Scaling Redis Without Clustering
Explore techniques for scaling Redis without clustering. Discover effective client-side sharding and consistent hashing strategies.
Join the DZone community and get the full member experience.
Join For FreeRedis is a popular in-memory data store known for its speed and flexibility. It operates efficiently when a particular workload's memory and computational demands can be managed within a single node. However, scaling beyond a single node often leads to the consideration of the Redis Cluster. There's a common assumption that transitioning to the Redis Cluster is straightforward and existing applications will behave the same, but that's not the case in reality. While Redis Cluster addresses certain scaling issues, it also brings significant complexities. This post will discuss the limitations of scaling with Redis Cluster, and introduce some simpler alternatives that may meet many organizations' needs.
What Is the Redis Cluster?
Redis Cluster is a distributed implementation that allows you to share your data across multiple primary Redis instances automatically and thus scale horizontally. In a Redis Cluster setup, the keyspace is split into 16384 hash slots (read more here), effectively setting an upper limit for the cluster size of 16384 master instances. However, in practice, the suggested maximum size is on the order of ~1000 master instances. Each master instance within the cluster manages a specific subset of these 16,384 hash slots. To ensure high availability, each primary instance can be paired with one or more replica instances. This approach, involving data sharding across multiple instances for scalability and replication for redundancy, is a common pattern in many distributed data storage systems. A cluster having three primary Redis instances, with each primary instance having one replica, is shown below:
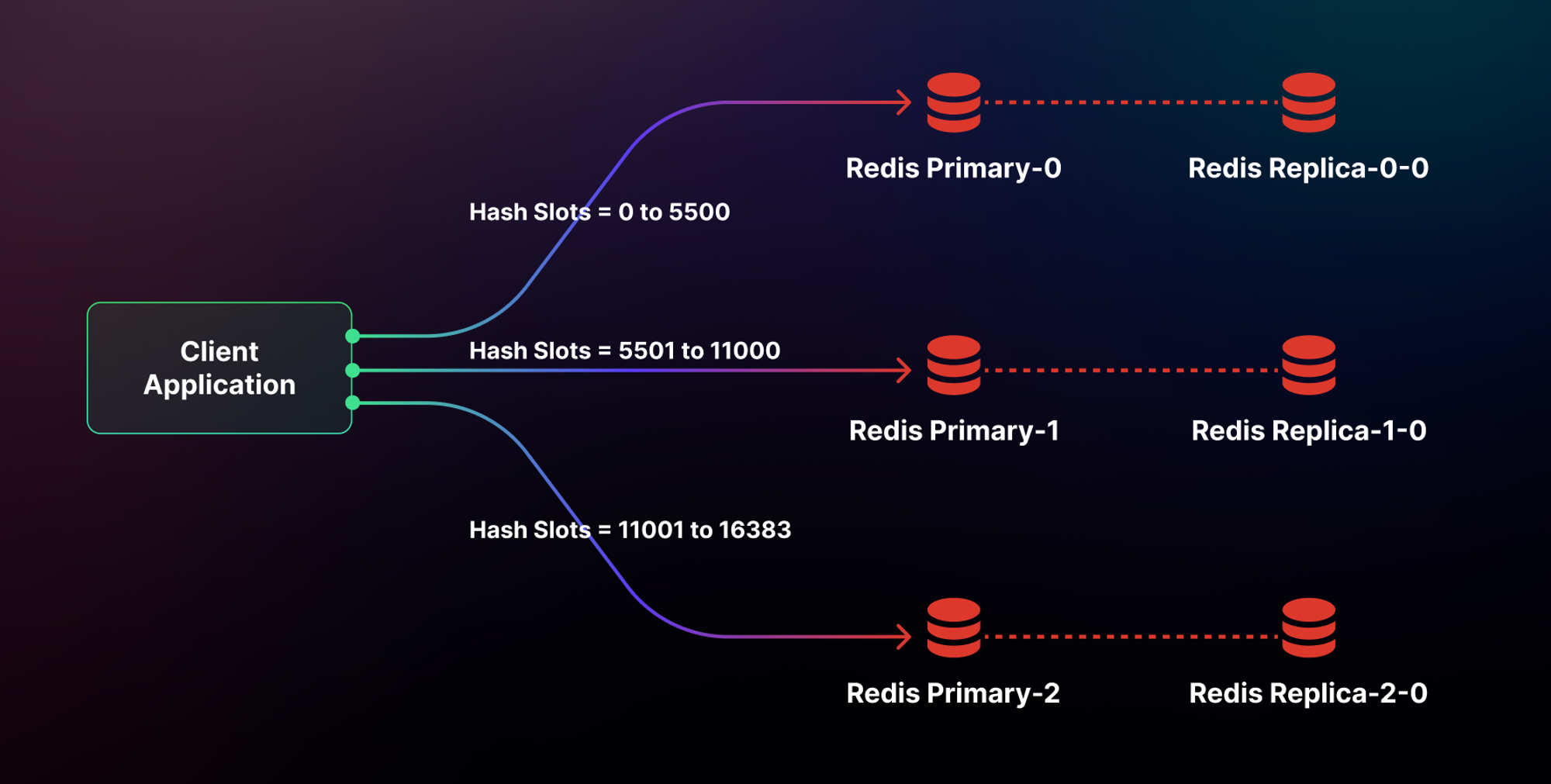
As you can see, Redis Cluster has an elegant design. But without diving too deeply into the implementation details, we have already introduced multiple concepts (sharding, hash slots, etc.), just to have a basic understanding. We will explore more challenges below.
The Challenges of Horizontal Scaling
While Redis Cluster is often thought of as merely a setting on standalone Redis it differs in many ways. This means that migrating to the Redis Cluster is filled with hidden challenges that can surprise even experienced developers.
Client Library Requirements
From the perspective of client libraries, working with Redis Cluster involves adapting to a different interface. That means you will very likely need to use a cluster-specific client library - your existing client for standalone Redis will not work out-of-box with a cluster. Let's take the go-redis Redis is an example. When connecting to a standalone Redis, the following code snippet can be used to connect to an instance with a specified host, password, and logical database:
import "github.com/redis/go-redis/v9"
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "", // no password set
DB: 0, // use default logical database 0 (more on this later)
})The same package offers a cluster-specific client, but it's important to note that they are distinct structures: redis.Client for standalone Redis and redis.ClusterClient for Redis Cluster. The initialization process for redis.ClusterClient is different as shown below. This distinction is crucial because redis.ClusterClient internally utilizes multiple redis.Client objects to manage communications with all the nodes in a cluster. Each redis.Client in this setup maintains its separate pool of connections.
import "github.com/redis/go-redis/v9"
rdb := redis.NewClusterClient(&redis.ClusterOptions{
Addrs: []string{
"localhost:7001",
"localhost:7002",
"localhost:7003",
"localhost:7004",
"localhost:7005",
},
})A side note that the go-redis package also provides a redis.UniversalClient interface to simplify the initialization process, but it's just a layer of abstraction on top of different types of clients. To work with Redis Cluster, a cluster-specific client as demonstrated above needs to be developed to take care of additional requirements from a cluster.
Multi-Key Operations
Multi-key operations in Redis refer to commands or sets of commands that act on more than one key simultaneously. For instance, the MSET command is a single command that can potentially set multiple keys to multiple values in a single atomic operation. Similarly, transactions or Lua scripts often involve multiple keys, though not always. A key limitation of the Redis Cluster is that it cannot handle multi-key operations unless the involved keys share the same hashtag, as outlined in the specification here. You need to carefully review all the multi-key operations in your application, and these operations need to be modified to avoid using multi-key operations or only use them in the context of the same hashtag.
Logical Databases
In Redis, a logical database is essentially a separate keyspace within the same Redis instance. Redis supports multiple databases, which are identified by a database index, a simple integer. Unless otherwise specified, Redis clients normally use the default database, database 0, upon connecting. Utilizing logical databases can be an effective strategy for separating different types of data (e.g., isolating session data from application data). You can use the SELECT command to switch between different logical databases. However, as specified in the SELECT command documentation, you lose this isolation with Redis Cluster. Therefore, if you're transitioning to Redis Cluster, it necessitates a complete re-architecture of your keyspace schema from scratch.
Complexity in Setup and Maintenance
What we have discussed above was just the application level. However, the implications of clustering extend into infrastructure complexity and operational costs.
First of all, enabling the Redis Cluster substantially increases infrastructure complexity and the operational burden for teams managing it. Instead of monitoring metrics and availability on a single Redis instance, you need to do it across dozens or hundreds of nodes.
Secondly, workloads should be distributed evenly across the cluster while minimizing hotspots in particular instances. In reality, however, this does not happen very frequently. A common misconception is that creating a cluster will automatically lead to uniform traffic across all shards. Yet, specific slots can almost always get more traffic than others. While Redis allows you to reshard the instances, it has no automatic rebalancing features.
Last but not least, with more instances come more potential points of failure. While a cluster provides failover capabilities when nodes go down, the multiplied risk is real. Let's assume any single Redis instance has a 0.01% chance of failure. At 100 instances, that escalates to a 1-2% chance, meaning more incidents, fire drills, and potentially sleepless nights.
Redis Cluster Alternatives
Given the challenges of Redis Cluster, it's worth considering alternatives that can provide a simpler path to scaling Redis.
Application-Level Optimization
Tune application access patterns to Redis can significantly minimize the working data size. With small tweaks to keys, data structures, and queries, you may squeeze a lot more out of your existing Redis deployment. For example, at Abnormal Security, they shortened their 64-character key strings to 32 characters. This reduced the per-key memory footprint, allowing them to fit 15% more key-value pairs. However, application-level optimization is not always feasible. After delving deep into the optimization process, it can sometimes feel like you're serving the needs of the data store rather than leveraging it to support your business goals.
Memory Bounded Workloads
If throughput is not an issue, and you just need more memory, the simplest solution is upgrading to a higher memory instance. Of course, this means that the extra CPUs that come with this beefier instance will sit idle and will not join the party. Sometimes it's annoying to pay for them but at least you are not contributing to global warming.
However, since Redis is single-threaded, if your workload is CPU-bound – for instance, involving extensive parsing and modification of JSON data – simply adding more CPUs will probably not help.
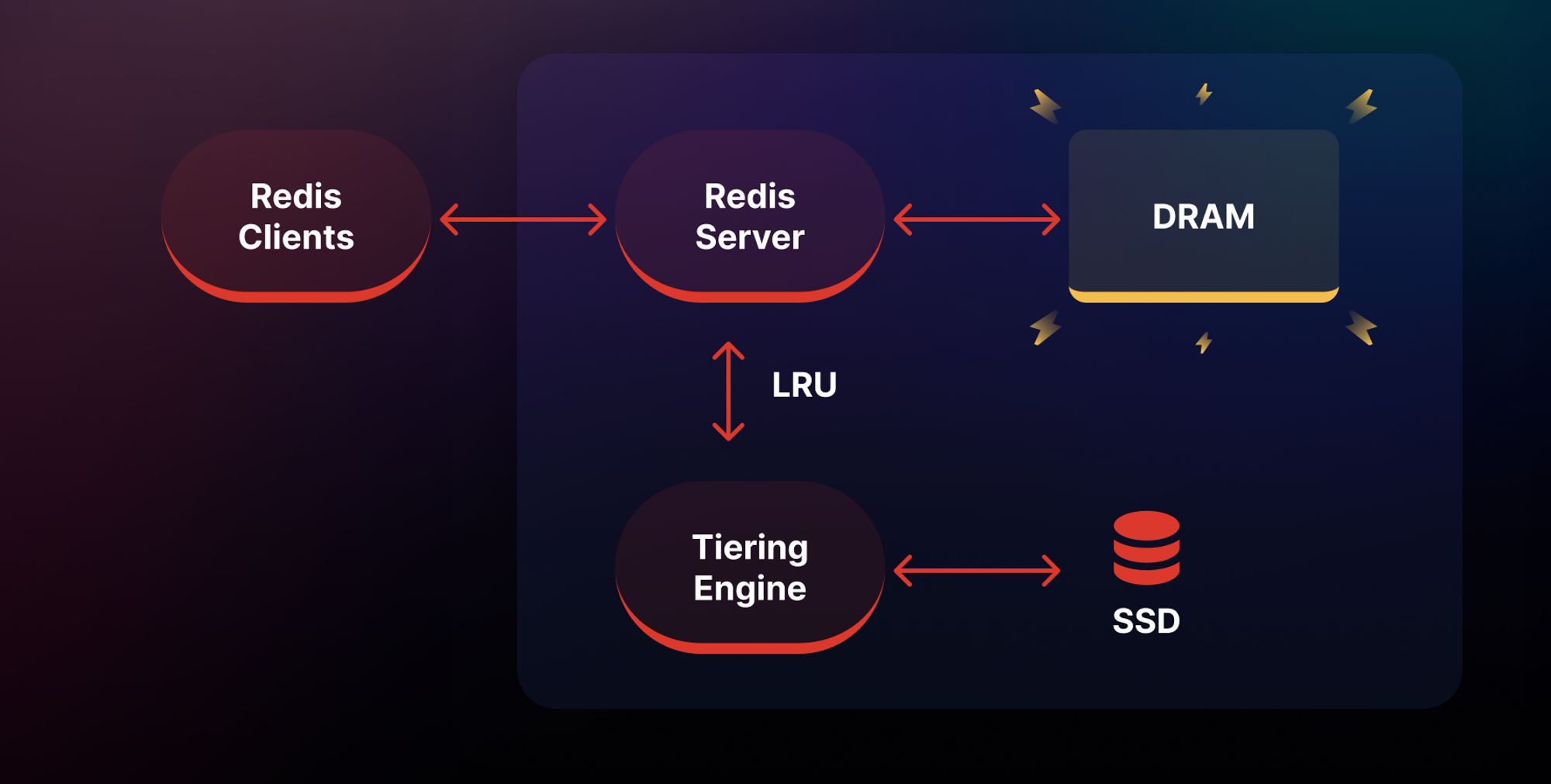
Data Tiering to SSD/Flash
Redis on Flash, also known as data tiering, is not available in the Redis open-source version and is a relatively new feature with Redis-managed solutions. Data tiering allows parts of a Redis dataset that are not frequently accessed to be moved to an SSD storage tier attached to the instance. This provides significantly more memory capacity (up to 2TB of combined in-memory and SSD storage on certain cloud platforms) for the working dataset while keeping the hot dataset in low-latency main memory.
Since Redis on Flash keeps all keys in memory and only stores the values to disk as needed, Redis on Flash is only a good choice if your key size is substantially smaller than your value size on average. As an example, if 100-byte keys are storing 120-byte values, there is minimal memory savings to be gained from using flash storage.
Moreover, the common principle of accessing 20% of your dataset 80% of the time applies to the total data volume, including both keys and values. Thus, Redis on Flash doesn't help if you are retrieving only 20% of the keys, but those keys correspond to 80% of the values.
Besides the techniques mentioned above, another alternative is adopting a more modern Redis implementation. Dragonfly is a simple, performant, and cost-efficient in-memory data store, offering full compatibility with Redis APIs. Dragonfly allows you to continue scaling vertically at up to 128 cores and 1TB of memory. A single Dragonfly node can deliver a similar scale to that of a Redis Cluster but without the added operational complexity and limitations on Redis features discussed above.
Dragonfly's Scaling Abilities
Dragonfly is a drop-in Redis replacement that can meet scaling needs without requiring clustering. By utilizing a multi-threaded shared-nothing architecture on a single node, Dragonfly can handle large memory workloads and traffic spikes that would otherwise require clustering.
Some of Dragonfly's key benefits over a cluster setup include:
- No client library or application code changes required
- Simple operational management with no sharding complexity
- Cost savings from needing fewer instances
- Avoid performance hotspots with flexible scaling
- Migrate easily from any Redis deployment
When migrating an application from Redis to Dragonfly, it's important to recognize that some tuning may be required to fully realize Dragonfly's advantages. Applications built for single-threaded Redis are often optimized for minimal parallelism. Dragonfly, by contrast, is multi-threaded. It can be worthwhile to spend time tweaking your client code or configuration to increase the number of connections to Dragonfly and spread data out across more keys.
Conclusion
While the need for horizontal scaling is inevitable past a certain scale - usually 700GB or 1TB of memory - many organizations scale horizontally prematurely before exhausting vertical scaling options. This results in needless operational complexity for workloads that could have fit on a single, sufficiently powered node.
For many use cases, capacity limits are theoretical rather than practical: even if your business grows, sometimes the specific use case for which you keep data in Redis is more limited.
And even if you have to eventually scale horizontally, you'll still want to use relatively powerful instances with 16 or 32 cores rather than spreading the work over hundreds of tiny instances. In that case, each instance becomes a potential weak link: if traffic changes, or there is a sudden surge in throughput or load, the tiny instances won't be able to cope.
While Redis Cluster provides horizontal scaling, it comes at a high cost in terms of complexity and loss of functionality. Dragonfly can support millions of operations per second and terabyte-sized workloads on a single instance, circumventing many of the pitfalls of clustering solutions.
Published at DZone with permission of Oded Poncz. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments