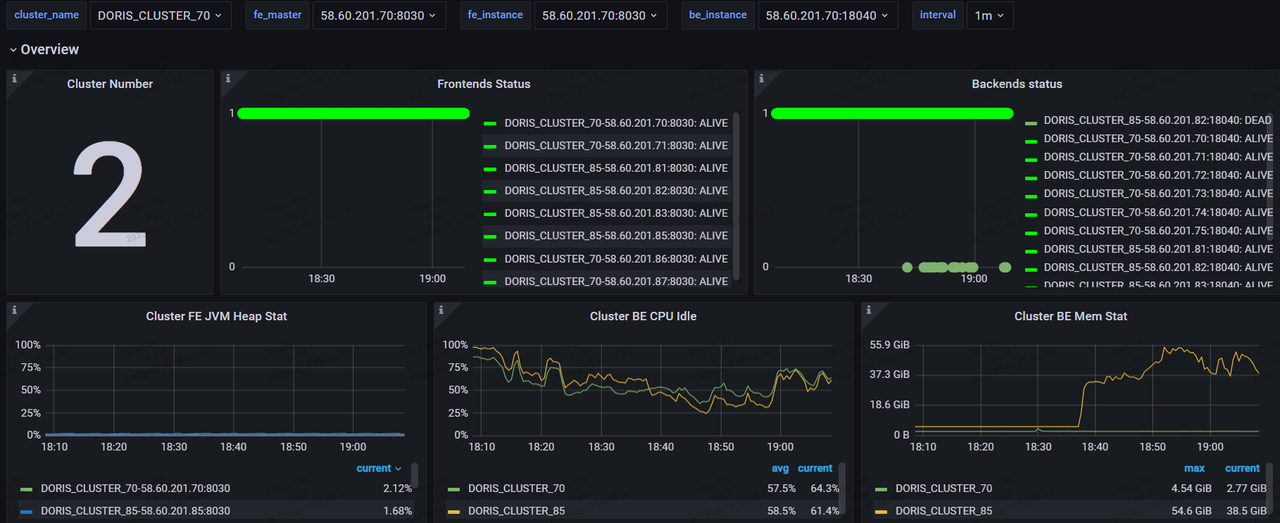
As is shown, the queries are fast. We expected that it would take at least 10 nodes, but in real cases, we mainly conduct queries via Catalogs, so we can handle this with relatively small cluster size. The compatibility is good, too. It doesn't rock the rest of our existing system.
Guide to Faster Data Integration
To accelerate the regular data ingestion from Hive to Apache Doris 1.2.2, we have a solution that goes as follows:

Main components:
- DolphinScheduler 3.1.4
- SeaTunnel 2.1.3
With our current hardware configuration, we use the Shell script mode of DolphinScheduler and call the SeaTunnel script on a regular basis. This is the configuration file of the data synchronization tasks:
env{
spark.app.name = "hive2doris-template"
spark.executor.instances = 10
spark.executor.cores = 5
spark.executor.memory = "20g"
}
spark {
spark.sql.catalogImplementation = "hive"
}
source {
hive {
pre_sql = "select * from ods.demo_tbl where dt='2023-03-09'"
result_table_name = "ods_demo_tbl"
}
}
transform {
}
sink {
doris {
fenodes = "192.168.0.10:8030,192.168.0.11:8030,192.168.0.12:8030,192.168.0.13:8030"
user = root
password = "XXX"
database = ods
table = ods_demo_tbl
batch_size = 500000
max_retries = 1
interval = 10000
doris.column_separator = "\t"
}
}This solution consumes fewer resources and memory but brings higher performance in queries and data ingestion.
Fewer Storage Costs
Before: The original table in Hive had 500 fields. It was divided into partitions by day, with 150 million pieces of data per partition. It took 810G to store in HDFS.
After: For data synchronization, we call Spark on YARN using SeaTunnel. It can be finished within 40 minutes, and the ingested data only takes up 270G of storage space.
Less Memory Usage and Higher Performance in Queries
Before: For a GROUP BY query on the foregoing table in Hive, it occupied 720 Cores and 1.44T in YARN and took a response time of 162 seconds.
After: We perform an aggregate query using Hive Catalog in Doris, set exec_mem_limit=16G, and receive the result after 58.531 seconds. We also try and put the table in Doris and conduct the same query in Doris itself, which only takes 0.828 seconds.
The corresponding statements are as follows:
- Query in Hive, response time: 162 seconds.
select count(*),product_no FROM ods.demo_tbl where dt='2023-03-09'
group by product_no;- Query in Doris using Hive Catalog, response time: 58.531 seconds.
set exec_mem_limit=16G;
select count(*),product_no FROM hive.ods.demo_tbl where dt='2023-03-09'
group by product_no;- Query in Doris directly, response time: 0.828 seconds.
select count(*),product_no FROM ods.demo_tbl where dt='2023-03-09'
group by product_no;Faster Data Ingestion
Before: The original table in Hive had 40 fields. It was divided into partitions by day, with 1.1 billion pieces of data per partition. It takes 806G to store in HDFS.
After: For data synchronization, we call Spark on YARN using SeaTunnel. It can be finished within 11 minutes (100 million pieces per minute ), and the ingested data only takes up 378G of storage space.
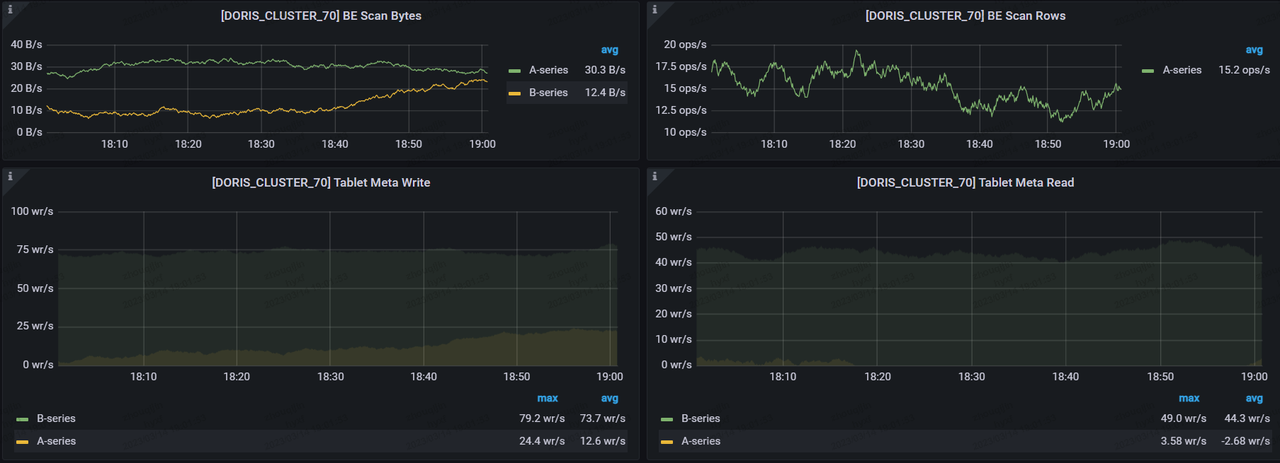
Summary
The key step to building a high-performing risk data mart is to leverage the Multi Catalog feature of Apache Doris to unify the heterogeneous data sources. This not only increases our query speed but also solves a lot of the problems coming with our previous data architecture.
- Deploying Apache Doris allows us to decouple daily batch processing workloads with ad-hoc queries, so they don't have to compete for resources. This reduces the query response time from minutes to seconds.
- We used to build our data ingestion interface based on Elasticsearch clusters, which could lead to a garbage collection jitter when transferring large batches of offline data. When we stored the interface service dataset on Doris, no jitter was found during data writing, and we were able to transfer 10 million rows within 10 minutes.
- Apache Doris has been optimizing itself in many scenarios, including flat tables. As far as we know, compared with ClickHouse, Apache Doris 1.2 is twice as fast in the SSB-Flat-table benchmark and dozens of times faster in the TPC-H benchmark.
In terms of cluster scaling and updating, we used to suffer from a big window of restoration time after configuration revision. But Doris supports hot-swap and easy scaling out, so we can reboot nodes within a few seconds and minimize interruption to users caused by cluster scaling.
(One last piece of advice for you: If you encounter any problems with deploying Apache Doris, don't hesitate to contact the Doris community for help, they and a bunch of SelectDB engineers will be more than happy to make your adaption journey quick and easy.)
Opinions expressed by DZone contributors are their own.
Comments