Using SingleStore and WebAssembly for Sentiment Analysis of Stack Overflow Comments
In this article, learn how to use SingleStore and WebAssembly to perform sentiment analysis of Stack Overflow comments.
Join the DZone community and get the full member experience.
Join For FreeIn this article, we'll see how to use SingleStore and WebAssembly to perform sentiment analysis of Stack Overflow comments. We'll use some existing WebAssembly code that has already been prepared and hosted in a cloud environment.
The notebook file used in this article is available on GitHub.
Introduction
In this article, we'll take an existing SingleStore Labs project and demonstrate the ease with which it can be deployed and run on SingleStore Cloud. The original project was developed before SingleStore provided support for notebooks in the cloud portal. We'll see the ease with which we can migrate and consolidate the code.
Create a SingleStore Cloud Account
A previous article showed the steps to create a free SingleStore Cloud account. We'll use the Standard Tier, select Google Cloud (GCP), and take the default names for the Workspace Group and Workspace.
Import the Notebook
We'll download the notebook from GitHub.
From the left navigation pane in the SingleStore cloud portal, we'll select DEVELOP > Data Studio.
In the top right of the web page, we'll select New Notebook > Import From File. We'll use the wizard to locate and import the notebook we downloaded from GitHub.
Run the Notebook
After checking that we are connected to our SingleStore workspace, we'll run the cells one by one.
We'll begin by installing the necessary libraries and importing dependencies.
Next, we'll create the database:
DROP DATABASE IF EXISTS demo;
CREATE DATABASE IF NOT EXISTS demo;We'll now create a link to a Google Cloud Storage (GCS) bucket for our Stack Overflow data and WebAssembly files:
CREATE LINK IF NOT EXISTS gcs_wasm AS GCS CREDENTIALS '{}'
DESCRIPTION 'wasm and wit examples';Next, we'll create the table to store the Stack Overflow comments:
DROP TABLE IF EXISTS comments;
CREATE TABLE IF NOT EXISTS comments (
id INT,
text TEXT,
creation_date TIMESTAMP,
score INT,
score_bucket AS (score - (score % 10)) PERSISTED INT,
KEY (score) USING CLUSTERED COLUMNSTORE,
SHARD KEY ()
);And we'll now create a Pipeline to ingest those comments into the table:
CREATE PIPELINE sowasm AS LOAD DATA LINK gcs_wasm 'stackoverflow-wasm'
INTO TABLE comments
FIELDS TERMINATED BY ','
ENCLOSED BY '\"'
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
STARTING BY '';Before starting the Pipeline, we'll test it:
TEST PIPELINE sowasm LIMIT 1;Example output:
+-----------+---------------------------------------------------------------------------------------------------------------------------------+---------------------+-------+
| id | text | creation_date | score |
+-----------+---------------------------------------------------------------------------------------------------------------------------------+---------------------+-------+
| 118711035 | because that function might use also other types of Collections, not only Map...so this is why I made it as general as possible | 2021-04-19 09:56:31 | 0 |
+-----------+---------------------------------------------------------------------------------------------------------------------------------+---------------------+-------+We'll now start the Pipeline:
START PIPELINE sowasm;We'll check the Pipeline status, as follows:
SELECT pipeline_name, batch_state, batch_time, rows_per_sec, mb_per_sec
FROM information_schema.pipelines_batches_summary;Example output:
+---------------+-------------+------------+--------------------+-------------------+
| pipeline_name | batch_state | batch_time | rows_per_sec | mb_per_sec |
+---------------+-------------+------------+--------------------+-------------------+
| sowasm | In Progress | 41.510348 | 448796.28568760736 | 88.36874162076406 |
| sowasm | Succeeded | 14.659567 | 0.5457187105185304 | 501.912665974377 |
+---------------+-------------+------------+--------------------+-------------------+We'll also check how many files have been loaded so far, as follows:
SELECT pipeline_name, file_state, COUNT(*)
FROM information_schema.pipelines_files
GROUP BY 1, 2;Example output:
+---------------+------------+----------+
| pipeline_name | file_state | COUNT(*) |
+---------------+------------+----------+
| sowasm | Unloaded | 16 |
+---------------+------------+----------+It may take a few minutes to complete the data loading. We'll keep re-running the above command until we see the file_state as Loaded.
+---------------+------------+----------+
| pipeline_name | file_state | COUNT(*) |
+---------------+------------+----------+
| sowasm | Loaded | 16 |
+---------------+------------+----------+If we now check the number of rows in the comments table:
SELECT COUNT(*) FROM comments;It should be:
82037742Next, we'll optimize the table:
OPTIMIZE TABLE comments FULL;Now, we'll create the sentiment function in SingleStore:
DROP FUNCTION IF EXISTS sentiment;
CREATE FUNCTION sentiment RETURNS TABLE AS WASM
FROM LINK gcs_wasm 'wasm-modules/sentimentable.wasm'
WITH WIT FROM LINK gcs_wasm 'wasm-modules/sentimentable.wit';And we'll test the function using a simple phrase:
SELECT * FROM sentiment('The movie was great');Example output:
+--------------------+--------------------+----------+--------------------+
| compound | positive | negative | neutral |
+--------------------+--------------------+----------+--------------------+
| 0.6248933269389457 | 0.5774647887323944 | 0 | 0.4225352112676057 |
+--------------------+--------------------+----------+--------------------+The function was built using VADER, which can consider capitalization, so we'll try:
SELECT * FROM sentiment('The movie was GREAT!');Example output:
+--------------------+--------------------+----------+---------------------+
| compound | positive | negative | neutral |
+--------------------+--------------------+----------+---------------------+
| 0.7290259049799065 | 0.6307692307692307 | 0 | 0.36923076923076925 |
+--------------------+--------------------+----------+---------------------+We can see that the values have changed, showing a stronger positive sentiment expressed by capitalization.
Now, we'll use the sentiment function over the Stack Overflow data. The following query categorizes comments by their score_bucket, calculates the positive and negative sentiment ranges for each bucket, and filters out buckets that do not meet specific thresholds for positive and negative sentiments or a minimum comment count:
SELECT
score_bucket,
COUNT(*) AS num_comments,
ABS(MIN(sentiment.compound)) AS 'negative',
MAX(sentiment.compound) AS 'positive'
FROM (
SELECT score_bucket, text
FROM comments
WHERE score >= 10
) AS c
JOIN sentiment(c.text) AS sentiment
GROUP BY 1
HAVING positive > 0 AND negative > 0 AND num_comments > 20
ORDER BY 1 ASC;Example output:
+--------------+--------------+--------------------+---------------------+
| score_bucket | num_comments | negative | positive |
+--------------+--------------+--------------------+---------------------+
| 10 | 115285 | 0.9994079336366717 | 0.9884804181816502 |
| 20 | 27409 | 0.9888823100791507 | 0.9892404342635115 |
| 30 | 12064 | 0.9821512068585552 | 0.9877005097673762 |
| 40 | 6701 | 0.9843907526148696 | 0.9879442138133854 |
| 50 | 4130 | 0.9578388745735287 | 0.9771454595448407 |
| 60 | 2737 | 0.9760934140752651 | 0.9729132860697197 |
| 70 | 1871 | 0.9706903352612597 | 0.9880242850306352 |
| 80 | 1382 | 0.9652000828396454 | 0.9762188560813158 |
| 90 | 961 | 0.923147976982903 | 0.9493088246302036 |
| 100 | 616 | 0.9304284852393788 | 0.9450887908327322 |
| 110 | 558 | 0.9493549089508792 | 0.9632429421826448 |
| 120 | 426 | 0.9002836209452251 | 0.9677479586749276 |
| 130 | 370 | 0.9162896416215123 | 0.9632354331654686 |
| 140 | 311 | 0.9021745222664633 | 0.9586716231397892 |
| 150 | 238 | 0.8675398479551882 | 0.9431759585204077 |
| 160 | 222 | 0.8531496240723568 | 0.9578995844532326 |
| 170 | 178 | 0.9747041185348985 | 0.9147007023988873 |
| 180 | 140 | 0.9169412377108535 | 0.8390091580666769 |
| 190 | 121 | 0.9245951335534447 | 0.9182147494752572 |
| 200 | 113 | 0.8816546429851182 | 0.9646083962735071 |
| 210 | 104 | 0.9000703207408192 | 0.9656662124414448 |
| 220 | 75 | 0.9540880207894837 | 0.9290884711557326 |
| 230 | 64 | 0.9366897688124777 | 0.8845412417221543 |
| 240 | 63 | 0.69959689416212 | 0.8798820901453436 |
| 250 | 69 | 0.885989313829565 | 0.9118030994059687 |
| 260 | 44 | 0.732963834521151 | 0.8451256880345008 |
| 270 | 48 | 0.6002989705424076 | 0.8977248037806889 |
| 280 | 37 | 0.7649686210234002 | 0.8174929079535046 |
| 290 | 27 | 0.7212708611789033 | 0.5410993951859938 |
| 300 | 21 | 0.8933580311460599 | 0.9118030994059688 |
| 310 | 21 | 0.9006976990391564 | 0.6248933269389456 |
| 320 | 23 | 0.5006589854488329 | 0.8396107297645051 |
| 330 | 22 | 0.5287984420596952 | 0.47069267569978684 |
+--------------+--------------+--------------------+---------------------+We could save the result of the query in a variable and use it from Python. Alternatively, we could run the query as follows:
df = pd.read_sql("""
SELECT
score_bucket,
COUNT(*) AS num_comments,
ABS(MIN(sentiment.compound)) AS 'negative',
MAX(sentiment.compound) AS 'positive'
FROM (
SELECT score_bucket, text
FROM comments
WHERE score >= 10
) AS c
JOIN sentiment(c.text) AS sentiment
GROUP BY 1
HAVING positive > 0 AND negative > 0 AND num_comments > 20
ORDER BY 1 ASC;
""", con = db_connection)
df.head()And then plot the data:
fig = px.scatter(
df,
x = "score_bucket",
y = ["positive", "negative"],
trendline = "ols",
labels = {
"score_bucket": "Comment Score",
"value": "polarization",
}
)
fig.update_layout(
title = "Comment Score vs. Sentiment Polarisation",
xaxis_title = "Comment Score",
yaxis_title = "Sentiment Polarisation"
)
fig.show()Example output is shown in Figure 1.
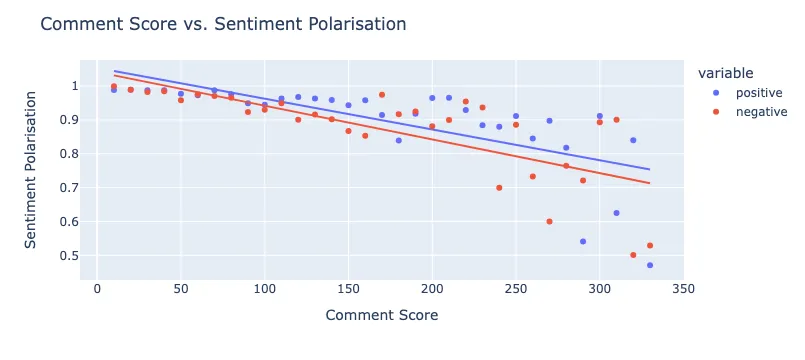
Figure 1: Comment Score vs. Sentiment Polarization
Figure 1 visually explores how positive and negative sentiment scores vary with comment scores. It can help identify whether comments with higher scores tend to have more polarized sentiment (either more positive or negative) and if there's a general trend or correlation between comment scores and sentiment polarity.
Summary
In this article, we've used several very useful SingleStore features, such as Pipelines to ingest data from an external source, and an external WebAssembly function loaded into the database to perform sentiment analysis. We've also been able to run both SQL and Python code from the cloud portal without the need to use any other tools.
Acknowledgments
I thank Bailey Hayes for developing the sentiment analysis example and documentation in the GitHub repo.
Published at DZone with permission of Akmal Chaudhri. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments