Architecture: Software Cost Estimation
As technology changes more rapidly, software cost estimation becomes much more important, especially for legacy systems. Discover a new estimation method.
Join the DZone community and get the full member experience.
Join For FreeEstimating workloads is crucial in mastering software development. This can be achieved either as an ongoing development part of agile teams or in response to tenders as a cost estimate before migration, among other ways.
The team responsible for producing the estimate regularly encounters a considerable workload, which can lead to significant time consumption if the costing is not conducted using the correct methodology.
The measurement figures generated may significantly differ based on the efficiency of the technique employed. Additionally, misconceptions regarding validity requirements and their extent exist.
This paper presents a novel hybrid method for software cost estimation that discretizes software into smaller tasks and uses both expert judgment and algorithmic techniques. By using a two-factor qualification system based on volumetry and complexity, we present a more adaptive and scalable model for estimating software project duration, with particular emphasis on large legacy migration projects.
Table Of Contents
- Introduction
- Survey of Existing SCE
2.1. Algorithmic Methods
2.2. Non-algorithmic Methods
2.3. AI-based Methods
2.4. Agile Estimation Techniques - Hybrid Model Approach
3.1. Discretization
3.2. Dual-factor Qualification System and Effort Calculation Task
3.3. Abacus System - Specific Use Case in Large Legacy Migration Projects
4.1. Importance of SCE in Legacy Migration
4.2. Application of the Hybrid Model
4.3. Results and Findings - Conclusion
Introduction
Software Cost Estimation (SCE) is a systematic and quantitative process within the field of software engineering that involves analyzing, predicting, and allocating the financial, temporal, and resource investments required for the development, maintenance, and management of software systems.
This vital effort uses different methods, models, and techniques to offer stakeholders knowledgeable evaluations of the expected financial, time, and resource requirements for successful software project execution.
It is an essential part of project planning, allowing for a logical distribution of resources and supporting risk assessment and management during the software development life cycle.
Survey of Existing SCE
Algorithmic Methods
COCOMO
Within the field of software engineering and cost estimation, the Constructive Cost Model, commonly referred to as COCOMO, is a well-established and highly regarded concept. Developed by Dr Barry Boehm, COCOMO examines the interplay between software attributes and development costs.
The model operates on a hierarchy of levels, ranging from basic to detailed, with each level providing varying degrees of granularity [1]. The model carefully uses factors such as lines of code and other project details, aligning them with empirical cost estimation data.
Nonetheless, COCOMO is not a stagnant vestige of the past. It has progressed over the years, with COCOMO II encompassing the intricacies of contemporary software development practices, notably amid constantly evolving paradigms like object-oriented programming and agile methodologies [2].
However, though COCOMO’s empirical and methodical approach provides credibility, its use of lines of code as a primary metric attracts criticism. This is particularly true for projects where functional attributes are of greater importance.
Function Point Analysis (FPA)
Navigating away from the strict confines of code metrics, Function Point Analysis (FPA) emerges as a holistic method for evaluating software from a functional perspective.
Introduced by Allan Albrecht at IBM in the late 1970s, FPA aims to measure software by its functionality and the value it provides to users, rather than the number of lines of code.
By categorizing and evaluating different user features — such as inputs, outputs, inquiries, and interfaces — FPA simplifies software complexity into measurable function points [3].
This methodology is particularly effective in projects where the functional output is of greater importance than the underlying code. FPA, which takes a user-focused approach, aligns well with customer demands and offers a concrete metric that appeals to developers and stakeholders alike.
However, it is important to note that the effectiveness of FPA depends on a thorough comprehension of user needs, and uncertainties could lead to discrepancies in estimation.
SLIM (Software Life Cycle Management)
Rooted in the philosophy of probabilistic modeling, SLIM — an acronym for Software Life Cycle Management — is a multifaceted tool designed by Lawrence Putnam [4].
SLIM’s essence revolves around a set of non-linear equations that, when woven together, trace the trajectory of software development projects from inception to completion. Leveraging a combination of historical data and project specifics, SLIM presents a probabilistic landscape that provides insights regarding project timelines, costs, and potential risks.
What distinguishes SLIM is its capability to adapt and reconfigure as projects progress. By persistently absorbing project feedback, SLIM dynamically refines its estimates to ensure they remain grounded in project actualities.
This continuous recalibration is both SLIM’s greatest asset and its primary obstacle. While it provides flexible adaptability, it also requires detailed data recording and tracking, which requires a disciplined approach from project teams.
Non-Algorithmic Methods
Expert Judgement
Treading the venerable corridors of software estimation methodologies, one cannot overlook the enduring wisdom of Expert Judgment [5]. Avoiding the rigorous algorithms and formalities of other techniques, Expert Judgment instead draws upon the accumulated experience and intuitive prowess of industry veterans.
These experienced practitioners, with their wealth of insights gathered from a multitude of projects, have an innate ability to assess the scope, intricacy, and possible difficulties of new ventures. Their nuanced comprehension can bridge gaps left by more strictly data-driven models.
Expert Judgment captures the intangible subtleties of a project artfully, encapsulating the software development craft in ways quantitative metrics may overlook. However, like any art form, Expert Judgment is subject to the quirks of its practitioners. It is vulnerable to personal biases and the innate variability of human judgment.
Analogous Estimation (or Historical Data)
Historical Data estimation, also known as Analogous Estimation, is a technique used to inform estimates for future projects by reviewing past ones. It is akin to gazing in the rearview mirror to navigate the path ahead.
This method involves extrapolating experiences and outcomes of similar previous projects and comparing them to the current one. By doing so, it provides a grounded perspective tempered by real-world outcomes to inform estimates.
Its effectiveness rests on its empirical grounding, with past events often offering reliable predictors for future undertakings. Nevertheless, the quality and relevance of historical data at hand are crucial factors.
A mismatched comparison or outdated data can lead projects astray, underscoring the importance of careful data curation and prudent implementation [6].
Delphi Technique
The method draws its name from the ancient Oracle of Delphi, and it orchestrates a harmonious confluence of experts. The Delphi Technique is a method that aims to reach a consensus by gathering anonymous insights and projections from a group of experts [7].
This approach facilitates a symposium of collective wisdom rather than relying on a singular perspective. Through iterative rounds of feedback, the estimates are refined and recalibrated based on the collective input.
The Delphi Technique is a structured yet dynamic process that filters out outliers and converges towards a more balanced, collective judgment. It is iterative in nature and emphasizes anonymity to curtail the potential pitfalls of groupthink and influential biases.
This offers a milieu where each expert’s voice finds its rightful resonance. However, the Delphi Technique requires meticulous facilitation and patience, as it journeys through multiple rounds of deliberation before arriving at a consensus.
AI-Based Methods
Machine Learning in SCE
Within the rapidly evolving landscape of Software Cost Estimation, Machine Learning (ML) emerges as a formidable harbinger of change [8]. Unshackling from the deterministic confines of traditional methods, ML delves into probabilistic realms, harnessing vast swaths of historical data to unearth hidden patterns and correlations.
By training on diverse project datasets, ML algorithms refine their predictive prowess, adapting to nuances often overlooked by rigid, rule-based systems. This adaptability positions ML as a particularly potent tool in dynamic software ecosystems, where project scopes and challenges continually morph.
However, the effectiveness of ML in SCE hinges on the quality and comprehensiveness of the training data. Sparse or biased datasets can lead the algorithms astray, underlining the importance of robust data curation and validation.
Neural Networks
Venturing deeper into the intricate neural pathways of computational modeling, Neural Networks (NN) stand as a testament to the biomimetic aspirations of artificial intelligence. Structured to mimic the neuronal intricacies of the human brain, NNs deploy layered architectures of nodes and connections to process and interpret information.
In the realm of Software Cost Estimation, Neural Networks weave intricate patterns from historical data, capturing nonlinear relationships often elusive to traditional models [9], [10]. Their capacity for deep learning, especially with the advent of multi-layered architectures, holds immense promise for SCE’s complex datasets.
Yet, the very depth that lends NNs their power can sometimes shroud them in opacity. Their "black box" nature, combined with susceptibility to overfitting, necessitates meticulous training and validation to ensure reliable estimations. Also, the recent discovery of ”Grokking” suggests that this field could yield fascinating new findings [11].
Genetic Algorithms
Drawing inspiration from the very fabric of life, Genetic Algorithms (GAs) transpose the principles of evolution onto computational canvases. GAs approach Software Cost Estimation as an optimization puzzle, seeking the fittest solutions through processes mimicking natural selection, crossover, and mutation.
By initiating with a diverse population of estimation strategies and iteratively refining them through evolutionary cycles, GAs converge towards more optimal estimation models. Their inherent adaptability and explorative nature make them well-suited for SCE landscapes riddled with local optima [12].
However, the stochastic essence of GAs means that their results, while generally robust, may not always guarantee absolute consistency across runs. Calibration of their evolutionary parameters remains crucial to strike a balance between exploration and exploitation.
Agile Estimation Techniques
Agile methodologies, originally formulated to address the challenges of traditional software development processes, introduced a paradigm shift in how projects are managed and products are delivered.
Integral to this approach is the iterative nature of development and the emphasis on collaboration among cross-functional teams. This collaborative approach extends to the estimation processes in Agile.
Instead of trying to foresee the entirety of a project’s complexity at its outset, Agile estimation techniques are designed to evolve, adapting as the team gathers more information.
Story Points
Instead of estimating tasks in hours or days, many Agile teams use story points to estimate the relative effort required for user stories. Story points consider the complexity, risk, and effort of the task.
By focusing on relative effort rather than absolute time, teams avoid the pitfalls of under or over-estimating due to unforeseen challenges or dependencies. Over several iterations, teams develop a sense of their ”velocity” — the average number of story points they complete in an iteration — which aids in forecasting [13].
Planning Poker
One of the most popular Agile estimation techniques is Planning Poker. Team members, often inclusive of developers, testers, and product owners, collaboratively estimate the effort required for specific tasks or user stories.
Using a set of cards with pre-defined values (often Fibonacci sequence numbers), each member selects a card representing their estimate. After revealing their cards simultaneously, discrepancies in estimates are discussed, leading to consensus [14], [15].
The beauty of Planning Poker lies in its ability to combine individual expert opinions and arrive at an estimate that reflects the collective wisdom of the entire team. The process also uncovers potential challenges or uncertainties, leading to more informed decision-making.
Continuous Reevaluation
A hallmark of Agile estimation is its iterative nature. As teams proceed through sprints or iterations, they continually reassess and adjust their estimates based on new learnings and the actual effort expended in previous cycles. This iterative feedback loop allows for more accurate forecasting as the project progresses [14].
Hybrid Model Approach
We aim to present a novel model that incorporates both expert judgment and algorithmic approaches. While considering the expert approach, it is worth noting that it may involve subjective evaluations, possibly exhibiting inconsistencies amongst different experts.
Besides, its dependence on the experience and availability of experts has the potential to introduce biases due to cognitive heuristics and over-reliance on recent experiences.
On the other hand, an algorithmic approach may require significant expertise to be applied correctly and may focus on certain parameters, such as the number of lines of code, which may not be relevant.
Therefore, the aim here is to propose a model that is independent of the programming language and considers multiple factors, such as project, hardware, and personnel attributes.
Task Discretization
In the constantly evolving field of software engineering, the practice of task discretization has become firmly established as a mainstay [16]. This approach stresses the importance of breaking down larger software objectives into manageable, bite-sized units.
By acknowledging the inherent discreetness of software components — from screens and APIs to SQL scripts — a methodical breakdown emerges as a practical requirement [17]. Such an approach allows you to define your software in consistent modules, composed of consistent elements. It is crucial to have homogeneous elements for estimation, to enable the estimation team to easily understand what they are estimating and avoid the need to adapt to the elements. Those elements will be referred to as ”tasks” throughout the paper.
Also, addressing tasks at an individual level improves accuracy, while the detail it provides promotes flexibility, allowing for iterative adjustments that accommodate a project’s changing requirements.
Such an approach guarantees that each component’s distinct characteristics are appropriately and independently considered. This method of discretization has several advantages. Addressing tasks at an individual level enhances accuracy, while the granularity it brings forth promotes flexibility, enabling iterative adjustments that accommodate a project’s fluid requirements.
Conversely, a detailed comprehension of each task’s complexities enables the prudent allocation of resources and fine-tuning skills to where they are most necessary. Nevertheless, this level of detail is not without drawbacks.
Despite providing accuracy, deconstructing tasks into their constituent parts may result in administrative challenges, particularly in extensive projects. The possibility of neglecting certain tasks, albeit minor, is ever-present. Moreover, an excessively detailed approach can sometimes obscure wider project aims, resulting in decision-making delays, which is often referred to as ”analysis paralysis”.
Dual-Factor Qualification System and Effort Calculation Task Discretization
With the delineation of tasks exhibiting homogeneous attributes, it becomes imperative to pinpoint generic determinants for allocating appropriate effort.
Upon meticulous scrutiny, two pivotal factors have been discerned: Complexity and Volumetry [1], [18].
Complexity serves as a metric to gauge the requisite technical acumen for task execution. For instance, within a user interface, the incorporation of a dynamic table may warrant the classification of the task as possessing high complexity due to its intricate requirements.
Volumetry delineates the volume or quantum of work involved. To illustrate, in the context of a user interface, the presence of an extensive forty-field form might be indicative of a task with significant volumetry due to the sheer magnitude of its components.
Both Complexity and Volumetry are in the interval [1 − 5] and must be integers. Now we will define the Effort (E), which is calculated as follows:
E = C ∗V
Where C is the Complexity and V the Volumetry. We utilize multiplication in this calculation in order to establish a connection between high Complexity and high Volumetry. This enables us to account for potential risks when both evaluation criteria increase simultaneously while maintaining accuracy for tasks with lower coefficients. By using a simple product of the two intervals of C and V, we obtain the following possibilities for E:
[1, 2, 3, 4, 5, 6, 8, 9, 10, 12, 15, 16, 20, 25]
Abacus System
Now that an effort has been obtained, the corresponding number of days can be identified for each effort value. This stage is critical and requires the intervention of an expert with knowledge of the target architecture and technologies.
However, the model permits this crucial resource to intervene only once when establishing these values.
Use of an Algorithm
To establish these values, we propose using an algorithm to enhance accuracy and prevent errors.
It can be utilized to simulate data sets using three distinct models and two starting criteria:
- The maximal number of days (which is linked with an effort of 25)
- The gap padding between values
We utilized three distinct models to enable the experts and estimation team to select from different curve profiles that may yield varied characteristics, such as precision, risk assessment, and padding size, for ideal adaptation to the requirements. Three distinct mathematical models were hypothesized to explicate the relationship: linear, quadratic, and exponential. Each model postulates a unique behavior of effort-to-days transformation:
- The Linear Model postulates a direct proportionality between effort and days.
- The Quadratic Model envisages an accelerated growth rate, invoking polynomial mathematics.
- The Exponential Model projects an exponential surge, signifying steep escalation for higher effort values.
Those models can be adjusted to more accurately meet estimation requirements. Finally, we obtain the following code:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd # Importing pandas for tabular display
# Fixed effort values
efforts = np.array([1, 2, 3, 4, 5, 6, 8, 9, 10, 12, 15, 16, 20, 25])
# Parameters
Max_days = 25
Step_Days = 0.25
def linear_model(effort, max_effort, max_days, step_days):
slope = (max_days - step_days) / max_effort
return slope * effort + step_days - slope
def quadratic_model(effort, max_effort, max_days, step_days):
scale = (max_days - step_days) / (max_effort + 0.05 * max_effort**2)
return scale * (effort + 0.05 * effort**2)
def exponential_model(effort, max_effort, max_days, step_days):
adjusted_max_days = max_days - step_days + 1
base = np.exp(np.log(adjusted_max_days) / max_effort)
return step_days + base ** effort - 1
def logarithmic_model(effort, max_effort, max_days, step_days):
scale = (max_days - step_days) / np.log(max_effort + 1)
return scale * np.log(effort + 1)
# Rounding to nearest step
def round_to_step(value, step):
return round(value / step) * step
linear_days = np.array([round_to_step(linear_model(e, efforts[-1], Max_days, Step_Days), Step_Days) for e in efforts])
quadratic_days = np.array([round_to_step(quadratic_model(e, efforts[-1], Max_days, Step_Days), Step_Days) for e in efforts])
exponential_days = np.array([round_to_step(exponential_model(e, efforts[-1], Max_days, Step_Days), Step_Days) for e in efforts])
logarithmic_days = np.array([round_to_step(logarithmic_model(e, efforts[-1], Max_days, Step_Days), Step_Days) for e in efforts])
# Plot
plt.figure(figsize=(10,6))
plt.plot(efforts, linear_days, label="Linear Model", marker='o')
plt.plot(efforts, quadratic_days, label="Quadratic Model", marker='x')
plt.plot(efforts, exponential_days, label="Exponential Model", marker='.')
plt.plot(efforts, logarithmic_days, label="Logarithmic Model", marker='+')
plt.xlabel("Effort")
plt.ylabel("Days")
plt.title("Effort to Days Estimation Models")
plt.legend()
plt.grid(True)
plt.show()
# Displaying data in table format
df = pd.DataFrame({
'Effort': efforts,
'Linear Model (Days)': linear_days,
'Quadratic Model (Days)': quadratic_days,
'Exponential Model (Days)': exponential_days,
'Logarithmic Model (Days)': logarithmic_days
})
display(df)Listing 1. Days generation model code, Python
Simulations
Let us now examine a practical example of chart generation. As previously stated in the code, the essential parameters ”Step Days” and ”Max days” have been set to 0.25 and 25, respectively. The results generated by the three models using these parameters are presented below.
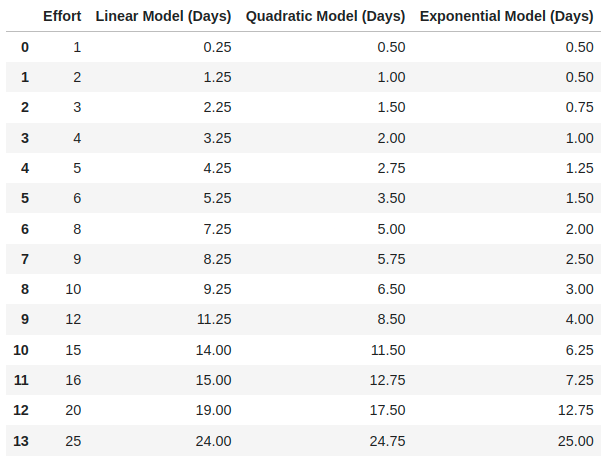
Figure 1: Effort to days estimation models - Data
Below is a graphical representation of these results:
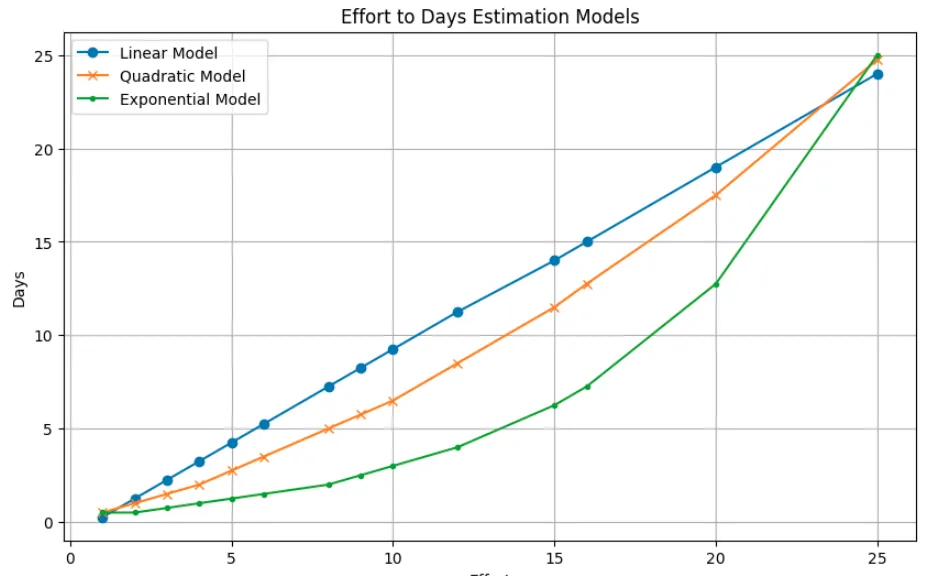
Figure 2: Effort to days estimation models — graphical representation
The graph enables us to distinguish the variation in ”compressions” amongst the three models, which will yield distinct traits, including accuracy in minimal forces or strong association among values.
Specific Use Case in Large Legacy Migration Projects
Now that the model has been described, a specific application will be proposed in the context of a migration project. It is believed that this model is well-suited to projects of this kind, where teams are confronted with a situation that appears unsuited to the existing standard model, as explained in the first part.
Importance of SCE in Legacy Migration
Often, migration projects are influenced by their cost. The need to migrate is typically caused by factors including:
- More frequent regressions and side effects
- Difficulty in locating new resources for outdated technologies
- Specialist knowledge concentration
- Complexity in integrating new features
- Performance issues
All potential causes listed above increase cost and/or risk. It may be necessary to consider the migration of the problematic technological building block(s). Implementation depends mainly on the cost incurred, necessitating an accurate estimate [19].
However, it is important to acknowledge that during an organization’s migration process, technical changes must be accompanied by human and organizational adjustments.
Frequently, after defining the target architecture and technologies, the organization might lack the necessary experts in these fields. This can complicate the ”Expert Judgement” approach. Algorithmic approaches do not appear to be suitable either, as they necessitate knowledge and mastery but also do not necessarily consider all the subtleties that migrations may require in terms of redrawing the components to be migrated.
Additionally, the number of initial lines of code is not consistently a reliable criterion. Finally, AI-based methodologies seem to still be in their formative stages and may be challenging to implement and master for these organizations.
That is why our model appears suitable, as it enables present teams to quantify the effort and then seek advice from an expert in the target technologies to create the estimate, thus obtaining an accurate figure. It is worth noting that this estimation merely encompasses the development itself and disregards the specification stages and associated infrastructure
costs.
Application of the Hybrid Model
We shall outline the entire procedure for implementing our estimation model. The process comprises three phases: Initialization, Estimation, and Finalization.
Initialization
During this phase, the technology building block to be estimated must first be deconstructed. It needs to be broken down into sets of unified tasks.
For example, an application with a GWT front-end calling an AS400 database could be broken down into two main sets:
- Frontend: Tasks are represented by screens.
- Backend: Tasks are represented by APIs.
We can then put together the estimation team. It does not need to be a technical expert in the target technology but should be made up of resources from the existing project, preferably a technical/functional pair, who can assess the complementarity of each task with the two visions.
This team will be able to start listing the tasks for the main assemblies identified during the discretization process.
Estimation
We now have a team ready to assign Complexity and Volumetry values to the set of tasks to be identified. In parallel with this association work, we can begin to set values for the days to be associated with the effort.
This work may require an expert in the target technologies and also members of the estimation team to quantify some benchmark values on the basis of which the expert can take a critical look and extend the results to the whole chart.
At the end of this phase, we have a days/effort correspondence abacus and a list of tasks with an associated effort value.
Finalization
The final step is to calculate the conversion between effort and days using the abacus to obtain a total number of days. Once the list of effort values has been obtained, a risk analysis can
be carried out using the following criteria:
- The standard deviation of the probability density curve of efforts
- Analysis of whether certain ”zones” of the components concentrate high effort values
- The number of tasks with an effort value greater than 16
Depending on these criteria, specific measures can be taken in restricted areas.
Results and Findings
Finally, we arrive at the following process, which provides a hybrid formalization between expert judgment and algorithmic analysis.
The method seems particularly well suited to the needs of migration projects, drawing on accessible resources and not requiring a high level of expertise.
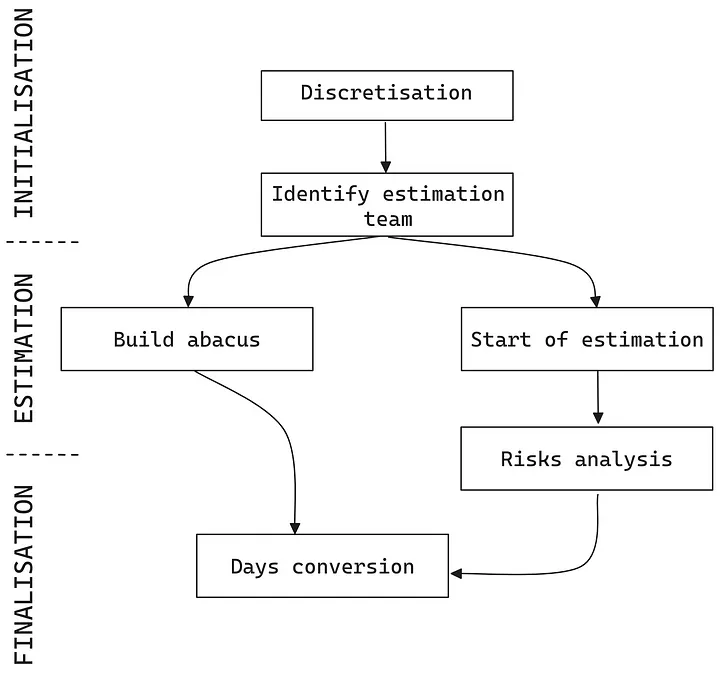
Figure 3: Complete process of the hybrid model
Another representation, based on the nature of elements, could be the following:
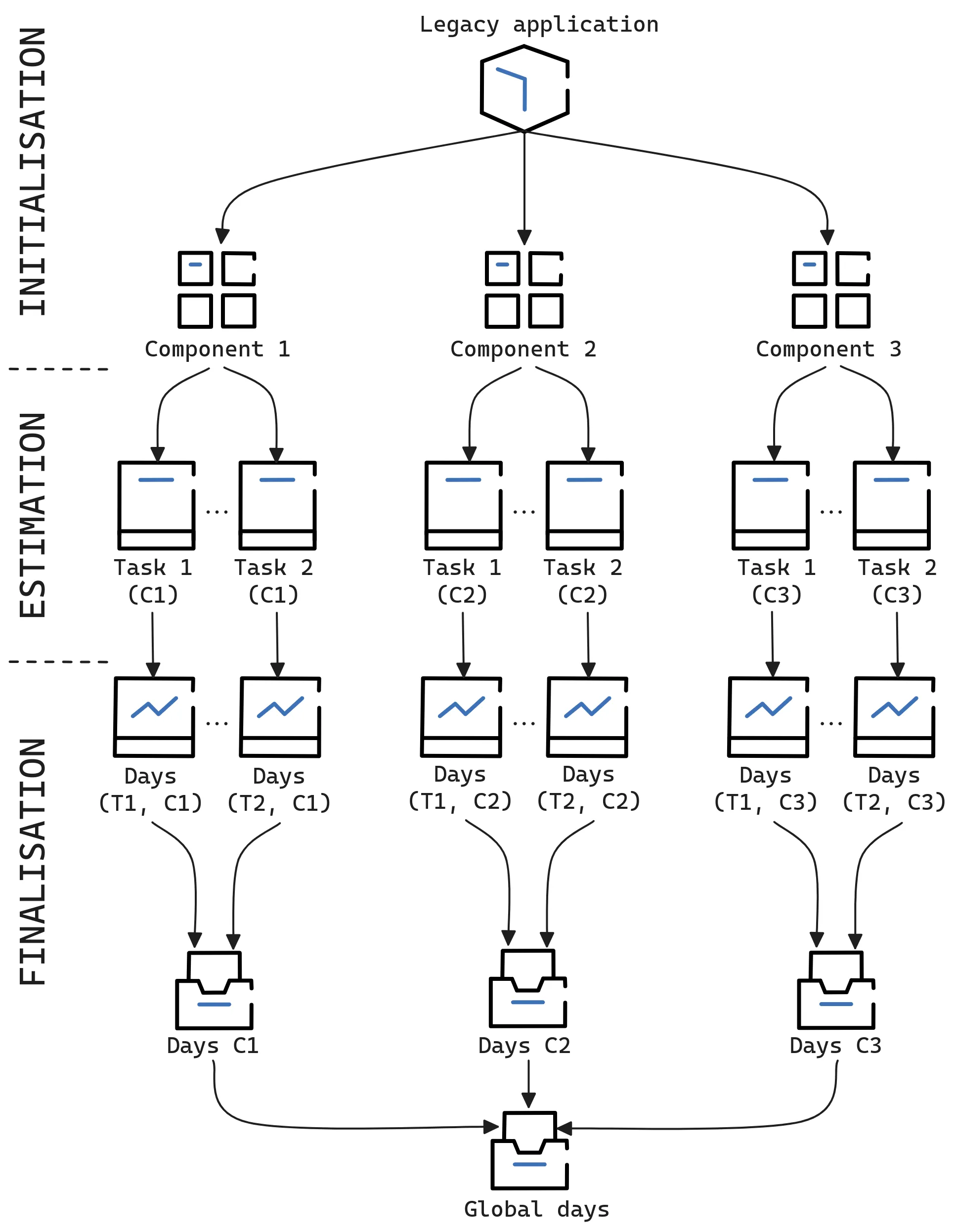
Figure 4: Complete process of the hybrid model
Conclusion
In conclusion, our model presents a practical and flexible approach for estimating the costs involved in large legacy migration projects.
By combining elements of expert judgment with a structured, algorithmic analysis, this model addresses the unique challenges that come with migrating outdated or complex systems.
It recognizes the importance of accurately gauging the effort and costs, considering not just the technical aspects but also the human and organizational shifts required.
The three-phase process — Initialization, Estimation, and Finalization — ensures a comprehensive evaluation, from breaking down the project into manageable tasks to conducting a detailed risk analysis. This hybrid model is especially beneficial for teams facing the daunting task of migration, providing a pathway to make informed decisions and prepare effectively for the transition.
Through this approach, organizations can navigate the intricacies of migration, ensuring a smoother transition to modern, more efficient systems.
In light of the presented discussions and findings, it becomes evident that legacy migration projects present a unique set of challenges that can’t be addressed by conventional software cost estimation methods alone.
The hybrid model as proposed serves as a promising bridge between the more heuristic expert judgment approach and the more structured algorithmic analysis, offering a balanced and adaptive solution. The primary strength of this model lies in its adaptability and its capacity to leverage both institutional knowledge and specific expertise in target technologies.
Furthermore, the model’s ability to deconstruct a problem into sets of unified tasks and estimate with an appropriate level of granularity ensures its relevance across a variety of application scenarios. While the current implementation of the hybrid model shows potential, future research and improvements can drive its utility even further:
- Empirical validation: As with all models, empirical validation on a diverse set of migration projects is crucial. This would not only validate its effectiveness but also refine its accuracy.
(We are already working on it.) - Integration with AI: Although AI-based methodologies for software cost estimation are still nascent, their potential cannot be overlooked. Future iterations of the hybrid model could integrate machine learning for enhanced predictions, especially when large datasets from past projects are available.
- Improved risk analysis: The proposed risk analysis criteria provide a solid starting point. However, more sophisticated risk models, which factor in unforeseen complexities and uncertainties inherent to migration projects, could be integrated into the model.
- Tooling and automation: Developing tools that can semiautomate the process described would make the model more accessible and easier to adopt by organizations.
In conclusion, the hybrid model presents a notable advancement in the realm of software cost estimation, especially for legacy migration projects. However, as with all models, it’s an evolving entity, and continued refinement will only enhance its applicability and effectiveness.
References
[1] Barry W. Boehm. Software engineering economics. IEEE Transactions on Software Engineering, SE-7(1):4–21, 1981.
[2] Barry W. Boehm, Chris Abts, A. Winsor Brown, Sunita Chulani, Bradford K. Clark, Ellis Horowitz, Ray Madachy, Donald J. Reifer, and Bert Steece. Cost models for future software life cycle processes: Cocomo 2.0. Annals of Software Engineering, 1(1):57–94, 2000.
[3] International Function Point Users Group (IFPUG). Function Point Counting Practices Manual. IFPUG, 2000. FPCPM.
[4] L.H. Putnam. A general empirical solution to the macro software sizing and estimating problem. IEEE Transactions on Software Engineering, 4:345–361, 1978.
[5] R.T. Hughes. Expert judgment as an estimating method. Information and Software Technology, 38(2):67–75, 1996.
[6] Christopher Rush and Rajkumar Roy. Expert judgment in cost estimating: Modelling the reasoning process. Unknown Journal Name.
[7] N. Dalkey. An experimental study of group opinion: the Delphi method. Futures, 1(5):408–426, 1969.
[8] Yibeltal Assefa, Fekerte Berhanu, Asnakech Tilahun, and Esubalew Alemneh. Software effort estimation using machine learning algorithm. In 2022 International Conference on Information and Communication Technology for Development for Africa (ICT4DA), pages 163–168, 2022.
[9] A. Venkatachalam. Software cost estimation using artificial neural networks. In Proc. Int. Conf. Neural Netw. (IJCNN-93-Nagoya Japan), volume 1, pages 987–990, Oct 1993.
[10] R. Poonam and S. Jain. Enhanced software effort estimation using multi-layered feed forward artificial neural network technique. Procedia Computer Science, 89:307–312, 2016.
[11] Alethea Power, Yuri Burda, Harri Edwards, et al. Grokking: Generalization beyond overfitting on small algorithmic datasets. arXiv preprint arXiv:2201.02177, 2022.
[12] B.K. Singh and A.K. Misra. Software effort estimation by genetic algorithm tuned parameters of modified constructive cost model for NASA software projects. International Journal of Computer Applications, 59:22–26, 2012.
[13] K. Hrvoje and S. Gotovac. Estimating software development effort using Bayesian networks. In 2015 23rd International Conference on Software, Telecommunications and Computer Networks, pages 229–233, Split, Croatia, September 16–18 2015.
[14] M. Cohn. Agile Estimating and Planning. Prentice Hall PTR, 2005.
[15] Saurabh Bilgaiyan, Santwana Sagnika, Samaresh Mishra, and Madhabananda Das. A systematic review on software cost estimation in agile software development. Journal of Engineering Science and Technology Review, 10(4):51–64, 2017.
[16] S. McConnell. Software Estimation: Demystifying the Black Art. Microsoft Press, 2006.
[17] C. Szyperski. Component Software: Beyond Object-Oriented Programming. Addison-Wesley, 2nd edition, 2002.
[18] N. E. Fenton and S. L. Pfleeger. Software Metrics: A Rigorous and Practical Approach. PWS Publishing Co., 1997.
[19] Harry M. Sneed and Chris Verhoef. Cost-driven software migration: An experience report. Software: Practice and Experience, 2020.
Published at DZone with permission of Pier-Jean MALANDRINO. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments