Scrape Amazon Product Reviews With Python
Let's learn how we can implement Python and Python scripts to scrape the Amazon website in an ethical way to extract product review data.
Join the DZone community and get the full member experience.
Join For FreeAmazon is a well-known e-commerce platform with a large amount of data available in various formats on the web. This data can be invaluable for gaining business insights, particularly by analyzing product reviews to understand the quality of products provided by different vendors.
In this guide, we will look into web scraping steps to extract Amazon reviews of a particular product and save them in Excel or CSV format. Since manually copying information online can be tedious, we’ll focus on scraping reviews from Amazon. This hands-on experience will enhance our practical understanding of web scraping techniques.
Prerequisite
Before we start, make sure you have Python installed in your system. You can do that from this link. The process is very simple — just install it like you would install any other application.
Now that everything is set, let’s proceed.
How to Scrape Amazon Reviews Using Python
Install Anaconda through this link. Be sure to follow the default settings during installation. For more guidance, you can watch this video:
We can use various IDEs, but to keep it beginner-friendly, let’s start with Jupyter Notebook in Anaconda. You can watch the video linked above to understand and get familiar with the software.
Steps for Web Scraping Amazon Reviews
Create a New Notebook and save it.
Step 1: Import Necessary Modules
Let’s start importing all the modules needed using the following code:
import requests
from bs4 import BeautifulSoup
import pandas as pdStep 2: Define Headers
To avoid getting your IP blocked, define custom headers. Note that you can replace the User-agent value with your user agent, which you can find by searching "my user agent" on Google.
custom_headers = {
"Accept-language": "en-GB,en;q=0.9",
"User-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.1
Safari/605.1.15",
}Step 3: Fetch Webpage
Create a Python function to fetch the webpage, check for errors, and return a BeautifulSoup object for further processing.
# Function to fetch the webpage and return a BeautifulSoup object
def fetch_webpage(url):
response = requests.get(url, headers=headers)
if response.status_code != 200:
print("Error in fetching webpage")
exit(-1)
page_soup = BeautifulSoup(response.text, "lxml")
return page_soupStep 4: Extract Reviews
Inspect Element to find the element and attribute from which we want to extract data. Let's create another function to select the div and attribute and set it to extract_reviews variable. It identifies review-related elements on a webpage but doesn’t yet extract the actual review content. You would need to add code to extract the relevant information from these elements (e.g., review text, ratings, etc.).
# Function to extract reviews from the webpage
def extract_reviews(page_soup):
review_blocks = page_soup.select('div[data-hook="review"]')
reviews_list = []Step 5: Process Review Data
The code below processes each review element, extracts the customer’s name (if available), and stores it in the customer variable. If no customer information is found, customer remains none.
for review in review_blocks:
author_element = review.select_one('span.a-profile-name')
customer = author_element.text if author_element else None
rating_element = review.select_one('i.review-rating')
customer_rating = rating_element.text.replace("out of 5 stars", "") if rating_element else None
title_element = review.select_one('a[data-hook="review-title"]')
review_title = title_element.text.split('stars\n', 1)[-1].strip() if title_element else None
content_element = review.select_one('span[data-hook="review-body"]')
review_content = content_element.text.strip() if content_element else None
date_element = review.select_one('span[data-hook="review-date"]')
review_date = date_element.text.replace("Reviewed in the United States on ", "").strip() if date_element else None
image_element = review.select_one('img.review-image-tile')
image_url = image_element.attrs["src"] if image_element else NoneStep 6: Process Scraped Reviews
The purpose of this function is to process scraped reviews. It takes various parameters related to a review (such as customer, customer_rating, review_title, review_content, review_date, and image URL), and the function returns the list of processed reviews.
review_data = {
"customer": customer,
"customer_rating": customer_rating,
"review_title": review_title,
"review_content": review_content,
"review_date": review_date,
"image_url": image_url
}
reviews_list.append(review_data)
return reviews_listStep 7: Initialize Review URL
Now, let's initialize a search_url variable with an Amazon product review page URL.
def main():
review_page_url = "https://www.amazon.com/BERIBES-Cancelling-Transparent-Soft-Earpads-Charging-Black/product-
reviews/B0CDC4X65Q/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews"
page_soup = fetch_webpage(review_page_url)
scraped_reviews = extract_reviews(page_soup)Step 8: Verify Scraped Data
Now, let’s print (“Scraped Data:”, data) scraped review data (stored in the data variable) to the console for verification purposes.
# Print the scraped data to verify
print("Scraped Data:", scraped_reviews)Step 9: Create a DataFrame
Next, create a DataFrame from the data, which will help organize data into tabular form.
# create a DataFrame and export it to a CSV file
reviews_df = pd.DataFrame(data=scraped_reviews)Step 10: Export DataFrame to CSV
Now, export the DataFrame to a CSV file in the current working directory.
reviews_df.to_csv("reviews.csv", index=False)
print("CSV file has been created.")Step 11: Ensure Standalone Execution
The code construct below acts as a protective measure. It ensures that certain code runs only when the script is directly executed as a standalone program rather than being imported as a module by another script.
# Ensuring the script runs only when executed directly
if __name__ == '__main__':
main()Result
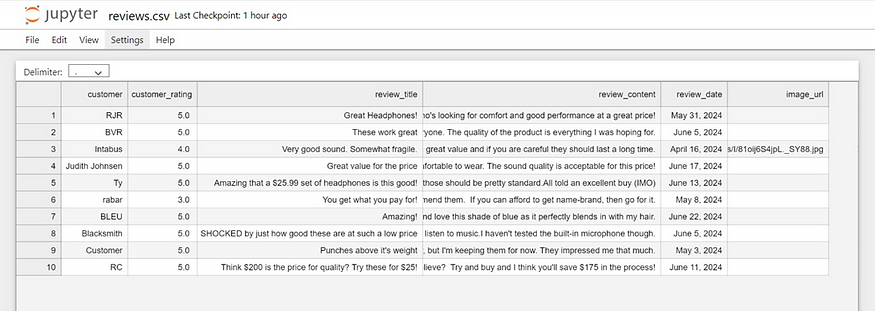
Why Scrape Amazon Product Reviews?
Scraping Amazon product reviews can provide valuable insights for businesses. Here’s why they do it:
Feedback Collection
Every business needs feedback to understand customer requirements and implement changes to improve product quality. Scraping reviews allows businesses to gather large volumes of customer feedback quickly and efficiently.
Sentiment Analysis
Analyzing the sentiments expressed in reviews can help identify positive and negative aspects of products, leading to informed business decisions.
Competitor Analysis
Scraping allows businesses to monitor competitors’ pricing and product features, helping them stay competitive in the market.
Business Expansion Opportunities
By understanding customer needs and preferences, businesses can identify opportunities for expanding their product lines or entering new markets.
Manually copying and pasting content is time-consuming and error-prone. This is where web scraping comes in. Using Python to scrape Amazon reviews can automate the process, reduce manual errors, and provide accurate data.
Benefits of Scraping Amazon Reviews
- Efficiency: Automate data extraction to save time and resources.
- Accuracy: Reduce human errors with automated scripts.
- Large data volume: Collect extensive data for comprehensive analysis.
- Informed decision-making: Use customer feedback to make data-driven business decisions.
Conclusion
Now that we’ve covered how to scrape Amazon reviews using Python, you can apply the same techniques to other websites by inspecting their elements. Here are some key points to remember:
Understanding HTML
Familiarize yourself with the HTML structure. Knowing how elements are nested and how to navigate the Document Object Model (DOM) is crucial for finding the data you want to scrape.
CSS Selectors
Learn how to use CSS selectors to accurately target and extract specific elements from a webpage.
Python Basics
Understand Python programming, especially how to use libraries like requests for making HTTP requests and BeautifulSoup for parsing HTML content.
Inspecting Elements
Practice using browser developer tools (right-click on a webpage and select “Inspect” or press Ctrl+Shift+I) to examine the HTML structure. This helps you find the tags and attributes that hold the data you want to scrape.
Error Handling
Add error handling to your code to deal with possible issues, like network errors or changes in the webpage structure.
Legal and Ethical Considerations
Always check a website’s robots.txt file and terms of service to ensure compliance with legal and ethical rules of web scraping. By mastering these areas, you’ll be able to confidently scrape data from various websites, allowing you to gather valuable insights and perform detailed analyses.
Published at DZone with permission of Juveria dalvi. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments