Spark Salesforce Connector Tutorial Using JDBC
We have a quick look at leveraging Apache Spark to access data in Salesforce via its JDBC connector. Come see how it's done!
Join the DZone community and get the full member experience.
Join For Freeapache spark, the open source big data processing framework, was built for speed, ease and complex analytics. learn how to access salesforce data in spark.
spark has several comprehensive advantages to mapreduce technologies such as hadoop and storm. spark has an advanced directed acyclic graph (dag) pattern that supports cyclic data flows and also allows programmers to develop multi-step pipelines. several tasks can be performed on the same data through in-memory data sharing across dags. using apache spark, one can run up to 100 times faster in memory and that is one of the major reasons most organizations want to use spark.
the tricky part is getting access to data stored in other applications to leverage the power of spark. a common scenario we see is the development of sophisticated transformations in the spark framework with cloud application data, such as salesforce, eloqua or marketo. many developers are turning to the progress datadirect salesforce spark connector and datasource api of spark to integrate salesforce data in spark. sai krishna bobba , a developer evangelist at datadirect, created this quick tutorial below to help you get started with your connection:
accessing salesforce data in spark
- download datadirect salesforce spark connector (jdbc) . for step by step installation instructions please refer our product documentation .
- open your terminal and run the following command to start the spark shell with salesforce jdbc driver path as its parameter:
spark-shell --jars /path_to_driver/sforce.jar-
the shell will start running. at the scala prompt, establish a connection to salesforce and read a table with sql context load function using the following command:
val dataframe_salesforce = sqlcontext.read.format("jdbc").option("url","jdbc:datadirect:sforce://login.salesforce.com;").option("driver","com.ddtek.jdbc.sforce.sforcedriver").option("dbtable","sforce.<table_name>").option("user","<username>").option("password","<password>").option("securitytoken","<security_token>").load() - once you are successfully authenticated the scala shell will display the schema of the table that you requested.
- for future sql queries, you can register the data as a temp table using the following command:
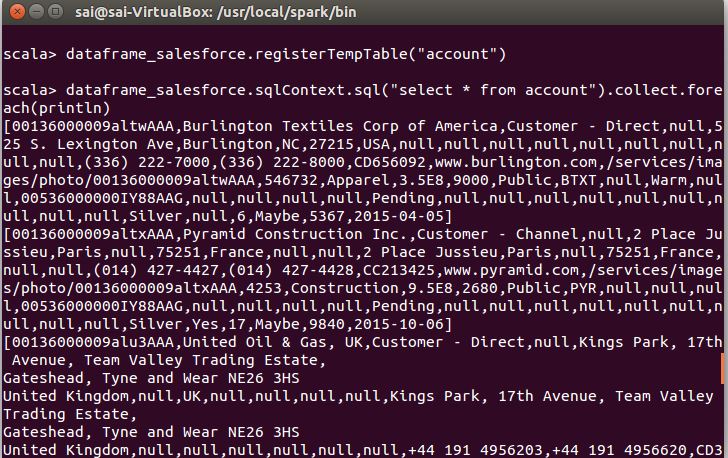
dataframe_salesforce.registertemptable("account")dataframe_salesforce.sqlcontext.sql("select * from account").collect.foreach(println)you should be able to see your result as shown below:
all finished
we hope this tutorial helped you access salesforce data and process your datasets in spark. this demonstration is not limited to salesforce. in fact, you can use the spark’s datasource api with any of the datadirect jdbc spark connectors or datadirect cloud jdbc spark connectors to connect and integrate to over 50+ datasources including saas, relational and big data sources.
please contact us if you have any questions and share your comments below.
Published at DZone with permission of , DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments