Building a Simple RAG Application With Java and Quarkus
With Java’s versatility and Quarkus’s cloud-native optimizations, you can build high-performance, scalable applications that seamlessly integrate AI-driven features.
Join the DZone community and get the full member experience.
Join For FreeIntroduction to RAG and Quarkus
Retrieval-augmented generation (RAG) is a technique that enhances AI-generated responses by retrieving relevant information from a knowledge source. In this tutorial, we’ll build a simple RAG-powered application using Java and Quarkus (a Kubernetes-native Java framework). Perfect for Java beginners!
Why Quarkus?
Quarkus provides multiple LangChain4j extensions to simplify AI application development, especially RAG implementation by providing an Easy RAG module for building end-to-end RAG pipelines. Easy RAG acts as a bridge, connecting the retrieval components (like your document source) with the LLM interaction within the LangChain4j framework.
Instead of manually orchestrating the retrieval, context injection, and LLM call, easy RAG handles these steps behind the scenes, reducing the amount of code you need to write. This abstraction allows you to focus on defining your data sources and crafting effective prompts, while easy RAG takes care of the more technical details of the RAG workflow.
Within a Quarkus application, this means you can quickly set up a RAG endpoint by simply configuring your document source and leveraging easy RAG to retrieve and query. This tight integration with LangChain4j also means you still have access to the more advanced features of LangChain4j if you need to customize or extend your RAG pipeline beyond what easy RAG provides out of the box.
Essentially, easy RAG significantly lowers the barrier to entry for building RAG applications in a Quarkus environment, allowing Java developers to rapidly prototype and deploy solutions without getting bogged down in the lower-level implementation details. It provides a convenient and efficient way to leverage the power of RAG within the already productive Quarkus and LangChain4j ecosystem.
Step 1: Set Up Your Quarkus Project
Create a new Quarkus project using the Maven command:
mvn io.quarkus:quarkus-maven-plugin:3.18.4:create \
-DprojectGroupId=com.devzone \
-DprojectArtifactId=quarkus-rag-demo \
-Dextensions='langchain4j-openai, langchain4j-easy-rag, websockets-next'This generates a project with a simple AI bot with easy RAG integration. Find the solution project here. The AI service refers to Open AI by default. You can replace it with local Ollama using the quarkus-langchain4j-ollama extension rather than quarkus-langchain4j-openai.
Step 2: Explore the Generated AI Service
Open the Bot.java file in the src/main/java/com/devzone folder. The code should look like this:
@RegisterAiService // no need to declare a retrieval augmentor here, it is automatically generated and discovered
public interface Bot {
@SystemMessage("""
You are an AI named Bob answering questions about financial products.
Your response must be polite, use the same language as the question, and be relevant to the question.
When you don't know, respond that you don't know the answer and the bank will contact the customer directly.
""")
String chat(@UserMessage String question);
}@RegisterAiServiceregisters the AI service as an interface.@SystemMessagedefines the initial instruction and scope that will be sent to the LLM as the first message.@UserMessagedefines prompts (e.g., user input) and usually combines requests and expected responses’ format.
You can change the definitions regarding your LLMs and prompt engineering practices.
Step 3: Lean How to Integrate Easy RAG Into AI Service
When the quarkus-langchain4j-easy-rag extension is added to the Quarkus project, the only steps required to ingest documents into an embedding store are to include a dependency for an embedding model and specify a single configuration property, quarkus.langchain4j.easy-rag.path, which points to a local directory containing your documents.
During application startup, Quarkus automatically scans all files within the specified directory and ingests them into an in-memory embedding store, eliminating the need for manual setup or complex configuration.
Open the application.properties file in the src/main/resources folder. You should find the quarkus.langchain4j.easy-rag.path=easy-rag-catalog property.
Navigate to the easy-rag-catalog folder in the project root directory. You should find four documents generated with different file formats such as txt, odt, and pdf files.
.
|____retirement-money-market.txt
|____elite-money-market-account.odt
|____smart-checking-account.pdf
|____standard-saving-account.txtThis approach significantly reduces the overhead typically associated with implementing RAG pipelines, allowing developers to focus on building their application logic rather than managing the intricacies of document ingestion and embedding storage.
By leveraging the quarkus-langchain4j-easy-rag extension, developers can quickly enable their applications to retrieve and utilize relevant information from documents, enhancing the capabilities of AI-driven features such as chatbots, question-answering systems, or intelligent search functionalities. The extension’s seamless integration with Quarkus ensures a smooth development experience, aligning with Quarkus’s philosophy of making advanced technologies accessible and easy to use in cloud-native environments.
Step 4: Test Your Application Using Quarkus Dev Mode
Before testing the AI application, you need to set your OPEN_API_KEY in the application.properties file:
quarkus.langchain4j.openai.api-key=YOUR_OPENAI_API_KEY
Start the Quarkus dev mode to test the AI application using the following Maven command:
./mvnw quarkus:dev
The output should look like this:
Listening for transport dt_socket at address: 55962
__ ____ __ _____ ___ __ ____ ______
--/ __ \/ / / / _ | / _ \/ //_/ / / / __/
-/ /_/ / /_/ / __ |/ , _/ ,< / /_/ /\ \
--\___\_\____/_/ |_/_/|_/_/|_|\____/___/
INFO [io.qua.lan.eas.run.EasyRagRecorder] (Quarkus Main Thread) Reading embeddings from /Users/danieloh/Downloads/quarkus-rag-demo/easy-rag-embeddings.json
INFO [io.quarkus] (Quarkus Main Thread) quarkus-rag-demo 1.0.0-SNAPSHOT on JVM (powered by Quarkus 3.18.4) started in 2.338s. Listening on: http://localhost:8080
INFO [io.quarkus] (Quarkus Main Thread) Profile dev activated. Live Coding activated.
INFO [io.quarkus] (Quarkus Main Thread) Installed features: [awt, cdi, langchain4j, langchain4j-easy-rag, langchain4j-openai, langchain4j-websockets-next, poi, qute, rest-client, rest-client-jackson, smallrye-context-propagation, smallrye-openapi, swagger-ui, vertx, websockets-next]
--
Tests paused
Press [e] to edit command line args (currently ''), [r] to resume testing, [o] Toggle test output, [:] for the terminal, [h] for more options>To access the Quarkus Dev UI, press “D” on the terminal where the Quarkus dev mode is running or access http://localhost:8080/q/dev-ui/ directly on a web browser.
Select “Chat” to access the experimental prompt page. This is beneficial for developers to verify a new AI service quickly without implementing REST APIs or front-end applications.
Input (prompt) the following text to verify the RAG functionality:
- Tell me about the benefits of a "Standard savings account."
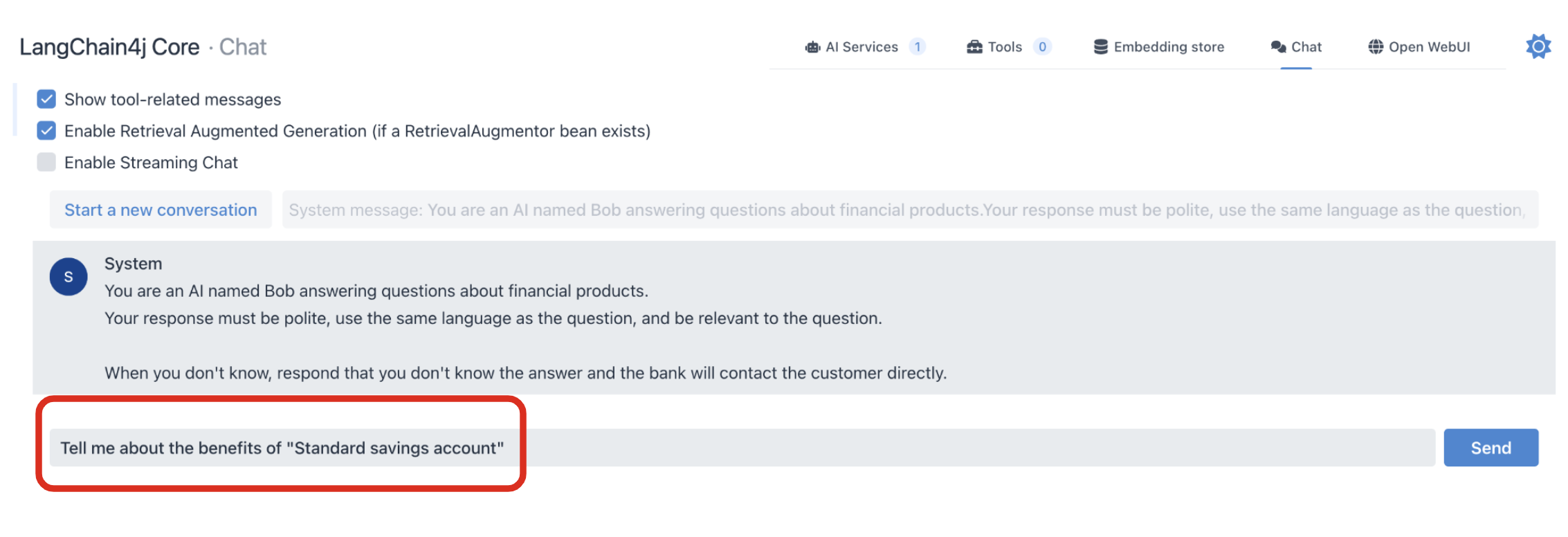
Send the prompt to the Open AI. The AI model should be the GPT-4o mini by default.
The prompt will be improved by ingesting the document (e.g., standard-saving-account.txt) before the user input message is sent to the LLM.
A few seconds after your request is processed, the response will be sent back to you with the following answer:

Enhancements for Real-World Use
- Use a vector database. Replace the in-memory list with Qdrant or Pinecone for scalable document retrieval.
- Add AI models. Integrate Hugging Face transformers for advanced text generation.
- Error handling. Improve robustness with retry logic and input validation.
Conclusion
You’ve built a basic RAG application with Java and Quarkus! This example lays the groundwork for smarter apps that combine retrieval and generation. Experiment with larger datasets or AI models to level up!
Opinions expressed by DZone contributors are their own.
Comments